推荐策略产品经理必读系列—第四讲推荐系统的召回(二)
前言:上一篇为大家介绍了推荐系统召回策略里面基于规则的召回,本篇将为大家介绍推荐系统召回策略中基于协同过滤算法的召回。
一、协同过滤算法综述
大家应该在很多场合或者文章中都听到过协同过滤算法,首先到底什么是协同过滤(Collaborative Filtering),它的核心思想是什么。
何为协同:
协同字面意思就是大家在一起互相配合来做成某一件事情。在协同过滤算法里指的就是利用群体的数据去寻找规律,去寻找物料与物料,用户与用户之间的相似性。
何为过滤:
过滤字面意思就是把不符合条件的东西给过滤掉。在协同过滤算法里指的就是当我们基于物料相似度或者用户相似度进行推荐时,需要把那些相似性很低的物料和用户过滤掉。
那“协同+过滤”:其实就是利用群体的数据去寻找规律,去寻找物料与物料,用户与用户之间的相似性,然后再把相似性很低物料和用户过滤掉,挑选出相似度最高的物料和用户。
协同过滤算法的产生是推荐算法1.0时代“基于内容的标签召回”算法后,人们开始利用数据本身探讨用户与用户,物料与物料之间的关联性,从而演化出来了协同过滤(Collaborative Filtering)算法。
标志性的算法就是基于用户的协同过滤算法,该算法在1992年被提出。协同过滤算法可以说是推荐领域最经典的算法了。甚至可以说协同过滤算法的出现,代表了推荐系统的出现。协同过滤算法一共分为两个大的方式:基于邻域的方法和基于模型的方式。

下面我们将详细展开介绍:
二、基于领域的方法
2.1 基于用户的协同过滤(User-Based)
AB用户拥有相同的背景和兴趣,基于用户之间的相似性,为A推荐用户B感兴趣且用户A没有接触过的内容。比如大学时候,我们都会问同专业的学长学姐应该选什么课。这个就是学长学姐和我们有一样的专业背景,基于他们过去经验上过的课,一定可以推荐出哪些考试简单给分又高的课,如果这个课很难给分又低,学长学姐们一定不会去上这个课。整个算法分为两个大的步骤:
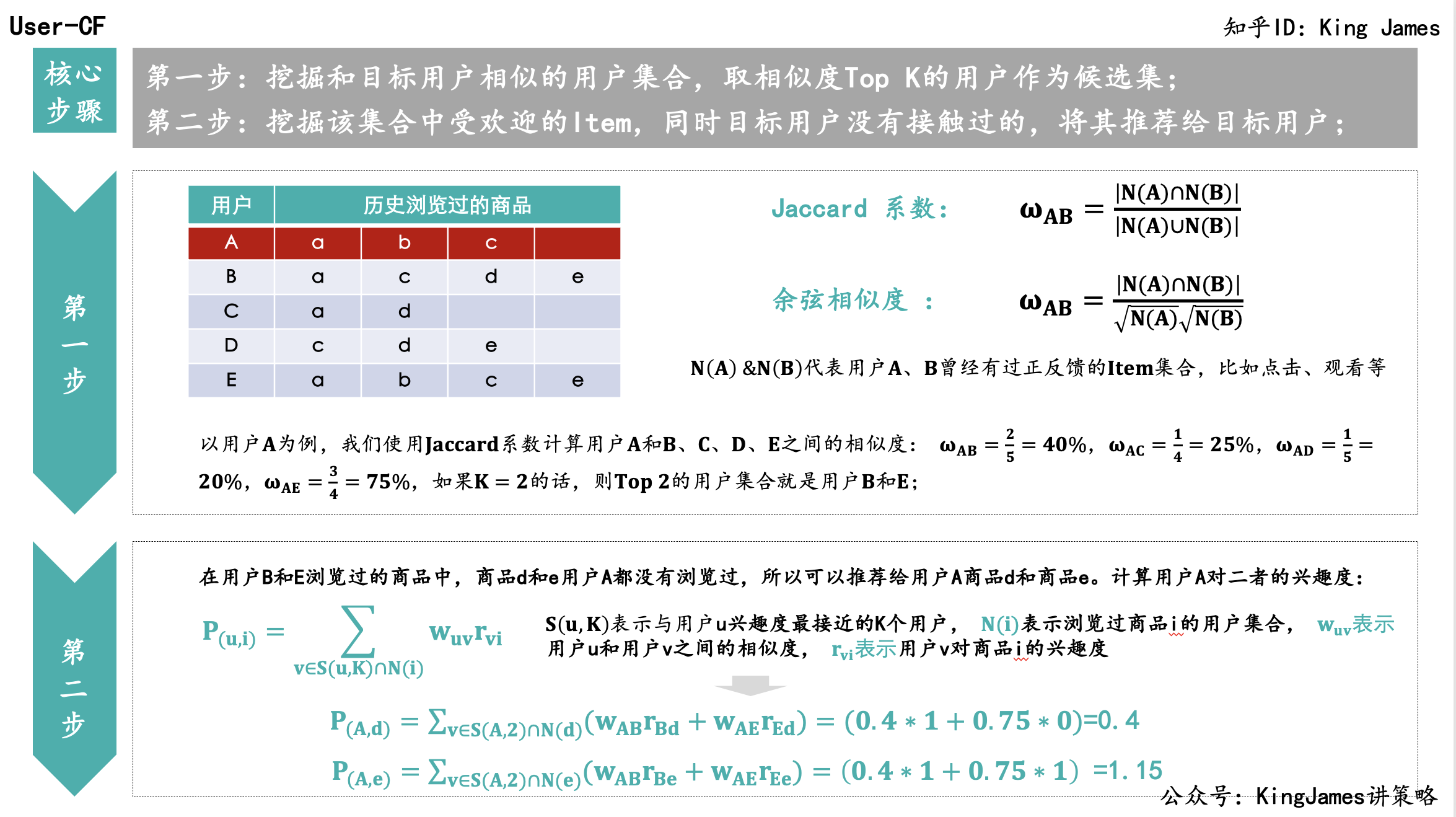
第一步:挖掘和目标用户相似的用户集合;
如何计算用户之间的相似性,一般我们使用Jaccard系数或者余弦相似度。具体公式如下:

上图左侧为历史用户浏览商品数据,右侧为计算用户相似度的公式。用户数很庞大,所以一般我们会设置一个K值,找出与用户A最相似的Top K个用户。例子中我们设置K为2,根据公式我们可以计算出与用户A相似度最高的两个用户是用户B和用户E。
第二步:挖掘该集合中受欢迎的Item,同时目标用户没有接触过的,将其推荐给目标用户;

用户B和E历史浏览过的商品中,商品d和e用户A没有浏览过,需要计算用户A对于商品d和e的兴趣度。计算公式如上图所示,我们以用户A对商品d的兴趣度举例:( 用户A与用户B的相似度 * 用户B对于商品d的兴趣度 ) + ( 用户A与用户E的相似度 * 用户E对于商品d的兴趣度 ),这里用户之间的相似度第一步里面已经计算过了,用户B & E对于商品d的兴趣度,我们统一设定:如果浏览过兴趣度就为1,没有浏览过兴趣度就为0。
实际业务中,我们可以更加细化,比如同一时间段浏览的次数等将兴趣度计算方式更加细化。最终计算出用户A对商品e的兴趣度为1.15,对商品d的兴趣度为0.4,所以优先推荐商品e。
User-CF算法1992年就已经在某电子邮件的个性化推荐系统上得到了应用,关于User-CF算法的优缺点我们在介绍完Item-CF算法以后进行统一对比介绍。
2.2 基于物料的协同过滤(Item-Based)
基于物料之间的相似性,通过用户历史喜欢的物料,为其推荐相似的物料。这里面的物料相似性并不是基于物料之间标签重合度来计算相似度,Item CF是基于用户对于物料的历史行为数据来计算物料之间的相似度。Item-CF最早是由亚马逊公司提出的,目前在各大互联网公司应用都十分频繁。
整个算法同样分为两个步骤:
第一步:计算商品之间的相似度;
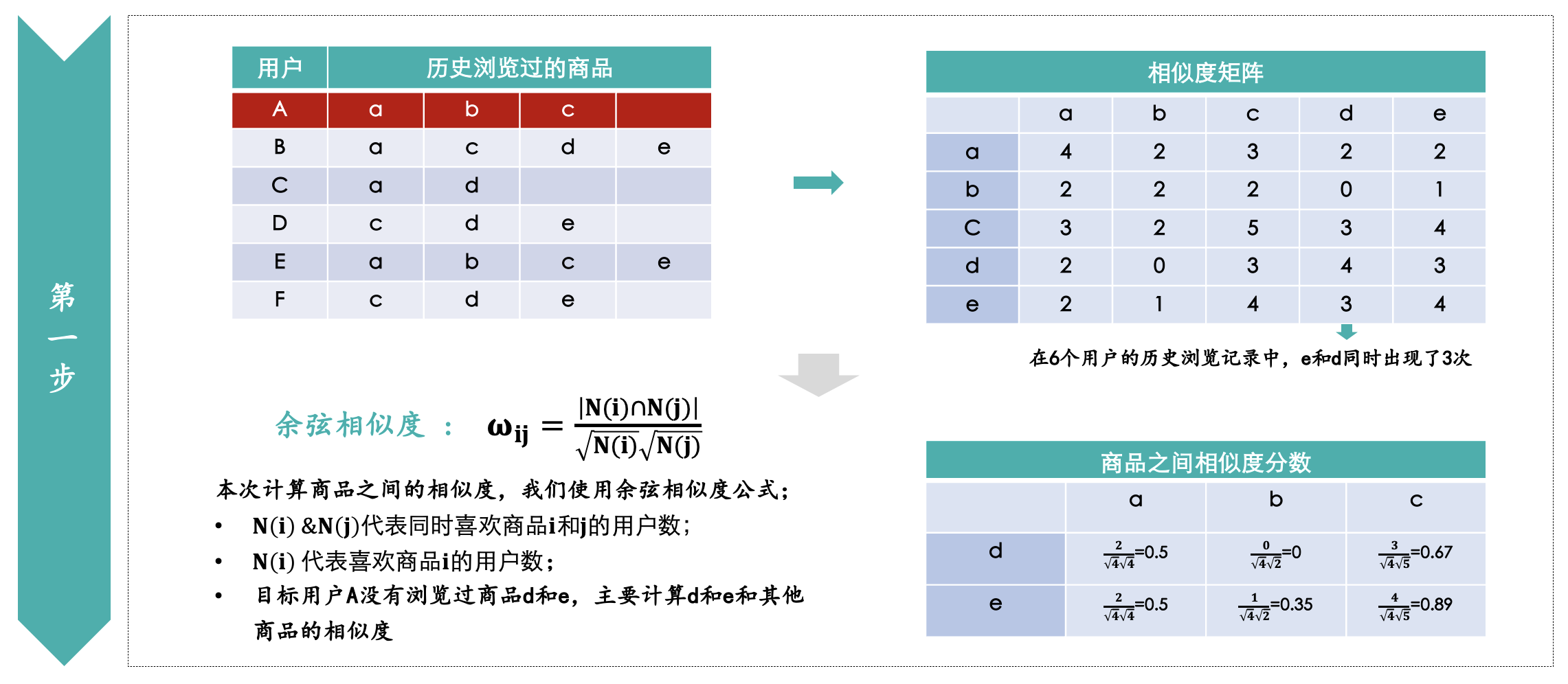
首先我们基于用户历史浏览的行为,统计两个商品被同一用户浏览过的次数,比如pair(e,d)同时被3个用户都浏览过,那么相似度矩阵里面就填入3。最后我们使用余弦相似度公式来计算商品之间的相似度。
第二步:基于目标用户历史浏览行为和商品之间的相似度,为其推荐感兴趣且未浏览过的商品;

相似度计算完以后,我们需要计算用户对这些没有浏览过商品的兴趣度。比如我们计算用户A对于商品d的兴趣度,案例中因为一共只出现了5个商品,只有d和e用户A没有浏览过,这里的K值我们就设置为3,我们只基于商品d和a,b,c之间的相似度以及用户A对于商品a,b,c的兴趣度进行计算。
实际案例中用户A浏览过的商品很多,和d有交集的商品也会很多,我们需要设置一个合理的K值,无法计算商品d和所有商品的相似度,再去乘以用户A对于这些商品的兴趣度。最终根据上述公式计算得出用户A对e的兴趣度为1.74,对d的兴趣度为1.17。所以优先为用户A推荐商品e。
最后我们用下面这张图将User CF和Item CF之间的区别进行归纳:
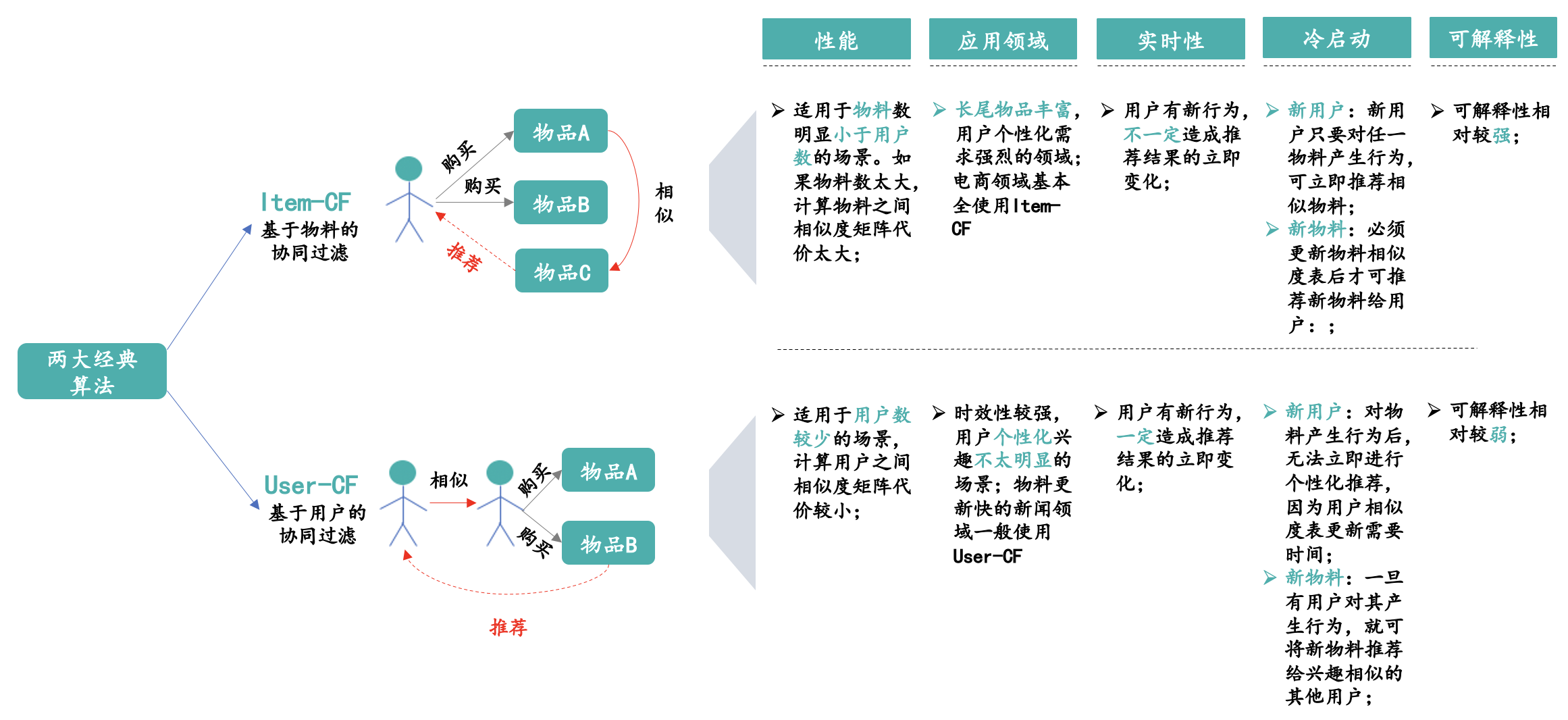
上图里面有几个核心的点需要关注。
(1)应用领域
User-CF在新闻社交网站等UGC社区使用的较多,而Item-CF在电商、电影&音乐等网站使用的较多。一方面因为新闻等网站内容更新快,使用Item-CF无法满足时效更新的要求,另一方面新闻等网站上用户的兴趣相对粗粒度,很多用户群体喜欢阅读同一内容。而在电商、电影等网站上用户兴趣相对比较个性化,使用Item-CF更能够反映用户兴趣的传承。
(2)可解释性
User-CF的解释性弱于Item-CF,因为User-CF是侧重于人与人之间的相似,给用户A推荐用户B感兴趣的东西。而Item-CF是侧重于基于用户A历史买过的商品,为其推荐相似的商品。从直观上用户也更愿意相信Item-CF这种推荐方式。
三、基于模型的方法
协同过滤是一种思想,很多时候大家在讲协同过滤时就讲User-CF和Item-CF,其实协同过滤中有很大一部分甚至说当前先进的协同过滤算法都是基于模型的协同过滤。下面为大家介绍几种常见基于模型的协同过滤。
3.1 基于图模型(Graph-based model)
第一步:将数据由表格转化为二分图;
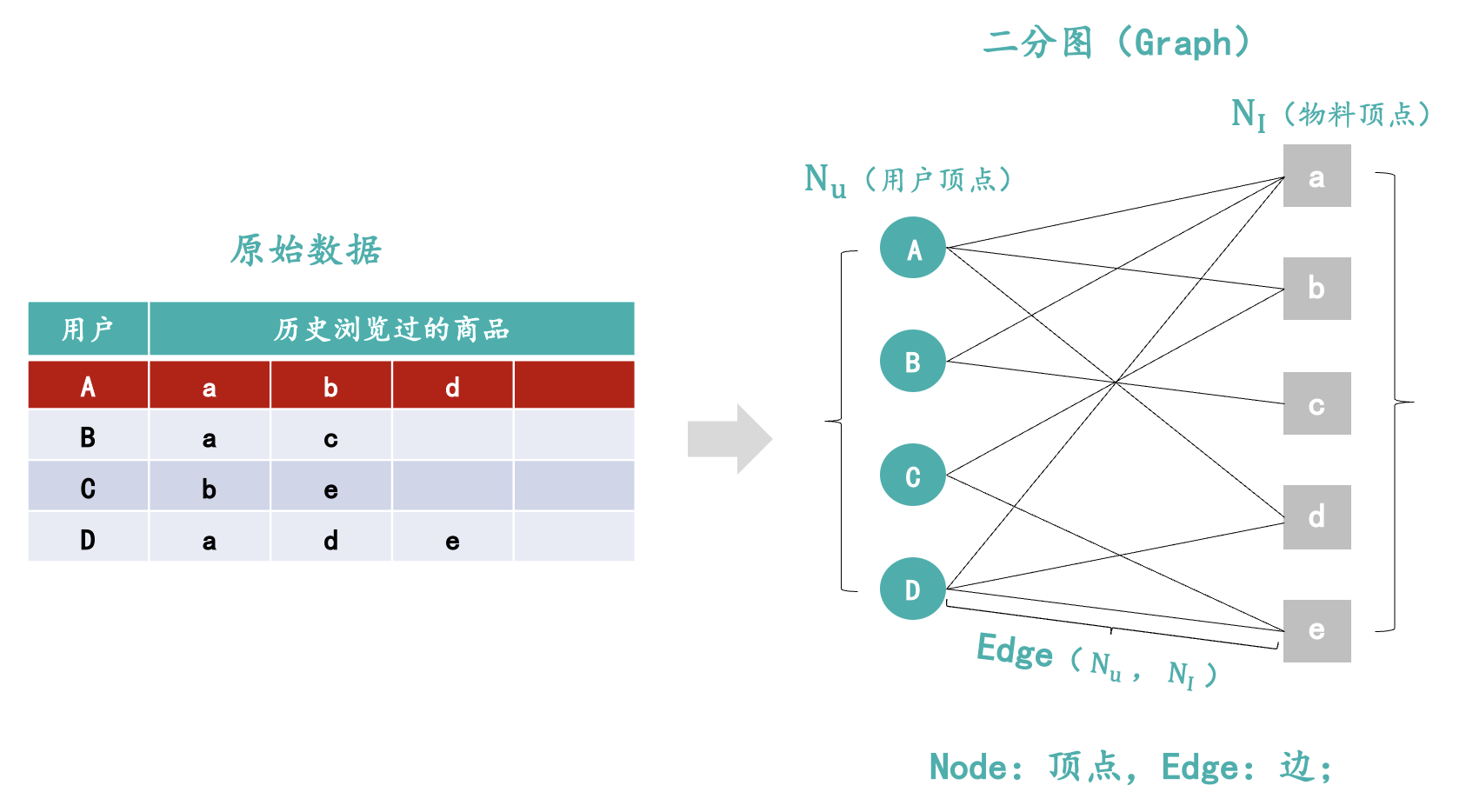
我们将表格用户历史浏览过的数据转化为Graph,左边为用户Node,右边为物料Node。用户浏览过的物料两个顶点之间就连一条线,顶点与顶点之间的连线我们叫做边Edge。
第二步:基于两个顶点之间路径数、路径长度及经过的节点出度判断相关性;
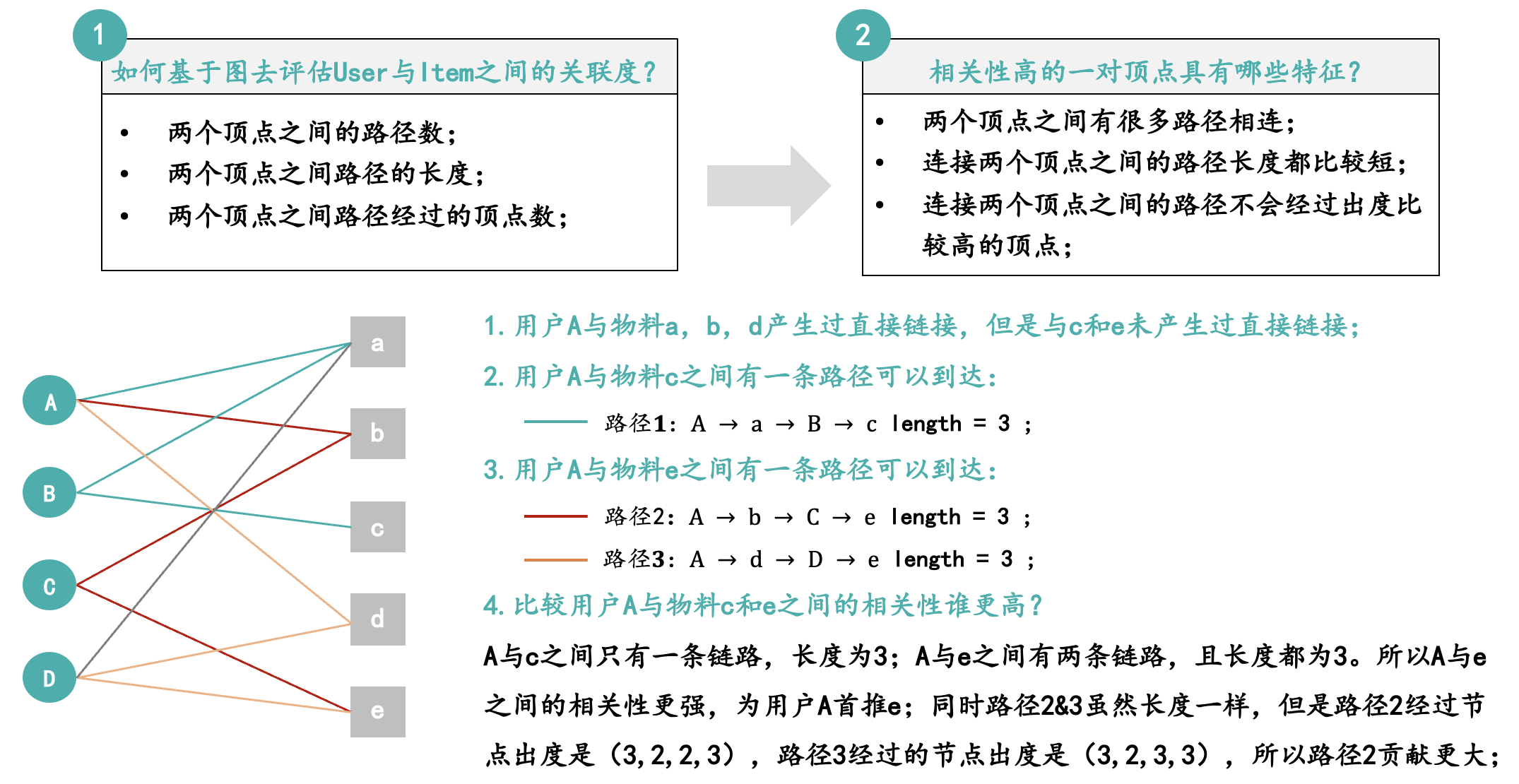
比如我们计算用户Node-A与物料Node-c和Node-e之间的相关性。首先我们统计Node-A到Node-c可以有几条路径,这里面只有一条路径可以到达就是A—a—B—c,长度是3。而Node-A与Node-e之间一共有两条路径可以到达,分别是A—b—C—e和A—d—D—e,长度均为3。所以Node-A和Node-e的相关性要强于NodeA与Node-c。
同时我们再去比较同样是两条长度为3的路径“A—b—C—e”,哪条路径产生的链接更强了?我们分别去统计两个路径经过Node的出度,何为出度?
出度就是该Node对外连接几个其他Node,比如Node-A的出度就是3。
两条路径经过节点的出度分别是【3,2,2,2】和【3,2,3,2】,该某个节点的出度越大代表这个节点的链接越多,该节点和连接的单个节点的相关性就越弱。所以路径A—b—C—e产生的A与e的相关性要强于A—d—D—e产生的A与e的相关性。
以上就是基于图模型的协同过滤算法。
下一篇将重点为大家介绍基于向量的召回,大家经常听到的FM模型以及双塔模型,大家敬请期待~
本文作者 @King James 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
