标签如何帮助B2B营销服务客户
为了提升营销效率,我们需要更清晰地认识到我们服务的客户对方,他们是谁及他们的意图。
这个时候,用户标签就排上了用场,通过从用户信息中抽取出用于说明用户特征的结构化数据,通常是认为规定的特征标识,用于高度精炼的特征进行描述,是对线索的定性分析数据。
主要作用体现在第一,标签可以使原本无法描述、搜索和定位的数据也可以被描述、搜索和定位;第二,不同的标签有不同的权重,有助于后续的线索打分,且能满足个性化需求;第三,通过标签可以将信息之间建立某种联系,最终为海量信息建立起相互关联的信息网。
针对标签的不同类型:事实型标签、分析型标签、预测型标签,其中事实型标签、分析性标签是客观存在的,属于统计型画像,而预测型画像更强调预测的准确度。
一、事实型标签
事实型标签,即根据用户的事实型行为打标签,可以通过4W着手,即who(谁)、when(什么时候)、where(在哪里)、what(做了什么)。
1. who(谁)
who(谁),即用户识别,其目的是为了区分用户。
互联网主要的用户识别方式包括Cookie、注册ID、微信微博、手机号等,获取方式由易到难,不同企业的用户信息数据化程度有所不同,用户识别的方式也可按需选取。
对于高客单价企业,进入到线索阶段后,一般已经具有了基本人口统计、公司信息、BANT信息,用户识别相对简单。
2. when(时间)
when(时间),这里的时间包含了时间跨度和时间长度两个方面。
“时间跨度”一般指以天为单位计算的时长,指某行为自发生到现在间隔了多长时间;“时间长度”则为了标识用户在某一页面的停留时间长短。
在用户行为中,普遍认为近期发生的行为更能反映用户当下的特征,因此过往行为将表现为在标签权重上的衰减,即所谓的“时间衰减因子”,如图所示。
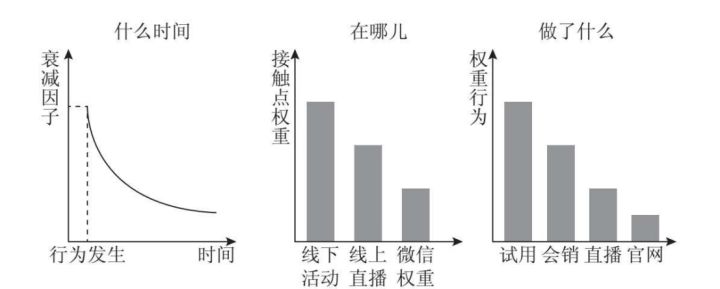
3. where(在哪里)
where(在哪里),就是指用户发生行为的接触点,里面包含内容和网址。
内容是指用户所作用对象标签;网址则指用户行为发生的具体地点。
内容决定标签,网址决定权重。
4. what(做了什么)
what(做了什么),就是指用户发生了怎样的行为,即用户的行为类型,例如线上搜索、微信阅读、观看直播、参加线下活动、下载电子书、产品试用等,根据行为的深入程度添加权重。
4W着手,可以简单勾画出一个用户行为的标签权重公式:标签权重=时间衰减(何时)×网址权重(何地)×行为权重(做什么)。
举个直观的例子,“B用户今天在产品页面试用了产品”反映出的用户标签可能是“获客”;而“A用户一周前在微信收藏了内容营销类文章”反映出的标签可能只是“内容营销0.448”,如图所示,这些不同用户的标签及相应的权重将在后续的营销决策中发挥指导作用。

二、分析型标签
分析型标签,是对于线索数据的进一步加工。
最典型的方式是RFM模型,即从最近一次消费R(recency)、消费频率F(frequency)、消费金额M(monetary)这三个维度分析某一个潜在用户的价值。
1. 最近一次消费R
即用户最近一次的购买时间。消费时间最近的用户是最有可能对提供的商品或服务有反应的群体。
离上一次购买很近的用户,人数如增加,则表示该公司是个稳健成长的公司;反之则要有所预警。
2. 消费频率F
即用户在限定期间内所购买的次数。最常购买的用户,也是满意度最高的用户。
如果相信品牌及商店忠诚度的话,最常购买的用户,忠诚度也最高。
增加用户购买的次数意味着从竞争对手处偷取市场占有率。
3. 消费金额M
即用户的购买金额,可分为累积购买及平均每次购买。消费金额是所有数据库报告的支柱,也可以验证“帕累托法则”——公司80%的收入来自20%的用户
3个变量可以用三维坐标系进行展示,x轴表示recency,y轴表示frequency,z轴表示monetary,坐标系的8个象限分别表示8类用户,可以用图4-6进行描述。

三、预测型标签
预测型标签需要基于事实型标签和分析型标签做出预测。
预测型标签的生产流程:特征抽取→监督学习→样本数据→评估→标签产出,是经典的机器学习流程,在设计标签时要注意以下几点:
尽量窄化范围,减少某个标签可能的意义范围。
标签要统一:风格一致,如活泼的或严肃的;版面样式一致,字体、字号、颜色、空白、分组方式一致,视觉上强化标签群组的系统性本质;语法一致,名词“餐厨”,动词“做饭”等同一层级不要混用。
易理解:标签所指示的系统范围应该能够让人充分理解,有助于用户快速扫描,推论出应用所提供的内容。
在打标签的过程中,可以用简单的方法快速走通整个流程,然后再进行每个环节的优化。同时,在进行线索定性过程中,要及时通过头脑风暴进行优化。
相关利益者(市场部和销售部)闭门会议,展开头脑风暴。
深入以下问题:目标市场是什么样的?销售人员觉得获得的销售线索数量是多了还是少了?数据库现有线索的质量?转化好的线索有什么特征?什么样的线索不受欢迎?
确定“好”是多好:设置基准级别。
确定“好”线索的标准,并定期审查,不断迭代培育机制。
公众号:致趣百川(ID:BesChannels)
本文作者@致趣百川 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
