如何用机器学习满足产品需求
关于机器学习有太多的文章介绍了,如果还对机器学习一知半解的可以参考一下其他文章,我的其他文章中也有简单介绍了机器学习。本文主要介绍机器学习的应用以及我们如何使用机器学习满足产品需求,尽量不说废话。
作为AI产品经理,不仅需要知道技术的边界,还要对应用场景的有足够的理解。
谈到谈到机器学习,有些人还不清楚机器学习和深度学习、人工智能之间的关系,甚至以为是一回事——其实不是这样的。
下面这个图可以帮助大家梳理这三者之间的关系: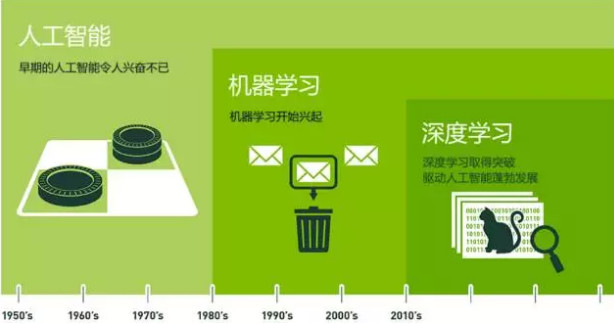
人工智能是个很泛的概念,有很多不同的方向:
50年代-70年代,人们认为赋予机器推理能力就能够使得机器具有智能,具有代表性的工作是图灵奖得主A.Newell和H.SImon的“逻辑理论家”程序。随着研究的逐渐深入,人们意识到仅有逻辑推理还是远远达不到智能的,必须要有先验知识。
这阶段人们试图将人类的知识抽象成规则输出到机器,也就是所谓的专家系统。
显然,知识是浩瀚的海洋,很快人们就遇到了瓶颈,几乎不可能准确的去概括所有知识。
例如语音识别,一开始人们把字词的发音做成模板,通过模板匹配的方式做识别,可想而知由于不同的人的发音习惯,加上不同的口音,语速等等,使得识别率一直都很差。
关于语音的特征,是很难人工去刻画的;于是就有学者提出了让机器自己学习的思路,并进行了相关的研究——这就是机器学习。
而深度学习是机器学习的一个方向:得益于计算能力的提升和互联网发展带来的大量数据累积,往往只要调节好参数,就能得到不错的性能。
深度学习并没有严格的理论基础,可以说是“大力出奇迹”的一种方法,降低了了机器学习应用的门槛。
一、什么时候可以使用机器学习?
首先我们要明白:什么是智能?
广义上来说,只要是能够根据先验知识,通过决策对外部刺激做出合理反馈的行为都可以称为智能。
互联网产品在这几年的发展大多数是基于流程化,是一种对于信息的重新组织和优化。一般来说只要有一个输入,我们就能够得到一个预期的输出——直观上就是“不智能”。
仔细想一下:是不是和人工智能最开始的“逻辑推理”阶段有点像?
互联网刚开始兴起的时候,流程优化、打破信息不对称,提升了社会效率,积累了大量的数据;同样的,现在信息的高度流通,也达到了一个“瓶颈”。
那么,如何进一步提升效率呢?机器学习给出了一个答案:现在的大数据就相当于“先验经验”,通过机器学习,让信息触达能够做到“千人千面”,降低了无效信息的损耗,让资源得到更加合理的配置。
所以使用机器学习的第一个目标,就是要 帮助产品突破“瓶颈”,提高效率。
现在回答什么时候使用机器学习?或者说是具备了什么样的条件的业务适合使用机器学习?
1.业务目标清晰(抽象为分类/回归问题)
在使用机器学习之前,要明确业务目标。
单独的机器学习在目前是很难直接支撑其一个场景产品的(区别于工具产品),所以机器学习的业务目标一般散落在产品业务的各个角落。例如向用户推送营销信息,如果全量推送,既无法保证转化率,又会骚扰用户,这是一种“低效率”的方式,可以使用机器学习找出可能会对营销信息感兴趣的用户推送。
其实大多数适用机器学习的业务场景都能够过抽象为分类(离散化)/回归(连续化)的问题。
- 常见的分类问题:识别问题(人脸识别、指纹识别、花草识别)
- 常见的回归问题:预测问题(点击率预测、转化率预测)
2.机器学习的成果能够作用于业务
在某项业务中使用机器学习,机器学习的成果要能够反过来作用于业务(提升转化率、提高用户体验等等)。
举个例子,假设你拿到大量的个人数据,可以准确预测出某个人的购物喜好,但是这份数据并没有这些人的联系方式,则预测的结果实际上是没办法作用到业务的。
再举个例子,如自动摘要,如果自动摘要出来的结果准确率不高,则这些结果是没有什么价值的,同样不能满足“能够作用于业务”。
3.具备“特征”
具备特征是很重要的一点。
如垃圾邮件识别,可能具备的特征有:无规则的邮箱地址、含有生僻字、发信时间等等——那么很显然可以使用机器学习解决。
反例,通过长相预测年收入。
仔细想想:年收入高的人在长相上具备什么“特征”吗?这个是个谜;或许还真有,但是不好说。但是如果使用机器学习去做这样的预测,除非是做学术研究,否则在生产环境中是不太适合的。
4.具备“样本”
无论是统计机器学习还是深度学习,都是需要样本的。
而样本获取可以是基于业务经验收集,如第3点的垃圾邮件识别,根据经验我们就可以收集邮箱地址、发信时间等等维度的特征。
如果没有业务经验,也可以进行全量的收集,特征不是越多越好,特征太多就会造成过拟合。
如果新加入的特征让准确率提升不大但是让模型的复杂度提升很大,我们就认为这个特征是不必要的。
二、如何提机器学习产品需求?
除了常规的界面需求、流程需求之外,涉及到机器学习的产品需求还应包括:
1.业务场景描述
作用是让算法人员理解业务场景,更好的理解输入与输出的需求,可以包含对业务经验的描述。
以垃圾邮件识别为例:在用户接收的邮件后,推送提醒之前,对邮件进行判定,如果为垃圾邮件,则不推送提醒,将邮件转移到放入”垃圾邮件“文件夹。
2.目标(输出)定义
什么样的邮件才是垃圾邮件?含有广告信息?含有欺诈信息?不同的人都有不同的定义。但是总是能够找得到一个共识。定义和特征类似,不是越完整越好,越完整的定义,泛化能力就越差。
例如你把广告信息定义为垃圾邮件,但是有用户爱好奇特,喜欢看广告,对于他们来说就不是垃圾邮件。
明确的定义主要是用来指导标注,关于标注那些事儿在我的上篇文章已经详细介绍,有兴趣可以翻阅。
关于垃圾邮件,可以列出几条定义如:无内容、内容杂乱、明显的黄暴信息等等。
如果是回归问题,如预测销售量,定义销售量=受众群体数×转化率。受众群体数一般可知,则预测转化率即算出销售量。
3.指标要求
关于机器学习的四个指标,简单提一下,许多文章都有介绍了。查准率(Precision)、查全率(Recall)、精确度(Accuracy)、F值。这是封闭测试集中的指标,如果是生物识别问题,还涉及错误接受率、错误拒绝率、等错率等指标。产品需要根据业务需要,或者是充分的数据分析来确定指标要求。
4.样本提供
样本越全,对于机器学习的性能的提升的帮助越大。样本需要客观、准确。有全量样本是最好的,如果没有,要使用抽样样本,要保证抽样样本的分布构成和实际保持一致。
作者 @跹尘 。
关键字:产品经理, 机器学习, 邮件, 样本
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
