资料下载 | QQ 音乐高级产品经理:QQ 音乐如何做个性化推荐?
产品经理 如何思考个性化推荐的?
个性化推荐的原理应该是在特定场景下,去构造一些合理的算法或规则将正确的数据推荐给正确的用户,这句话放在现在很多产品都是一样的,但可能在不同的产品上也有一点区别。比如说在QQ音乐里面所指的数据就是 音乐 和 用户 。
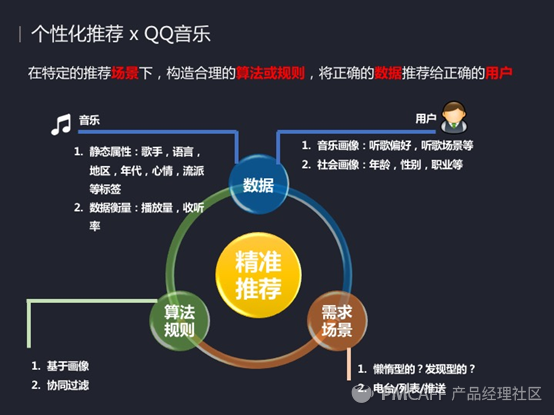
音乐: 说我们在6500万的曲库里面每一首歌曲都有一些它自己的静态属性。比如歌手、语音、发行地区、发行年代、用户为他打上的一些心情、场景等标签、音乐流派标签。同时每首歌也有它的一些动态数据,如播放量、收藏率等等。
用户: QQ音乐除了有自己的用户画像,比如说听歌偏好、听歌场景等等,还拥有一些其他体制下的用户画像,比如用户的年龄、性别等等。这些都会是一些比较好的推荐资源。接下来会详细跟大家说一下这些是怎么用上的。
如何 从需求场景出发给用户分类 ?
1)懒惰/被动浏览
场景: 他可能是漫无目的的,他可能会有一些自己感兴趣的歌手,但他又懒得去找,比如说进入音乐,他就是想要一键播放,其实也没有更好的解决方法,之前就是要进入一个列表滑动一下,然后又没有预期。需求: 那这种需求我们就要提炼出来,首先推荐一些他感兴趣的,另外说他不需要太费力地浏览,能够做到一键播放,这个地方也就是他个性化需求的另一方面,也就是去满足他被动听那个心态。
解决: 我们在这里面也做了蛮多的一些尝试,比如说我们做的“猜你喜欢”、“个性电台”等那些,都是解决个性化推荐和一键播放,根据用户的行为进行调整。
2)主动浏览
场景: 对于这种用户就是他有自己的一个找到某些歌曲的需求,但因为他的时间比较短,但有时候需要通过一些分类他肯定需要进入很多层级,那找一次就挺麻烦了,所以需要一种能够节省时间的方法。需求: 这种用户是属于那种浏览型用户,他有自己感兴趣的,也希望能够主动去发现,但是就是在筛选的方式上比较麻烦,要通过筛选几次之后才能找到他自己想要的内容。
解决: 那我们可以在他浏览的场景,比如说在歌单广场,在查找的新歌下面,主动去做一些个性化推荐,比如说新增一个全部,那全部里面可能是根据你的听过习惯做的推荐,省去你查找的麻烦。另外一块,或者是我们把他经常做一些筛选的行为记录下来,也让他后面重新做筛选的时候省去一些麻烦。
3)追“新”
场景: 关注某一个歌手,希望了解他的新歌动态。
需求: 有自己关注的内容,希望被及时告知。
解决: 那我们可以通过他的听歌行为知道他关注什么歌手的哪些歌曲,那单击歌手或者歌曲更新的时候我们可以马上通过push的方法来告诉用户,这种是一个搞清用户最快的一个方法,满足他一个个性化的需求。
4)对于需求跟场景的总结。
用户在使用这个场景的时候是什么? 他是一个需要主动去浏览的场景还是说是一个被动场景,这场景没有解决的时候他的痛点是什么?
我们希望他的解决方法是自然和简单的。 不需要用户去做太多操作,太多操作对于用户来说是一种负担。
对个性化推荐来说是不是有更加刚需的主场景? 举例,我们提供了很久在线发现跟本地推荐,在线推荐的意思是说有发现欲望的用户在音乐馆里面可以逛到一些好听的音乐,但其实,在很多音乐软件里面,用户的大部分时间都不是停留在在线发现。那我们应思考一下用户的主场景,比如说他的本地音乐跟下载音乐是不是有更多可以做个性化推荐的可能。这些实际上都应该是产品经理应该思考的,而不是拘泥在一些算法或者其他方法。
个性化推荐的算法/规则是什么?
我们可能认为个性化推荐需要接触的算法东西很多,比如几个推荐系统、几个表情推荐、画像推荐甚至是更深奥的回归,但归纳到底一些比较复杂的算法可能会用到局部调整。
1、基于用户画像的推荐。
画像在我们QQ推荐里面有两个定义,第一个是基于用户的社会属性定出来的,比如说我几岁、我的职业、我的星座等这些属性。社会属性在QQ音乐有几个特征是非常明显的,比如说不同年龄段的人挺的歌是不太一样的,或者说不同职业的人听的歌不一样。
而QQ音乐的用户画像是指,通过用户在QQ音乐里面听到、收藏的歌归纳出来用户可能喜欢某些歌曲,他可能喜欢某些流派、某个歌手这些,通过数据来归纳出对他的一个描述。不同性别、年龄的用户口味相差蛮大。

通常,当一个用户进入QQ音乐但没有任何数据的时候,我们可以尝试这种方法来推荐给用户,比如说你是一个十几岁的男生,我比较倾向于给你推荐李荣浩这种。
2、协同推荐。
协同推荐的原理非常简单,看一下图里。首先可以看左边这张图,比如在QQ音乐上有100人收藏了陈绮贞这首歌,而张悬的儿歌也有100个人收藏,其中共同收藏这两首歌的总共有50个人,那大家通过一个简单的并运算,然后再用共同人数50除以并集100之后可以得出0.5,也就是喜欢旅行的意义的人有50%的概论就喜欢张悬的儿歌。同样看右边,这两首歌的相似度就只有0.05。通过这个方法我们就可以通过多少人听过这首歌,再求出共同听歌人数,最后通过一个公式来算出一个相似度。
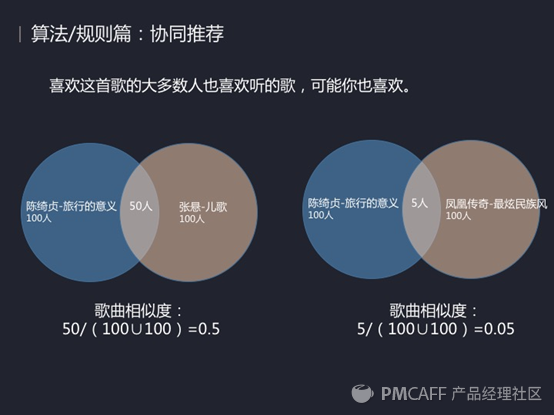
那获得歌曲相似度之后我们该怎么去推荐给用户感兴趣的歌曲呢。
这里面还涉及到怎样去定义用户感兴趣的歌曲,在QQ音乐里面用户行为是则回应定义的,比如说他的一个显性和隐性操作,比如说他对一张专辑收藏和跳过了某些歌曲。
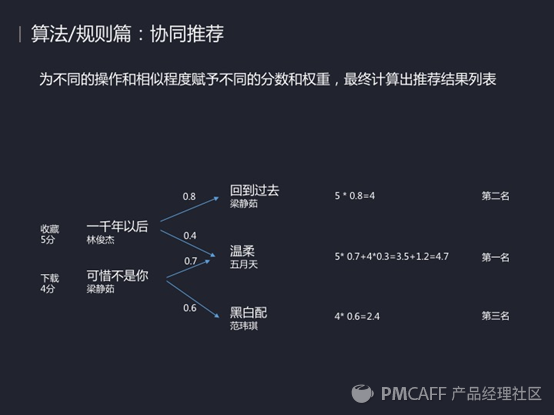
当你有了这些操作行为之后就可以来计算用户喜欢哪些歌曲。如图上的例子(数据有错注意一下,温柔这首歌的分值应该是50.4+40.7=4.8),通过这样一个计算得出温柔这首歌应该是最先推给你的,其次是回到过去和黑白配。
这就是QQ音乐一个非常简单的原理,当然上面可能叠加了很多修正,比如说他很久之前收藏的歌曲就会进行一个降权,因为越早收藏的重要性越低。而一些热门歌曲很多人都收藏的会降权,但你收藏了很多歌曲会加权。通过这个算法对用户进行推荐。
3、基于标签推荐。
这个很好理解,比如说这首歌跟另外一首歌在流派、年代等这些维度都非常相似,刚好也喜欢其中的一首,那我们就认为你可能也喜欢另外一种。
三种推荐策略优劣对比
基于用户画像推荐解释性可能是最强的,但是他依赖于用户不断地去听歌积累数据。关于协同推荐的有点就是只要你听过这首歌曲,他就可以通过后台计算去给你推荐,对于一些冷门歌曲,这样是非常有用的;同时他的缺点也非常明显,就是对于热门歌曲它的可解释性不强。基于标签优点在于他无论冷热门歌曲可取性都非常强,只要你有打上这个标签就能推荐;缺点就在于他需要依靠人工去打标签。
对于QQ音乐来说最重要的是标签和用户画像的数据。对于标签来说大家可以看到他有很多维度,比如歌手、歌曲等很多,而这一块刚刚说了标签这一块,他打标签的人力成本非常高,而我们从长期也发现其实客观标签的覆盖率不是特别全面,主观标签如果完全依赖与信息,它的出错率也是非常高的。对于用户画像来说,它的生成慢和感知差是一个大痛点。
如何利用数据优化推荐系统?
1、 通过机器 提高效率和准确率
举个例子,比如说周杰伦这首三年二班,我们听过的都觉得他是一首rap,但实际上我们自动计算的可能会计算成一首中等速度歌曲。因此这种东西就需要我们不断去编辑和审核了。
我们后面想了一个方法就是在对歌曲的歌词的时候,打上一些关键帧,一旦这首歌有了这种数据之后,我们就非常容易计算这是歌曲的速度。通过这种方法我们可以看到右图那个,这首歌其实除了前面和后面那部分,其他的速度基本都保持比较稳定。这种变向获得节奏标签的方法我们可以提高标签的覆盖率,这样能降低成本,提高效率和准确率。
2、简化初始画像,创建多样化场景
而用户画像我们上面说道他的一个生成难感知度普遍较弱。我们最近也在尝试一个比如说用户新装了QQ音乐,那他可能会有一个扫面本地歌曲的习惯,那么扫描完之后我们就会去分析一下他本地的那些歌曲是什么样的,这样就能够确定一个用户的初始画像。这种方法在很多app上都有用到。同时对于画像感知差的问题,我们会做一个年终盘点,把用户数据呈现在他面前,告诉他这不是一个冷冰冰的数据,这样就让她更有动力去接受我们的推荐。
点击下载完整版分享资料
有任何疑问,请咨询负责人微信:luxxxlu
更多精彩,请关注PMCAFF公众号(搜索“pmcaffcom”添加关注)
文/PMedia
关键字:产品经理, 推荐
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
