KANO模型的量化处理
很多大厂在产品商业化、产品设计以及运营方面已经达到了非常精细化程度,比如在对需求优先级进行排序的时候,大家都听说过KANO模型,很多产品经理也会采用该模型去“凭感觉”进行划分,但感觉的问题在于一些模糊不清的地带和一些需要通过互相说服来决策的时刻,这种定性的方式很难让人达成共识。于是很多公司的用研部门会将“定量”的方式引入其中进行辅助,尤其越是庞大的产品,越是会做这样的事情。
既然说到这,那就来聊聊KANO模型,在定量的方式上可以如何去实施。
背景就不去做交代了,假定目前已经确定了一些需求已经要做,但由于开发资源以及项目时间周期的限制,目前只能从中挑出一部分需求去进行设计,而且大家争执不下的情况下,于是通过收集到用户以及内部员工具体的一些答案通过统计结果来进行量化抉择,便挑选出合适的用户发出了调查问卷,设计问卷的时候为了方便后面的量化操作,问题需要存在一定的设计逻辑。
一、明确需求分类
先基于KANO模型,可以把需求分成如下几类:
- M:必备型需求,即痛点
- O:期望型需求,即符合预期的
- A:兴奋型需求,即超出用户预期的
- I:无差异型需求,即用户不在意的
- R:反向型需求,即会引起用户反感的
对吧,很简单,但你思维稍微停一下,你会发现,它的本质只不过是按照将需求对用户的感受进行了不同程度的分类,这些程度之间是存在逻辑上的递进关系的。
你不觉得这玩意的底层逻辑跟之前接触过的很多东西都很像吗?比如,学校里面给学生打分的时候会有优秀、良好等方面的评级,公司里会按照不同岗位划分出不同的组织架构,哪怕去个奶茶店也会遇到小杯、中杯、大杯的区分。
这些东西的底层逻辑,要概括一下的话,其实都是基于MECE原则对某个事物按照“彼此独立,完全穷尽”的方式进行了分类而已。
二、调查问卷设计
为了更好的得到方便量化的结果,问题设计上可以分为两个方向并提供不同的选项供用户选择。
问题可以包含两个方向:增加某个功能后用户的态度以及不增加某个功能时用户的态度
答案则提供几种不同的程度,由喜欢程度的高到低分别是:非常喜欢、符合预期、无所谓、勉强接受、很不喜欢
最终构建出来的结果如下图所示:
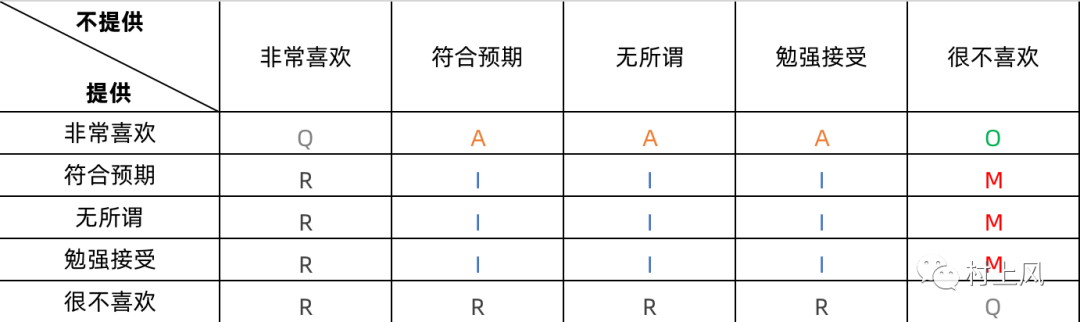
那么,在这里有一种比较特殊的情况,就是可疑结果(Q),毕竟对于一个功能的提供与否,用户都表现出了很喜欢或者很不喜欢这种自相矛盾的情况,所以,这样的结果在最终统计时,一般都需要排除掉。
同样,思维在这里稍微停一下,你会发现依然是一个仿佛接触过无数过的玩意。好像有点四象限法则的影子?好像还有点SWOT分析的赶脚?甚至这玩意还似曾相似的出现在你不知道要不要跳槽而感到迷茫时,你在纸上列出来的不同维度的对比……
其实,这些东西的底层就是矩阵思维,本质就是多角度纵横交叉的看待同样的一个问题。
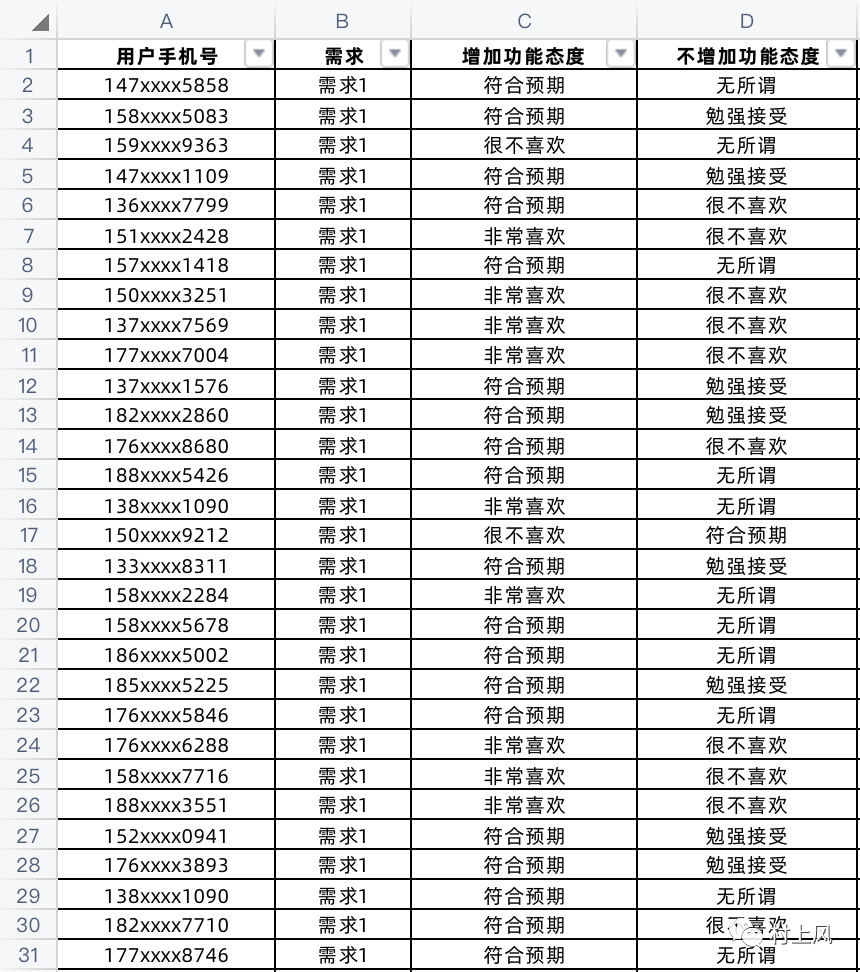
三、调查问卷数据清洗加工
在收集到问卷的结果后,对数据进行清洗并加工。下图所示就是之前我们在公司收集上来的调查问卷当中部分用户的反馈结果:
四、对问卷进行需求分类
再结合上面的不同需求类型的矩阵图,就可以针对每一条需求都划分出每个用户所认为的需求的类型是什么了,最终我们就定义出了需求的类型如下图所示:

到这里之后,其实问题就出现了。对于同样一条需求,不同用户所定义的需求类型是不一样的,那么,我们总得按照某种方式计算出一个最后的标准吧?最典型的思维方式就是少数服从多数,于是就可以考虑采用统计同一需求不用用户不同类型的定义,然后计算趋向于对用户带来好的方向影响的占比,再计算给用户带来不好的方向影响的占比,最后按照平均值划分进行定义。
在KANO模型里也是采用了上面的思考方式,只不过定义出了一个叫做better-worse系数的东西。
better系数 = (A+O)/(A+O+M+I)
worse系数绝对值 = |-(M+O)/(A+O+M+I)|
按照收集上来的问卷(包含了900份调查问卷的结果),统计和计算后的数据如下图所示:

将统计后的每个需求对应的坐标点放置在better-worse坐标系当中,并且在坐标系当中基于所有的坐标点,生成better的平均值对应的参考线以及worse的平均值对应的参考线,划分出最终的兴奋型、必备型、期望型、无差异型需求,按照优先级必备型>期望型>兴奋型>无差异型划分出优先级即可。

至此,一个KANO模型在实际工作中的量化处理案例就讲完了。
作者:小风,产品经理;公众号:村上风
本文作者 @小风 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
