如果被信息流控制了喜怒哀乐,你会让算法对你负责吗?
人们从信息的狩猎者逐渐变成猎物,难怪会被信息流控制自己的情绪。
最近,很多企业都在谈算法的价值观。在乌镇互联网大会上,张朝阳谈到了这个话题,在之前今日头条举办的AI大会上,哈佛教授Cyrus Hodes也提到人工智能应该承担更多的社会责任。
在以前看到这种论调,我总想为企业喊冤。技术钻研、产品开发、组织经营已经很费力了,企业创造价值、提供就业就已经足够负责了。还要为算法技术这种来源于用户数据的东西塑造价值观?不过在了解过Facebook一个有颇多争议的实验后,我开始逐渐改变了这种想法。
在2013年,Facebook联合康奈尔大学、UC旧金山分校的研究员在2013年于美国国家科学院院刊发表了一篇名为“社交网络中大规模情绪扩散的实验证据”的论文。实验的主要内容是,更改用户信息流中的情绪,看看用户会有怎样的反馈。事实证明,在用户信息流中灌输“正能量”的信息,用户也会给出正面的反馈,反之则是给出负面的反馈。
由于这则实验是在用户不知情的情况下进行的,“实验”人数涉及到了将近七十万人。互联网上对这则实验进行了强烈的抨击,认为Facebook的行为极大的违反了人伦道德。
其实我们都知道,真正让人们感到恐惧的,是Facebook可以通过信息流轻易操纵人们情绪这件事。
从猎手到猎物,弱者才会被“操纵”
回溯到互联网的“上古时代”,人们寻找信息的方式是非常简单的。例如搜狐的黄页形式,整个互联网上的信息寥寥无几,以至于可以用分类排列的形式展现出来。当时的人们要知道自己要找的网站属于那一类,才能在黄页互联网上尽情冲浪。
此时人们对获取信息的把控力可以达到90%。在昂贵的拨号网络之外,还有大量的电视、广播、纸质媒体构成人们对世界的认知。
随着信息的爆发式增长,一本黄页已经远远不足够。到了谷歌、百度的搜索引擎时代,关键词成为了寻找信息的利器。这时的人们已经可以带着问题来寻找信息,SEO、SEM等等广告形式也让企业开始有权力去“控制”用户看到那些信息。
同时,廉价的宽带资费和更丰富的信息增加了互联网的权重,让其在人类认知来源构成中的地位更高。换句话说,人类认识世界的窗口变窄了。
等到了今天,移动终端的小屏特征带来了信息流和时间线,而这两者一个来自于编辑推荐/算法推荐,另一个则来自于用户的关注关系。人们已经很难再去主动寻找信息,而是接受编辑、算法认为适合他们的信息。
此时,移动互联网下沉基本完毕,人们获取信息的渠道更为集中,对于获取信息的把控程度却在下降。人们从信息的狩猎者逐渐变成猎物,难怪会被信息流控制自己的情绪。
让渡信息窗口,直到成为算法的镜中人
其实互联网发展的过程,可以被看做一个人类不断让渡信息窗口的过程。
从黄页时期到搜索引擎的发展中,我们把部分信息窗口让渡给了流量和金钱。广告主和高热度话题有权力占据我们信息窗口的主要位置。而从发展引擎到信息流的发展中,社交关系和原生广告加大了高热度话题和广告主在信息窗口中的占比,而剩下的部分则被让渡给推荐算法和编辑。
信息流的出现,是这个让渡的过程中最为关键的一步。我们虽然把信息窗口交了出去,却获得了更多、更具个性化的信息。黄页时代的几十万个网站怎么可能满足人们丰富的需求?广告主会鼓励内容创造者创造更多内容,编辑和推荐算法帮助我们找到最适合我们的内容。
这一切看似是非常良性的循环,可问题的关键在于:信息流和推荐算法无处不在,它们已经不仅仅意味着我们浏览什么,而对我们生活的很多方面都起到了关键性的作用。
Facebook的实验,只是简单的校验了一下信息茧房的假说,结果却发现信息流可能会影响到人们的情绪。实际在购物、旅行、音乐等等的选择上,我们都会被信息流左右。
信息流影响了我们读什么新闻、看什么电影、买什么东西,而这些行为数据又被记录下来,成为了自身画像的一部分,也成了算法构成的依据,某种程度来说,这一切都会让我们和算法中的自己越来越像。
算法的第一要务是……
当人们和算法中的自己越来越像(即使只是有这种可能性),算法的价值观、人工智能的责任感这种论调就有了存在的必要。在内心深处,我们感受到了一种对自我把控的无力感。提出价值观、责任感这种要求,就好像弱者对强者耍赖,要求签订一条互不侵犯的条约。
那么问题是,难道就是为了我们自己的不安全感,信息流相关技术作为窗口的缔造者,就有必要五讲四美、三热爱?
这时问题就上升到了更高形态:成为健康美好正直的人,是一种普世的价值观。可没人有权力阻止另一个人成为猥琐阴险低俗的人。
如果算法承担了教育人性工作,不顾高中生的兴趣标签是王者农药,在内容平台推荐数学题,在电商平台推荐《三年模拟五年高考》。以前的“我可能喜欢”、“我可能感兴趣”、“和我一样的人都在看”全都变成“你需要看”、“为了身体健康你最好买这个”“比你优秀的人看了这些”。
那样的确是价值观很正,可这行为真的正确吗?
郭德纲说过,相声的第一要务是教育人,好不好笑没关系。
到底是谁没有价值观跟责任感?
所以说了这么多,答案是算法不该有价值观,人工智能不该有责任感吗?
当然不是。
在以往的“技术责任事故”中,如果要追究责任,第一责任人往往是一位不作为的人类。如果说算法该有价值观,那价值观也应该来自于人的作为。
- 第一,慎用作为信息窗口权力。 不能再把一些莫名的条款隐藏在长长的用户须知中,然后像Facebook一样把自己的用户作为实验品。
- 第二,明晰人类和技术的权责划分,做好人类的分内事。 举个例子,把鉴黄、鉴假这种事一味的交给人工智能完全是不负责任的懒政,出了问题就责怪技术的不成熟而不是人的不作为,AI真的觉得很冤!
- 第三,给予用户充分的知情权和选择权。 让用户在越来越小的信息窗口中清晰的知道信息为什么会出现。比如不管原生广告(自以为)做的多么有趣、多么原生,请务必标注上“广告”二字。而给用户推荐信息时,最好明确给出推荐理由,并给予用户拒绝某一标签或某一推荐来源的权力。不要在用户点击“不再推荐此类内容”后假装看不见然后继续推荐。
多的不说,只要人类能做到以上三点,算法就会很有价值观了。如果能从技术角度多进行一些优化,我们的信息流会变得非常让人愉悦。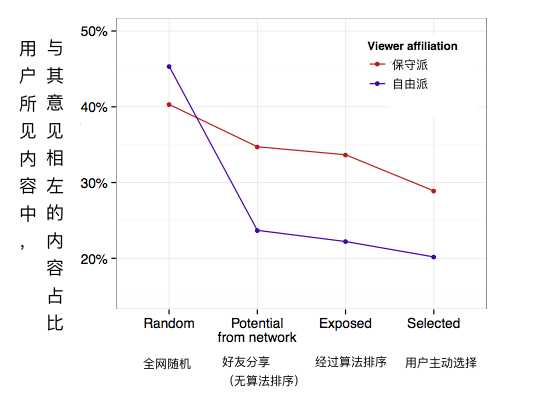
这篇文章的开头,是一场Facebook主导的实验,但在文章的最后,我想给大家介绍另一篇Facebook的研究成果。
2015年(在那场实验的两年之后),Facebook研究了14年一年的用户数据,为用户和新闻链接的政治倾向都打了分,看看用户会不会主动浏览跟自己政见有冲突的新闻。
结果如图所示,Facebook随机展示出的信息是一样多的,但用户们靠着自己的社交关系(自由派会关注更多的自由派,反之亦然)筛掉了一大部分政见相左的信息,靠自己的点击又筛掉了一大部分,最后才是被算法推荐筛选掉的。而算法逻辑本身又部分成立在社交关系和用户行为之上。结论就是,在信息展示这件事上,个人选择比算法的影响更大。
所以,即使信息茧房这种说法是存在的,但把成因最小的算法推荐当做罪魁祸首,是不是在欺负算法不会说话?
作者 @脑极体 。
关键字:算法, 信息流, 信息, 价值观
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
