机器学习中准确率、精确率、召回率、误报率、漏报率、F1-Score、APmAP、AUC、MAE、MAPE、MSE、RMSE、R-Squared等指标的定义和说明
在机器学习和深度学习用于异常检测(Anomaly detection)、电子商务(E-commerce)、信息检索(Information retrieval, IR)等领域任务(Task)中,有很多的指标来判断机器学习和深度学习效果的好坏。这些指标有相互权衡的,有相互背向的,所以往往需要根据实际的任务和场景来选择衡量指标。本篇博文对这些指标进行一个梳理。
一、名称解释
1、真实值actual value和预测值predicted value
这两者就是字面的意思,actual value是指真实记录的已发生的测量结果值,而predicted value是指对未发生的预测值。这里的值既可以是数值型,也可以是类别型。
2、真True、假False
这两个表示的是真实值与预测值之间是否吻合,true表示的是预测值与真实值一致,而false表示的是预测值与真实值不一致。
3、阳性Positive(正)、阴性Negative(负)
首先这里讨论的positive和negative不代表性别的取向,同时正和负也不代表正确或者错误。positive指条件或者事物存在,而negative指条件或者事物不存在。例如异常检测领域阳性positive代表存在异常,阴性negative代表不存在异常;如健康领域阳性positive代表检测存在病毒或者疾病,阴性negative代表检测结果是健康的。再如电子商务领域阳性positive代表点击或者成交,阴性negative代表未点击或者未成交。
4、曝光List、点击Click、加收藏Wish/加关注Follow、加购Cart、订单Order、支付Pay
这几项名称往往用于网络内容或者电商领域,代表的是一则内容或者一个商品从展现给用户到用户消费该内容或者商品的过程。含义就是由字面代表的意思。
二、分类指标的定义和说明(准确率、精确率、召回率、误报率、漏报率)
首先看下面这张图,里面对部分指标做了定义。接下来对各个指标的定义和说明进行阐述:
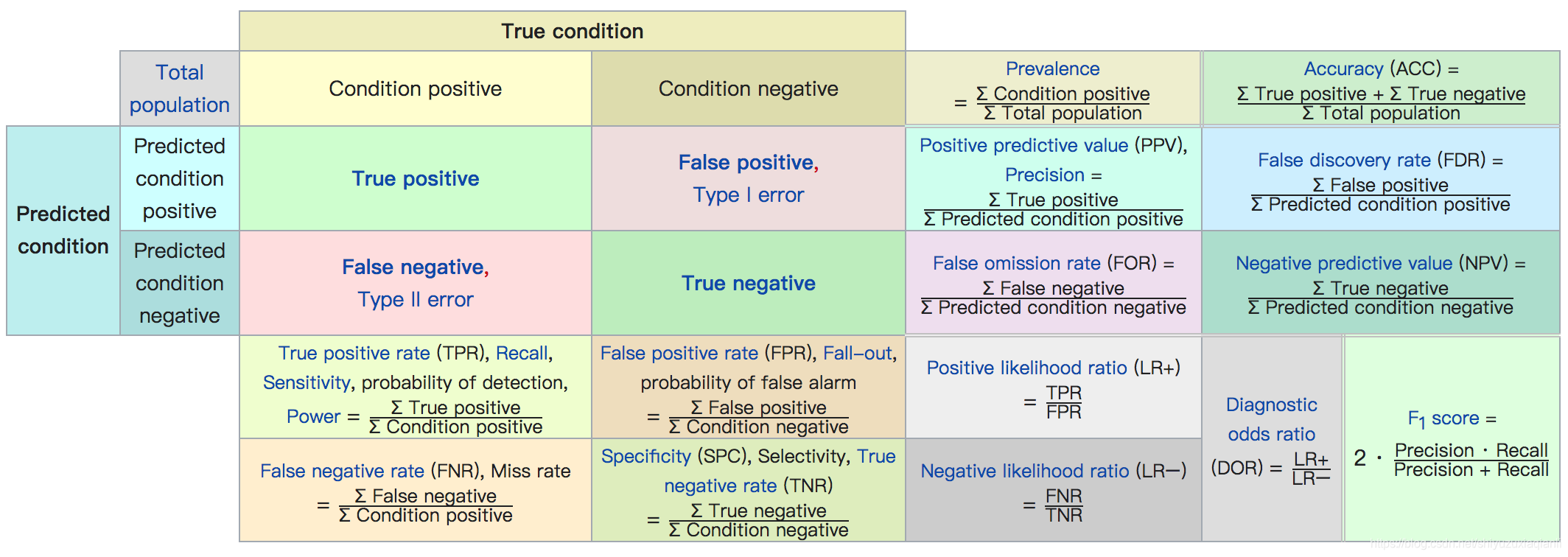
如上图,将样例(样本,后面两者混用)分为阳性(正,后面两者混用)样例和阴性(负,后面两者混用)样例
,将正样本预测为正样本的为True positive(
),正样本预测为负样本的为False negative(
),负样本预测为正样本的为False positive(
),负样本预测为负样本的为True negative(
)。所以有
,
。
1、准(正)确率accuracy
反映分类器或者模型对整体样本判断正确的能力,即能将阳性(正)样本positive判定为positive和阴性(负)样本negative判定为negative的正确分类能力。即预测正确的结果占总样本的百分比。值越大,性能performance越好
这里注意,在负样本(或者正样本)占绝对多数的场景中,即样本不平衡的情况下,不能单纯追求准确率,因为将所有样本都判定为负样本(或者正样本),这种情况下准确率也是非常高的。
2、精确率precision
反映分类器或者模型正确预测正样本精度的能力,即预测的正样本中有多少是真实的正样本。值越大,性能performance越好
这里注意,单纯追求精确率,会造成分类器或者模型少预测为正样本,这时低,即精确率就会很高。
3、召回率recall,也称为真阳率、命中率(hit rate)
反映分类器或者模型正确预测正样本全度的能力,增加将正样本预测为正样本,即正样本被预测为正样本占总的正样本的比例。值越大,性能performance越好
这里注意,单纯追求召回率,会造成分类器或者模型基本都预测为正样本,这时低,即召回率就会很高。
4、误报率false alarm,也称为假阳率、虚警率、误检率
反映分类器或者模型正确预测正样本纯度的能力&
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!