大数据 Hadoop 之 ZooKeeper 认识

zookeeper
Zookeeper字面上理解就是动物管理员,Hadoop生态圈中很多开源项目使用动物命名,那么需要一个管理员来管理这些“动物”。
在集群的管理中Zookeeper起到非常重要的角色,他负责分布式应用程序协调的工作。
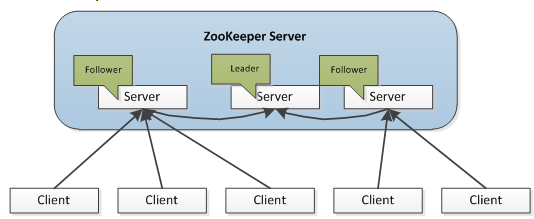
Zookeeper集群架构图
Zookeeper管理集群会选举一个Leader节点(可参考FastLeader选举算法,即快速选举Leader节点),Leader节点主要负责整个Zookeeper集群的运行管理,Follower负责管理具体的数据存储与读取。
_Zookeeper是一款通用的集群管理工具,不仅适用于Hadoop集群,在其他的集群中也可能被用到,比如ESB_集群。
_搭建Zookeeper集群要求整个集群节点为奇数,这样可以避免选举中选票相同的两个节点出现,类似于7大常委或11_个国会成员在进行选举时不允许弃权,两个备选的节点总有一个会胜出。
Zookeeper主要提供以下四点功能:统一命名服务、配置管理、集群管理、共享锁和队列管理,用于高效的管理集群的运行。
- 统一命名服务
命名服务指通过指定的名字获取资源或者服务提供者的信息。分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于识别和记忆。通常情况下使用树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构,即对人友好又不会重复。
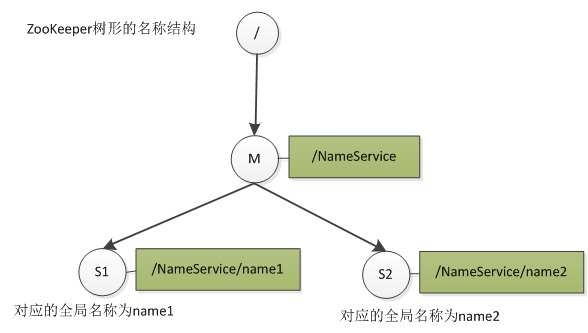
Zookeeper树形名称结构
Zookeeper集群中统一由Leader节点(图中M节点)来管理所有Follower节点(图中的S1和S2节点)的命名空间。Zookeeper提供统一的命名服务,他不对外提供数据也不存储数据,他只提供一套统一的命名规则,运行在Zookeeper之上的服务需要遵循这一套命名规则。其中较为常见的就是一些分布式服务框架中的服务地址列表。通过调用ZK提供的创建节点的接口(API),能够很容易创建一个全局唯一的路径(path),这个path就可以作为一个名称。命名服务(NameService)已经是Zookeeper内置的功能,你只要调用Zookeeper的API就能实现。如调用create接口就可以很容易创建一个目录节点。
阿里巴巴集团开源的分布式服务框架Dubbo中使用ZooKeeper来作为其命名服务,维护全局的服务地址列表。
在Dubbo实现中:服务提供者在启动的时候,向ZK上的指定节点/dubbo/${serviceName}/providers目录下写入自己的URL地址,这个操作就完成了服务的发布。
_服务消费者启动的时候,订阅/dubbo/{serviceName}/providers目录下的提供者URL地址,并向/dubbo/{serviceName} /consumers目录下写入自己的URL_地址
遵循Leader统一管理命名规则下,集群中数据读写的方式:
1.1.写数据,一个客户端进行写数据请求时,会指定Zookeeper集群节点,如果是Follower接收到写请求,会把请求转发给Leader,Leader通过内部的Zab协议进行原子广播,直到所有Zookeeper节点都成功写了数据,然后Zookeeper会给Client发回写完响应。
1.2.读数据,因为集群中Zookeeper按照统一的命名空间,所有Zookeeper节点呈现相同的命名空间视图(文件目录名称结构),所以读数据的时候请求任意一台Zookeeper节点都一样。
_集群中写数据的问题,存在数据并没有在集群中完成写入,集群数据还未同步,就已经更新了命名空间。这个时候使用最新的名称去读取数据会读到错误的数据,解决数据不同步问题,只能通过同步机制(定时执行sync()_方法)解决。
- 配置管理
配置的管理在分布式应用环境中很常见,例如同一个应用需要在多台服务器上运行,但是它们的应用系统的某些配置相同的,如果要修改这些相同的配置项,就必须同时修改每台运行这个应用系统的PC Server,这样非常麻烦而且容易出错。像这样的配置信息完全可以交给Zookeeper来管理,处理起来非常便捷。
配置的管理包含发布和订阅两个过程,顾名思义就是将数据发布到ZK节点上,供订阅者动态获取数据,实现配置信息的集中管理和动态更新。
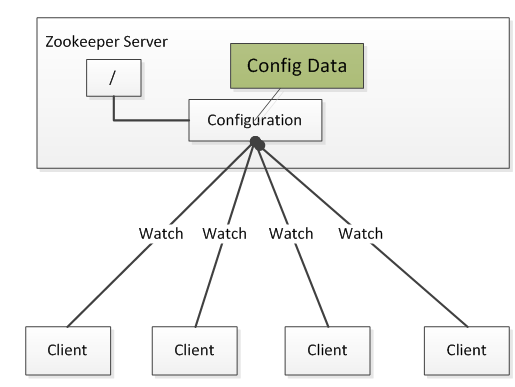
配置管理结构图
如图所示,将配置信息保存在Zookeeper(Leader节点)的某一个目录中,然后将所有需要修改的应用机器订阅该Zookeeper(Leader节点)节点,一旦Leader节点发布新配置信息,每台订阅的机器就会收到Zookeeper的通知,然后从Zookeeper获取新的配置信息应用到系统中,完成配置的集中统一管理。
- 集群管理
Zookeeper在集群管理中主要是集群监控和Leader选举。
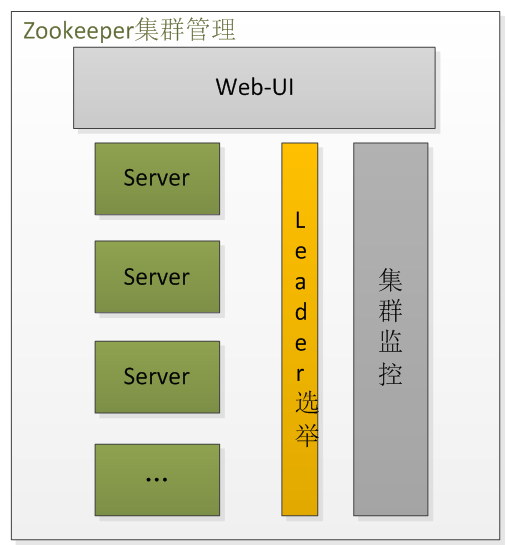
集群管理架构图
3.1.集群管理
这通常用于那种对集群中机器状态、,机器在线率有较高要求的场景,能够快速对集群中机器变化做出响应。这样的场景中,往往有一个监控系统,实时检测集群机器是否存活。过去的做法通常是:监控系统通过某种手段(比如ping)定时检测每个机器,或者每个机器自己定时向监控系统汇报"我还活着"。
这种做法可行,但是存在两个比较明显的问题:
1).集群中机器有变动的时候,牵连修改的东西比较多。
2).有一定的延时。
利用ZooKeeper中两个特性,就可以实施另一种集群机器存活性监控系统:
1).客户端在示例节点A上注册一个监控者(Watcher),那么如果A的子节点变化了,会通知该客户端。
2).创建EPHEMERAL类型的节点,一旦客户端和服务器的会话结束或过期,那么该节点就会消失。
3.2.Leader选举:
Leader选举即从大量集群节点中选举一个Leader节点,是zookeeper中最为经典的使用场景,在分布式环境中选举的Leader节点好快会直接影响集群的效率。Leader节点主要负责相同的业务应用分布在不同的机器上共用的逻辑模型和数据的调配,优秀的调配方案可以大大减少重复运算,提高性能降低集群的负载。
_如一些耗时的计算,要求提高集群计算能力的使用,而网络I/O处往往只需要让整个集群中的某一台机器进行执行,其余机器可以共享这个结果。如果Leader节点将I/O处理分配到每一个计算节点进行处理,处理I/O_消耗计算资源势必会降低集群运算效率。
利用ZooKeeper中两个特性,就可以实施另一种集群中Leader选举:
1).利用ZooKeeper的强一致性,能够保证在分布式高并发情况下节点创建的全局唯一性,即:同时有多个客户端请求创建Leader节点,最终一定只有一个客户端请求能够创建成功。利用这个特性,就能很轻易的在分布式环境中进行集群的Leader选举了。
2).另外,这种场景演化一下,就是动态Leader选举。这就要用到EPHEMERAL_SEQUENTIAL类型节点的特性了,这样每个节点会自动被编号。允许所有请求都能够创建成功,但是创建节点会为每个节点安排顺序,每次选取序列号最小的那个机器作为Leader。
小结
Zookeeper作为Hadoop主要的组件,在集群管理方面为我们提供了解决方案。通过对统一命名服务、配置管理和集群管理的阅读,我们能够清晰的理解Zookeeper的核心内容。针对共享锁和队列服务偏技术实现,有兴趣的可以进一步研究。
Zookeeper在大数据集群中解决集群管理的问题,磨刀不误砍柴工,了解完工具我们下一次分享一些具体的实效应用。
文/1比特
关键字:大数据
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
