听懂用户们在说什么——UGC文本分析怎么做?
如果你的评论区仅有10条用户评论,你可以很轻松地了解他们对这个产品/商品的态度如何以及表达了什么想法。但是,如果是100条,是不是需要稍微花点时间,变得吃力了?
如果是1000条,恐怕需要附上一些数据筛选的方式,一条一条看就不太适合了。即使1000条可以勉强人力处理,但问题是,如果评论的数量扩大到了10000条,别说读懂了,就连翻页都得好长时间,人力就捉襟见肘了。
这时候你需要运用一些文本分析的方法,来帮助你读懂海量的评论文本究竟在表达什么。
一、获取评论数据
最朴实无华的方式当然是Crtl C+Crtl V,将每一条数据手动复制到Excel表格当中。但正如上文所言,人力是有上限的,请让我结合自身经验来分享一下高效点的方法。
1. 如果你想通过编程的方法
在大家都是技术大佬的内网,我不敢班门弄斧,只简单地推荐一下学习路径、科普一下相关概念。
做网络爬虫最易用的语言应该非python莫属,因为上手的门槛很低,在掌握了一系列基本语法,会定义函数后,就可以安装beautiful soup库来开始爬虫之旅。网络上的免费课程非常地多,让人眼花缭乱。
如果你自制力足够,学习能力够强,其实随便一搜,python的基础语法对你来说一定不算难。但如果你学习的时候需要一些交互,趣味对你来说是必要的话,我会推荐你选择风变编程的课程,在线编程,即学即反馈是它的最大优点。学习时间上来看,30小时是足够了的。
2. 如果你想通过无代码的方法
市面上越来越多的不用使用代码就可以实现网络爬取的工具,让本懒人很是快乐。
1)八爪鱼采集器

八爪鱼应该是目前中文互联网曝光度最高的网络抓取工具。
- 优点:具有一定数量现成的采集模版,有专门的问题解决qq群。
- 缺点:自定义采集做得并不是很好用,具有一定的上手门槛。
2)后羿采集器

很低调但是很好用的一款网络爬虫工具。
- 优点:智能采集很智能,识别准确度高,同时自定义流程上手也较为简单。
- 缺点:价格昂贵,免费版的网速实在令人汗颜。
3)集搜客

- 优点:集文本分析的部分功能于一体,可以一站式实现较多需求;
- 缺点:爬虫功能实在不好用,远不如后裔采集器。
如果你的爬取要求不是很复杂的那种,个人推荐使用后羿采集器来爬取,慢就慢点,大不了,开着电脑给它挂一晚上?
二、预处理评论数据
1. 评论内容分词与去词
1)分词是什么,为什么这样做
Why?我爬取下来了咋还要分词,「分词」又是个什么东东?速速听我说来,我们都知道,计算机和人脑的区别在于理性与感性,计算机为了更高效地处理数据,需要做出一些更符合计算机运行逻辑的加工,分词就是其中一种。
举个栗子:我今天驾驶宝马的汽车前往商场了。
经过分词处理后:我/今天/驾驶/宝马/的/汽车/前往/商场/了。
就是这样,经过了分词的文本,将更利于计算机来进行统计分析。
在分词系统的推荐上,我认为NLPIR-ICTCLAS汉语分词系统会比较好使,这是它的官网,有下载地址以及简单的功能介绍。
2)去词呢
与分词同一步调的,是「去词」。去词一般来说是去除停用词(Stopwords),意指可以忽略的词。在文本分析中,一些特定的词语或字不提供信息价值(或提供很少),而为了提高效率,产出更可直接用于解读的分析结果,我们会选择在正式的文本分析前,将它们去除掉。
同样举个栗子,这里经过分词的句子:我/今天/驾驶/宝马/的/汽车/前往/商场/了。
经过去除停用词后,它变成了:我/今天/驾驶/宝马/汽车/前往/商场(一些停用词表中,「我」以及「今天」都在其列,为了方便理解,举的例子并未去除这两个词)。
就是这样,去除停用词的目的在于提高信息密度,提高计算机分析产生结果的效率以及方便人为解读结果。
去词一般不会成为一项专门的流程,而是被混在分词过程中。停用词表是需要额外准备(一般分词的系统中也会自带停用词表),百度一搜,会有很多的停用词表,csdn和github上也可以随意下载,不做赘述。
三、分析评论数据
做完评论文本数据的预处理后,就进入到具体的分析阶段了。文本分析的方法与目的是高度相关的,因此难以全部囊括,就简单聊几个通用的、容易上手的。
注:下文几个分析方法并不存在直接的次序关系。
1. 情感分析
「情感分析」,顾名思义是用来判断文本情感倾向的,一般来说会分为积极、中性与消极情感,也可以根据打分的高低,分一分极端积极/消极的情况。
但是如果想要细化到喜怒哀惧悲嗔爱就难以通过简单的三方工具做到了,需要自己构建词库,暂且不提,菜鸟本人也在修炼ing。
用一些工具/平台来实现情感分析,那么精度只能说差强人意而已,不能做到尽善尽美,简单推荐罢。
- 首先是很古老的一个软件,rost cm6。是由武汉大学在很久之前编写的,据我所知往后的(十)几年里并没有进行任何更新。
- 上文提到的可以用于网络爬取的集搜客也可以进行情感分析,而且据它介绍,自己的情感分析准度要比rost cm6高上不少以期获得用户的青睐。
好用的软件只推荐这两个,因为市面上能直接拿来用的工具实在太少。但是如果加一步调用api的话,其实百度开放平台/讯飞开放平台/腾讯云智以及一些大神们都有很成熟的解决方案,想必精度也会更高。
2. 词频分析
讲道理,词频分析很难称得上什么高大上的分析方法,只是把词语出现的频率直白地展现出来而已。一段文本在经历过去除停用词、分词之后,便都是落单的词语了,数数数出来就行。上文提到的NLPIR分词系统、rost cm6、集搜客都能很轻松地做到。
额外提一嘴,在这个过程中,词频分析的精度取决于分词的精度。如果你发现词频分析的结果不是很让人满意,不妨多试试几套分词系统,然后也可以自定义一下词库,避免特定的词语被分开。
举个栗子:「夏日泳池」「冬日泳池」作为某个酒店专门的两个泳池,我们会更期待他们以组合的形式而非「夏日」「冬日」以及「泳池」的形式出现。
至于如何让词频分析可视化一点,好看一点,自然是做一张大家都熟悉的词云图,这里推荐Wordart
https://wordart.com/create,纯净免费无广告,便民实用。
3. 网络语义共现
「语义网络共现」的目的在于可视化的展现词语与词语之间的关系。而生成一个语义网络共现图的的基础在于建立起词语的共现矩阵。行文至此,感受到不动用编程手段的话,能使用的工具越发寥寥。
关于语义网络共现,仍然需要祭出rost cm6,它有一个很方便的功能,可以一键式生成语义网络。
一键生成的语义网络会有两个问题:
- 一是精度不够好,因为rost cm6本身的分词做得不是很好,自然影响到后续的共现矩阵的构建,可以导入已经分好词的文件代替它,可以做到一定程度上的优化;
- 第二个是图片不够美观,这个问题的优化措施是,将rost cm6生成的共现矩阵导出,再将这个表格导入到Gephi软件中生成语义网络共现图,会好看很多。
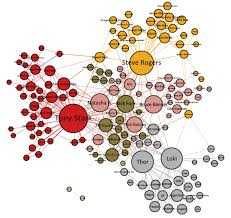
(图源google)
四、主题分析
或许再难避开编程手段,我做到主题分析的这一步,使用的是Python的现成代码,做简单的调参来满足自己的需求。功能实现的主要过程离不开一个模型,其名为「lda」。
「lda」的功能描述为试图找到两类物体或事件的特征的一个线性组合,以能够特征化或区分它们(据百度)。
亲测在短文本分析的领域,无论是中文还是英文都表现地挺差的,搜索了解到,原因可能出现在
短文本的特征稀疏性上。
因此,在面对短文本居多的评论领域,不太推荐使用lda来做主题聚类分析。
所以,如果是游记类的长文本,可以尝试用lda主题聚类来做分析,但在短文本的数据集中,lda的表现难称优秀。而我在这一方面也并未具备见解性的看法,便不斗胆做推荐分享了。
本文作者 @ 我叫徐知鱼
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
