从 0 到 1 构建数据生态系列之三:拆解架构图

接上一篇《从0到1构建数据生态系列之二:拓荒》,这篇我们来好好拆解一下我们的蓝图。
1 写在之前
之前有朋友在后台留言说,从第二章中,可以看出文章略显匆忙,并没有把拓荒的一些过程细节给描绘出来。
这里检讨一下,我坦白、我认罪。
当时那个话题一写开来的时候,突然就发现这是一个巨大的话题,随便发散下去又一大篇了,所以我还是在这一张穿插着把上一张的部分内容补充完整。
当然,至今为止,我已经把未来三章的内容规划出来了,这样更容易把控这个系列的质量。
所以,请期待,请不要放弃治疗。
回归话题,这一部分我将结合架构图中的东西,讲述我们是如何拆解完整的数据规划到执行的过程, 并且期间一些思考方式也会一起分享出来(感觉这更是重点) 。
2 结合业务需求拆解架构图
这里,我们把之前一章已经上过的架构图再贴一次:
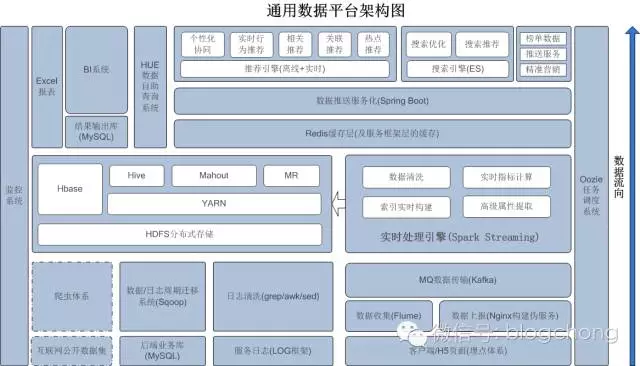
先简单的从整体上说一下这个架构图。
从架构图中,我们可以看出来,我们整个数据架构中,需要做的事情很多。
随着数据的流向,从下到上,主要分三层:
第一层是数据收集层,负责基础数据的收集工作;
第二层是数据存储以及处理层,负责数据存储,以及对数据进行深度处理,数据的转换,价值的挖掘等;
最上层是应用层,基于下面的数据处理,进行价值转换;当然还有贯穿整个过程的监控以及任务调度相关的工作。
第一层中,主要有四个数据来源:用户行为埋点上报数据、服务日志的数据、后端的业务数据、互联网的公开数据。
第二层中,我们主要的核心框架是hadoop的核心生态,基于HDFS的存储(本质上hive的存储也是基于HDFS),以及基于spark的部分实时处理的需求场景,主要是平台级的架构。
当然,至于说具体的处理以及数据的加工、挖掘详细数据业务,后续其他章节再详述。
第三层中,我们直接面向的是业务方。
一方面是数据生态中最基础最常见的的数据智能商业化分析,我们以EXCEL封装成邮件日报周报的形式提供另一方面是平台化的BI系统,以及高度自助性的数据自助查询系统。
在深度挖掘方面,推荐是一个大方向,基于数据的当代搜索也是数据生态的重要组成部分,以及业务画像、用户画像(绝对核心价值所在)等。
当然,除了以上这些,还有一些基于数据的推送服务啊、榜单数据啊、精准营销系统啊,都是数据进一步有效应用,以及数据化价值的直接体现。
收回话题,在时间有限,人力有限,并且基础是0的前提下,事情解决的顺序就显得尤为重要了。
当前的业务需求。
想要使用数据,前提是有数据。所以,我们第一个需要解决的问题是数据源,但是核心的驱动价值因素是我们的业务需求。
我们第一个业务需求就是从数据上洞察产品的运营效果,电商的各种数据运营需求,指导内容数据化运营、电商数据化运营以及通过数据改进产品。
跟业务强相关的基础数据是产品的业务数据库,这个是现成的,只要打通数据流通即可。
与用户行为强相关的则是最直接的用户行为埋点上报数据,以及用户使用服务,在应用服务中留下的访问LOG。
基于服务日志LOG解析数据,一方面如果需要从服务LOG中清洗出有用数据,前提是服务中已经有意识的进行相关信息的LOG落地,这一点,很遗憾,当时并没有这个前瞻性。
其次,从服务LOG中清洗数据的代价略高,且信息量有限。
所以,在这个阶段中,我们并没有打算直接从服务LOG中清洗数据,因为在服务LOG中埋入数据收集点位,也是一个巨大的改造工程,但效果并不一定好。
我们将最快限度的打通业务数据库与数据中心的通道,然后以最快速度的对业务方提供可参考性的数据化日报。
打通行为数据到数据应用的链路,结合用户行为数据,进一步优化数据化运营体系,以及为产品优化迭代提供数据支撑。
构造最基础的数据中心平台,打通数据收集到数据分析应用的链路,为业务方、决策层提供数据化运营决策方案,为产品迭代提供最真实的数据反馈支撑。
这就是我们数据部门第一个战略目标,什么深度挖掘,什么推荐系统,这些在这个时候统统都不要想太多啦,饭需要一口一口的吃!
我们之所以需要拆分阶段目标,依然是投入与产出比的问题!
当我们有一个大目标时,我们需要把目标进行拆分,进一步拆分为阶段可实施、成果可见的阶段性目标,在这里同样适用。
并且,记住,你的老板是不懂技术的,他才不会管你的平台又建设到什么什么程度,集群又搭建了多少台,他只会问,这都一两个月了,你们数据怎么还没有给公司带来价值啊?!(哈哈,有点黑BOSS的感觉了)
不过这肯定是现实,不同位置上的人关注的核心重点不一样。可能你需要关注整体的进度,而业务层只关心你的产出给他带来什么帮助。
是的,拆解大目标有利于我们快速入手启动项目;成果阶段化,更具有鼓励性,成就感;最后就是阶段性目标的实现情况更容易量化你的效率。
从人力的需求评估角度上说,也是有道理的,只有随着你的体系一步一步完善,你才知道哪个环节真正的缺人,缺什么人,这点很关键。
不过最本质的问题,还是投入与产出比。
我们在做人一件事情的时候,都需要注意投入与产出的比例,在一定的时间段内、投入一定的精力、产出一定比例的成果。
有这种价值观,处理事务才更有效率!
3 如何做机器需求的评估
要打通数据收集到数据分析业务的输出链路,那么,你需要一个数据平台进行支撑。甚至,后续你将持续开挖的数据核心价值,也是基于平台上做的。
所以,我们需要一个数据平台,而说到平台,则机器资源是绕不过去的一个问题。
那么,如何去评估你的集群需要多少台机器呢?每个机器又是以一个什么样的角色而存在呢?
在评估之前,你首先清楚的了解到,你平台上需要承载的业务,包括内部的处理业务以及对外暴露的数据业务。
其次,你需要考虑后续一个可扩展性,即后续数据量上涨的情况下,机器的横向扩展当然是没有问题的,但是部分角色机器的资源需求是在纵向。
举个简单例子,Hadoop的datanode可以在横向上进行扩展,但是namenode的资源需求则无法做到。
至于说如何进行机器资源评估,在了解自身业务需求的前提下,这里所说的业务需求,不单纯是业务范围,也意味着业务范围承载的数据量是什么情况。
在了解自身数据量的情况下,多查找其他公司的案例,与其他同行多交流沟通,借鉴其他公司的数据量与集群规模,来评估自身所需要的机器资源。
不过需要注意一点的是,对于电商行业,经常会出现节日性、活动性质的流量暴涨。
所以,你的机器资源一定是需要考虑这些实际场景负载的,或者对于这种场景,你有其他的方案进行处理也OK。
4 使用Nginx做数据上报伪服务
上面说到第二个重点,那就是用户行为数据的上报。
了解数据上报以及埋点相关逻辑的朋友应该清楚,其实所谓的SDK,其本质也是一个接受数据上报的服务。
直接往上报服务中丢数据,跟封装成工具SDK,本质的意义是一样的,我们需要提供一个对外的数据上报服务。
上报什么数据,数据以什么格式上报,这个在下一章的“数据上报体系”部分详细阐述,这里只是对上报服务这块进行讲解。
那这意味着,我们需要为客户端或者H5的童鞋提供一个统一的上报服务接口,让他们在用户特定行为操作的时候。
比如浏览了某个页面,操作了某个按钮等之类的操作,进行这种信息的收集统一上报。
说白了,封装用户的行为数据,在适当时候调我们的接口,把用户的行为数据给我传过来。
那这看似就是一个后台服务,用于处理上报过来的数据。
但是请注意,不管你是一个服务也好,伪服务也好,一般情况下绝不会直接把获取到的数据直接落地的,这是传统的思维路子。
要知道上报的业务流量是很大的,特别是你的点位足够丰满的情况下,在流量高峰期,你要是敢直接进行数据落地,它就敢直接把你的服务给搞死。
一般情况下,我们都会把数据丢给缓存,以解耦上报与落地两端的压力。
既然如此,在有限的人力资源下,在项目时间有限的前提下,为何要花这么大的精力去维护一个服务呢?于是,有了伪服务设想。
我们直接使用Nginx对外伪装成一个Web服务,提供Restful API,但我们不对上报的内容做任何处理,直接落地成Nginx的日志,再通过Flume对日志进行监控,丢到Kafka中。
这样我们就迅速的搭建起一个上报“服务”,提供给客户端童鞋以及H5的童鞋,制定好数据上报的规范,然后就可以坐等数据过来了。
关于数据的 合理性校验、规范性校验、有效性校验、以及进一步的解析 ,我们都放到Spark Streaming这一层去做。
其实当时也是调研过lua的,在Nginx这一层也是可以做到数据完整性以及有效性校验的,但是为了不至于给Nginx端带来过大的负荷,我们把复杂的逻辑处理放到后端。
基于这种伪服务的设计,还有一个好处就是,即使后端链路出现故障,但我的原始数据是落到LOG中的,了不起我进行数据的回溯,再通过LOG清洗出异常的部分就行了。
这也是我们后续实时数据容错的核心依据所在,所以,重点推荐。
5 使用Spark Streaming做实时数据清洗
接上面的上报,我们在后端一层是使用Spark Streaming做数据校验、进一步清洗的。
如果业务对于实时性要求不高,我们完全是不必要做数据的实时链路的,只需要周期性的把Nginx中的上报日志进行批量清洗入库即可。
但是,一方面基于部分对实时性稍高(其实也不高,分钟级别),例如电商活动期间对数据的实时监控;另一方面来说,实时性的数据上报链路是最终的目标,为了业务的时效性,迟早是需要做的。
由于我们需要在后端的处理环节中,对数据的有效性、规范性做校验,并且做进一步的属性解析,例如通过IP解析地理位置之类的,所以承载的业务逻辑还是蛮复杂的。
所以,我们打算引入一个实时处理框架来做这件事。
关于实时框架这块,我想,熟悉的朋友都会想到两个:Storm与Spark Streaming。
简单的说一下两者的对比。
很久以前翻译过一篇文章《翻译:Storm与Spark Streaming的对比》,这里只是简单的说一说。
Storm与Spark Streaming最本质的区分在于,Storm是真正实时处理,而Spark Streaming的处理本质则是微批处理。
所以Storm能够将实时业务达到毫秒级,而Spark Streaming虽然也能达到亚秒级,但对于效率的影响会比较大,所以一般会用于秒级的数据处理。
目前就我们自身的业务需求来说,对于实时性并没有高到毫秒级的要求。
并且,为了维护系统平台的统一性(统一的平台架构,统一的YARN资源管理,同一个垂直生态),我们选择使用Spark Streaming作为我们数据清洗的入口。
使用Spark Streaming需要解决的一个问题就是,输出结果的高度碎片化。
正如上面所说,Spark Streaming其核心依然是Spark的路子,在微小的时间窗内,对微小批量的数据进行处理,达到类似实时的效果。
而其每一个批量处理之后都是以批量结果得以输出,于是,就会产生大量的碎片文件。
其实,解决这个问题也简单,那就是合并!进行周期性的文件合并,这点就不多说了。
既然说到了Spark Streaming,也就顺带着说一说Spark这个生态。
在很早以前,Hadoop、MapReduce经常会被人提到,但是随着Spark的兴起,已经越来越少人愿意使用MapReduce去批量处理数据了。
是的,Spark目前在Hadoop大生态中,已经形成一个比较完整的子生态:
包括与数据查询分析关联的Spark SQL;
实时处理领域的Spark Streaming;
正常内存处理可以替代MapReduce的离线批量;
还有集成大量机器学习包的MLlib;
以及还有什么图形处理的什么鬼(好吧,那个不是我擅长的)。
在效率至上的数据时代,MapReduce说抛弃就被抛弃了(哈哈,其实也没有这么严重,只是越来越多人弃用MapReduce,这肯定是事实)。
在体系支撑上,Spark依然成气候,数据的常规SQL分析,数据的内存处理、实时处理,以及数据的深度挖掘等,全部一起打包,好用的不得了,所以越来越得人心,也是木有办法的事。
关于IP地理位置解析,这里也可以分享一下。
IPIP.NET提供的IP库实在是值得推荐的,没钱的可以使用它提供的免费版,有钱的主可以考虑使用使用付费版。
其实免费版也没有想象中那么不堪,只是他提供的服务没有这么多,更新的频次少点而已,大部分能解析到市一级,至于省份这一级,那是妥妥的没问题的。
6 结语
这一章主要阐述如何从局部入手,拆解架构图,进行阶段性的任务执行,从这个角度讲,上一章节的标题反倒是更适合这个了。
其中,详细讲解了部分核心重点,包括架构图的拆解、机器资源的评估、Nginx的上报伪服务、以及基于Spark Streaming的数据清洗等。
但是,个人认为,更重要的是期中阐述一些问题的思考方式、价值观等。诸如拆解整体规划的思考、扩展预留的思考、方案选择的对比衡量等。
方法论远比现成的方案有用!我一向的观点是:授人以鱼不如授人以渔。
OK,到这里,本章节打完收工。
相关阅读:
从 0 到 1 构建数据生态系列之一:蛮荒时代
从 0 到 1 构建数据生态系列之二:拓荒
从 0 到 1 构建数据生态系列之三:拆解架构图
从 0 到 1 构建数据生态系列之四:与研发的爱恨情仇
从 0 到 1 构建数据生态系列之五:让你的数据生态变得更高效
从 0 到 1 构建数据生态系列之六:数据价值挖掘
文·blogchong
关键字:数据, 产品经理
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
