李宏毅深度学习HW7
李宏毅深度学习---HW7
- 1、任务介绍
- 2、数据集
- 3、词语划分
- 为什么长段落是一个问题?
- 4、训练数据窗口划分
- 5、测试数据窗口划分
- 6、提示
- (1)线性学习速率衰减
- (2) stride
- (3)预处理
- (4)其他预训练模型
- (5)后加工
- (7)自动混合精度
- (8)梯度累积
- 7、实验
- (1)Simple Baseline (Acc>0.45139)
- (2)Medium Baseline (Acc>0.65)
- (3)Strong Baseline (Acc>0.78136)
1、任务介绍
使用BERT模型,微调用于下游任务,解决从文章提取答案的问答题。


2、数据集
ARCD:增量阅读理解数据集
ODSQA:开放域口语问题回答数据集
●train: DRCD + DRCD-TTS ○10524段,31690个问题
●dev: DRCD + DRCD-TTS ○1490段,4131个问题
●test: DRCD + ODSQA ○1586段,4957个问题
训练数据集含有答案:
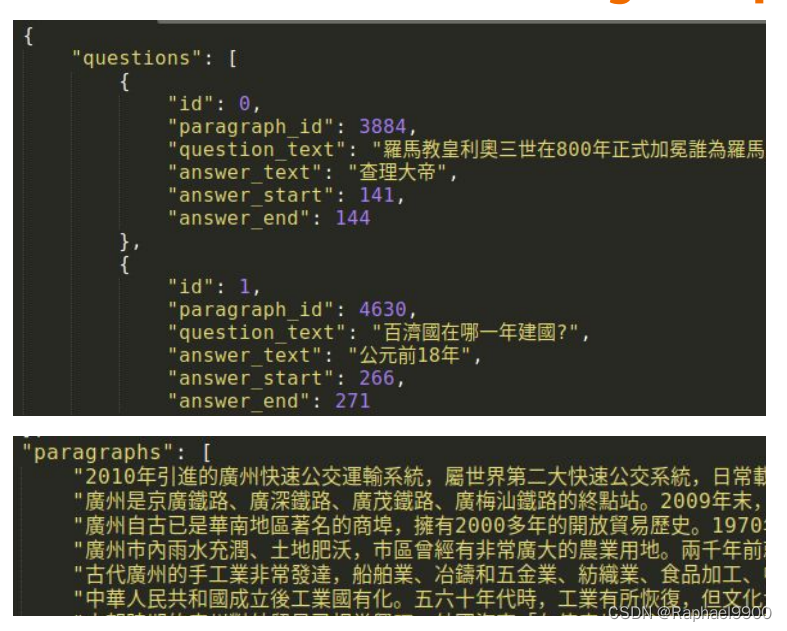
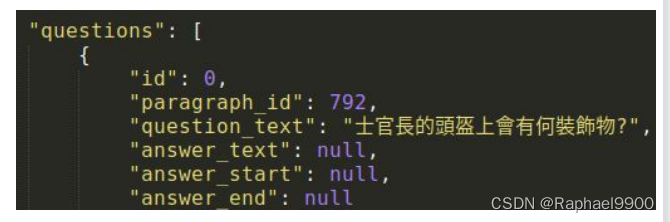
测试数据集没有答案:
3、词语划分
把句子断词,然后转换成代码才能传到模型训练。

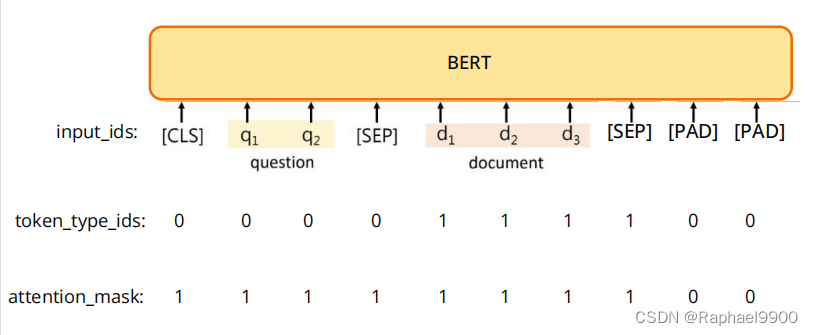
文章和问题输入之前要用一些特殊符号,[PAD]表示文章不够长时的占位符。传进模型有两段文字时使用token_type_ids,用0表示前一段文字,1表示后一段文字,[PAD]用0表示。attention_mask表示我们希望模型学习attention的位置,用1表示,[PAD]用0表示,不学习。
为什么长段落是一个问题?
总序列长度=问题长度+段落长度+3(特殊标记)。
BERT的最大输入序列长度被限制为512,为什么?变压器中的➔transformer中的自注意具有( O(n2))的复杂度,因此,我们可能无法处理整个段落。我们能做什么?
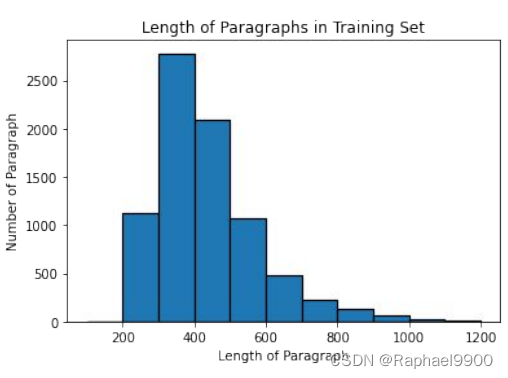
在训练集中的数据长度一般都是位于300-400之间,但是也有很长的到1200。
解决方法分为训练和测试数据的方案:
4、训练数据窗口划分
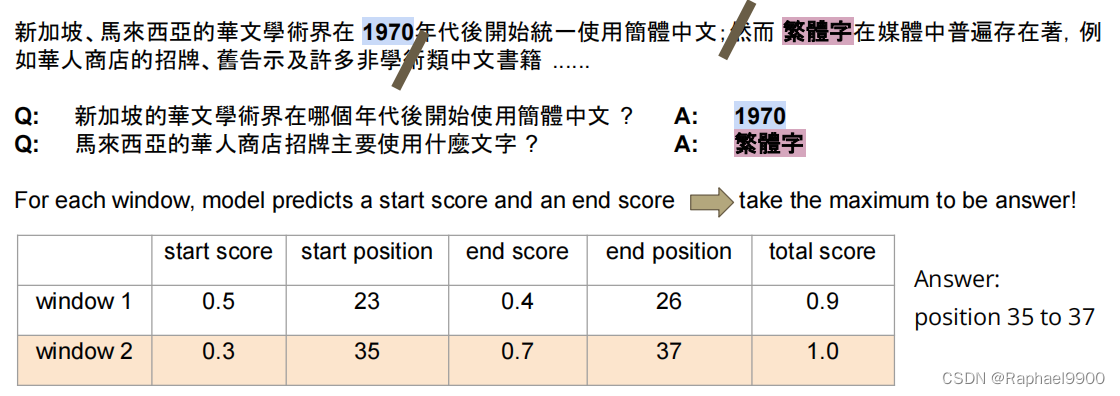
我们知道在训练中答案在哪里!
假设:回答这个问题所需的信息可以在答案附近找到!
简单的解决方案:只要在答案周围画一个窗口(尽可能大)!
例如,窗口大小为= max_paragraph_len = 32。

5、测试数据窗口划分
我们不知道答案是在测试分裂到窗口!
答案可能不在中间,而在窗口的两边,这样我们怎么做呢?如果每个划分的句子之间是没有重叠的,那如果答案分布在两个句子里面怎么办?所以我们希望句子之间可以设置重叠,然后根据下面的总分数得到答案的位置。
6、提示
(1)线性学习速率衰减
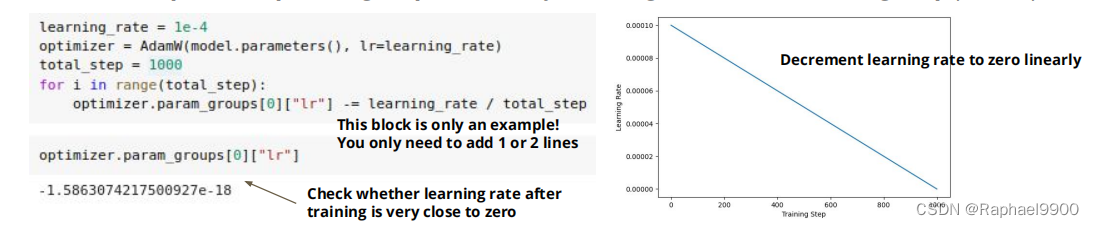
方法1:手动调整学习率
这种方法需要注意学习率不能是太明显的复数
Decrement optimizer.param_groups[0][“lr”] by learning_rate / total training step per step
方法2:通过调度程序自动调整学习速率

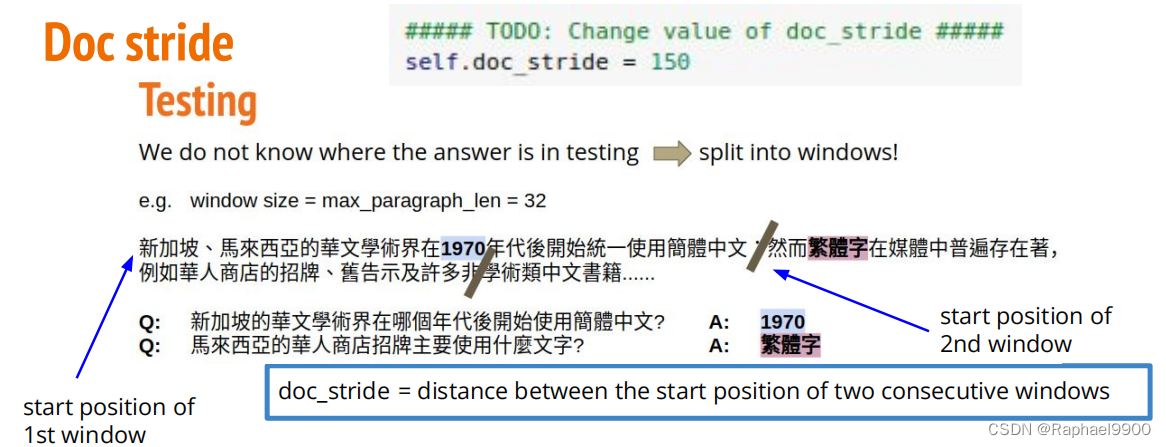
(2) stride
doc_stride:两个连续窗口的起始位置之间的距离
doc_stride在示例代码中被设置为“max_paragraph_len”(即没有重叠),如果答案是在窗口的边界附近或跨窗口怎么办?提示:重叠窗口。
(3)预处理
提示:如何防止模型学习到它在训练过程中不应该学习的东西?(即答案并不总是靠近窗口的中间)
##### TODO: Preprocessing ###### Hint: How to prevent model from learning something it should not learnif self.split == "train":# 将paragraph_text中答案的开始/结束位置转换为tokenized_paragraph中的开始/结束位置 answer_start_token = tokenized_paragraph.char_to_token(question["answer_start"])answer_end_token = tokenized_paragraph.char_to_token(question["answer_end"])#通过对包含答案的段落部分进行切片来获得单个窗口mid = (answer_start_token + answer_end_token) // 2paragraph_start = max(0, min(mid - self.max_paragraph_len // 2, len(tokenized_paragraph) - self.max_paragraph_len))paragraph_end = paragraph_start + self.max_paragraph_len# 分割问题/段落并添加特殊标记(101: CLS, 102: SEP)input_ids_question = [101] + tokenized_question.ids[:self.max_question_len] + [102] input_ids_paragraph = tokenized_paragraph.ids[paragraph_start : paragraph_end] + [102] # 将tokenized_paragraph中答案的开始/结束位置转换为窗口中的开始/结束位置answer_start_token += len(input_ids_question) - paragraph_startanswer_end_token += len(input_ids_question) - paragraph_start# 填充序列并获得模型输入input_ids, token_type_ids, attention_mask = self.padding(input_ids_question, input_ids_paragraph)return torch.tensor(input_ids), torch.tensor(token_type_ids), torch.tensor(attention_mask), answer_start_token, answer_end_token(4)其他预训练模型

可以在里面找到。

(5)后加工
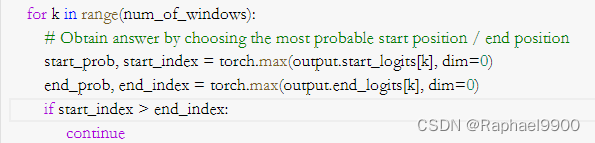
如果预测的end_index <预测的start_index怎么办?
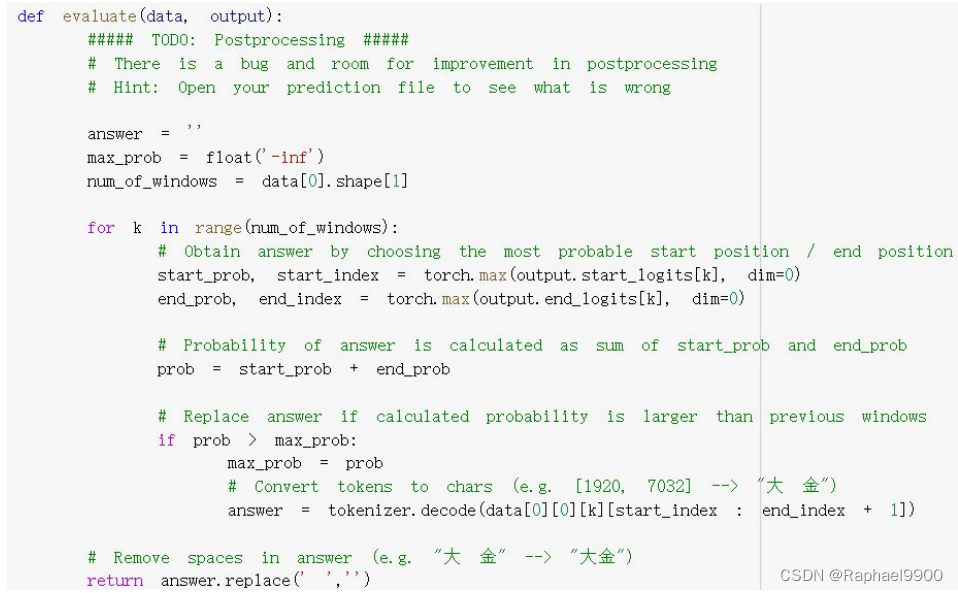
在evaluate函数中,可能出现预测的start index比end index大的情况,要添加代码修复。
(7)自动混合精度
●PyTorch训练默认使用32位浮点(FP32)算法
●自动混合精度(AMP)使自动转换某些GPU操作,从FP32精度到半精度(FP16)。
●提供约1.5-3.0倍的速度,同时保持精度。

警告:仅适用于某些gpu(如T4、V100)
(8)梯度累积
当gpu内存不足,但您想使用更大的批量大小
●将全局批量分割成更小的小批
●为每个小批量:累积梯度而不更新模型参数
●更新模型参数

7、实验
(1)Simple Baseline (Acc>0.45139)


保持不变:





(2)Medium Baseline (Acc>0.65)




保持不变:



(3)Strong Baseline (Acc>0.78136)

用新的预训练模型

新的模型大小是1.2G,它比原BERT模型的400M大了很多,这样造成内存不够,需要降低batch size。

累积梯度:


在evaluate函数中,可能出现预测的start_index比end_index大的情况,要添加代码修复。
class QA_Dataset(Dataset):def __init__(self, split, questions, tokenized_questions, tokenized_paragraphs):self.split = splitself.questions = questionsself.tokenized_questions = tokenized_questionsself.tokenized_paragraphs = tokenized_paragraphsself.max_question_len = 40self.max_paragraph_len = 150##### TODO: Change value of doc_stride #####self.doc_stride = 150# Input sequence length = [CLS] + question + [SEP] + paragraph + [SEP]self.max_seq_len = 1 + self.max_question_len + 1 + self.max_paragraph_len + 1def __len__(self):return len(self.questions)def __getitem__(self, idx):question = self.questions[idx]tokenized_question = self.tokenized_questions[idx]tokenized_paragraph = self.tokenized_paragraphs[question["paragraph_id"]]##### TODO: Preprocessing ###### 提示:如何防止模型学习它不应该学习的东西if self.split == "train":# 将paragraph_text中答案的开始/结束位置转换为tokenized_paragraph中的开始/结束位置answer_start_token = tokenized_paragraph.char_to_token(question["answer_start"])answer_end_token = tokenized_paragraph.char_to_token(question["answer_end"])# 通过对包含答案的段落部分进行切片来获得单个窗口mid = (answer_start_token + answer_end_token) // 2paragraph_start = max(0, min(mid - self.max_paragraph_len // 2, len(tokenized_paragraph) - self.max_paragraph_len))paragraph_end = paragraph_start + self.max_paragraph_len# Slice question/paragraph and add special tokens (101: CLS, 102: SEP)input_ids_question = [101] + tokenized_question.ids[:self.max_question_len] + [102] input_ids_paragraph = tokenized_paragraph.ids[paragraph_start : paragraph_end] + [102] # Convert answer's start/end positions in tokenized_paragraph to start/end positions in the window answer_start_token += len(input_ids_question) - paragraph_startanswer_end_token += len(input_ids_question) - paragraph_start# Pad sequence and obtain inputs to model input_ids, token_type_ids, attention_mask = self.padding(input_ids_question, input_ids_paragraph)return torch.tensor(input_ids), torch.tensor(token_type_ids), torch.tensor(attention_mask), answer_start_token, answer_end_token# Validation/Testingelse:input_ids_list, token_type_ids_list, attention_mask_list = [], [], []# 段落被分成几个窗口,每个窗口的起始位置由步长“doc_stride”分隔for i in range(0, len(tokenized_paragraph), self.doc_stride):# Slice question/paragraph and add special tokens (101: CLS, 102: SEP)input_ids_question = [101] + tokenized_question.ids[:self.max_question_len] + [102]input_ids_paragraph = tokenized_paragraph.ids[i : i + self.max_paragraph_len] + [102]# 填充序列并获得模型输入input_ids, token_type_ids, attention_mask = self.padding(input_ids_question, input_ids_paragraph)input_ids_list.append(input_ids)token_type_ids_list.append(token_type_ids)attention_mask_list.append(attention_mask)return torch.tensor(input_ids_list), torch.tensor(token_type_ids_list), torch.tensor(attention_mask_list)def padding(self, input_ids_question, input_ids_paragraph):# 如果序列长度短于max_seq_len,则填充零padding_len = self.max_seq_len - len(input_ids_question) - len(input_ids_paragraph)# 词汇表中输入序列标记的索引input_ids = input_ids_question + input_ids_paragraph + [0] * padding_len# 指示输入的第一和第二部分的分段令牌索引。在[0,1]中选择索引token_type_ids = [0] * len(input_ids_question) + [1] * len(input_ids_paragraph) + [0] * padding_len#掩码,以避免关注填充标记索引。在[0,1]中选择的掩码值attention_mask = [1] * (len(input_ids_question) + len(input_ids_paragraph)) + [0] * padding_lenreturn input_ids, token_type_ids, attention_masktrain_set = QA_Dataset("train", train_questions, train_questions_tokenized, train_paragraphs_tokenized)
dev_set = QA_Dataset("dev", dev_questions, dev_questions_tokenized, dev_paragraphs_tokenized)
test_set = QA_Dataset("test", test_questions, test_questions_tokenized, test_paragraphs_tokenized)train_batch_size = 32# 注意:不要改变dev_loader / test_loader的批量大小!
#虽然批处理大小=1,但它实际上是由来自同一QA对的几个窗口组成的批处理
train_loader = DataLoader(train_set, batch_size=train_batch_size, shuffle=True, pin_memory=True)
dev_loader = DataLoader(dev_set, batch_size=1, shuffle=False, pin_memory=True)
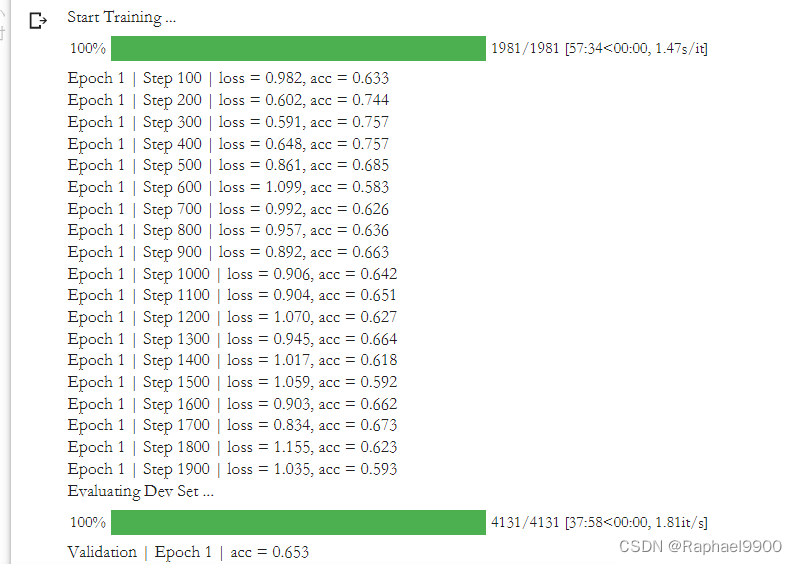
test_loader = DataLoader(test_set, batch_size=1, shuffle=False, pin_memory=True)def evaluate(data, output):##### TODO: Postprocessing ###### There is a bug and room for improvement in postprocessing # Hint: Open your prediction file to see what is wrong answer = ''max_prob = float('-inf')num_of_windows = data[0].shape[1]for k in range(num_of_windows):# 通过选择最可能的开始位置/结束位置获得答案start_prob, start_index = torch.max(output.start_logits[k], dim=0)end_prob, end_index = torch.max(output.end_logits[k], dim=0)# 答案概率计算为start_prob和end_prob之和prob = start_prob + end_prob# 如果计算的概率大于以前的窗口,则替换答案if prob > max_prob:max_prob = prob# Convert tokens to chars (e.g. [1920, 7032] --> "大 金")answer = tokenizer.decode(data[0][0][k][start_index : end_index + 1])# Remove spaces in answer (e.g. "大 金" --> "大金")return answer.replace(' ','')num_epoch = 1
validation = True
logging_step = 100
learning_rate = 1e-4
optimizer = AdamW(model.parameters(), lr=learning_rate)if fp16_training:model, optimizer, train_loader = accelerator.prepare(model, optimizer, train_loader) model.train()print("Start Training ...")for epoch in range(num_epoch):step = 1train_loss = train_acc = 0for data in tqdm(train_loader): # Load all data into GPUdata = [i.to(device) for i in data]# Model inputs: input_ids, token_type_ids, attention_mask, start_positions, end_positions (Note: only "input_ids" is mandatory)# Model outputs: start_logits, end_logits, loss (return when start_positions/end_positions are provided) output = model(input_ids=data[0], token_type_ids=data[1], attention_mask=data[2], start_positions=data[3], end_positions=data[4])# Choose the most probable start position / end positionstart_index = torch.argmax(output.start_logits, dim=1)#最大值索引end_index = torch.argmax(output.end_logits, dim=1)# Prediction is correct only if both start_index and end_index are correcttrain_acc += ((start_index == data[3]) & (end_index == data[4])).float().mean()train_loss += output.lossif fp16_training:accelerator.backward(output.loss)#反向传播计算得到每个参数的梯度值else:output.loss.backward()optimizer.step()#通过梯度下降执行一步参数更新optimizer.zero_grad()#梯度归零step += 1##### TODO: 应用线性学习率衰减 ###### 打印过去logging步骤的训练损失和准确性if step % logging_step == 0:print(f"Epoch {epoch + 1} | Step {step} | loss = {train_loss.item() / logging_step:.3f}, acc = {train_acc / logging_step:.3f}")train_loss = train_acc = 0if validation:print("Evaluating Dev Set ...")model.eval()with torch.no_grad():dev_acc = 0for i, data in enumerate(tqdm(dev_loader)):output = model(input_ids=data[0].squeeze(dim=0).to(device), token_type_ids=data[1].squeeze(dim=0).to(device),attention_mask=data[2].squeeze(dim=0).to(device))# prediction is correct only if answer text exactly matchesdev_acc += evaluate(data, output) == dev_questions[i]["answer_text"]print(f"Validation | Epoch {epoch + 1} | acc = {dev_acc / len(dev_loader):.3f}")model.train()# Save a model and its configuration file to the directory 「saved_model」
# i.e. there are two files under the direcory 「saved_model」: 「pytorch_model.bin」 and 「config.json」
# Saved model can be re-loaded using 「model = BertForQuestionAnswering.from_pretrained("saved_model")」
print("Saving Model ...")
model_save_dir = "saved_model"
model.save_pretrained(model_save_dir)
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!