效果分析的关键是「指标能算出来」
看到题目会不会有一些奇怪?这算什么关键……
经历过才知道,这是一个不起眼但却极为重要的部分,企业在数据驱动发展进程中必然会遇到指标算不出来的情况,而且随着企业规模的不断扩大,这一问题会持续伴随。“指标能算出来” 涵盖了两个方面:有值、准确,这中间不仅包括数据治理的问题,还包括指标管理和平台应用等诸多问题,我们细数常见的问题如下:
- 没有看数据的地方
- 能看到数据,但数据不准
- 验证数据准确,但不知道数据对应的口径是什么
- 同一指标不同平台看到的数据不一致
- 协调多个平台好不容易数据准确一致,新起个项目,所有事情重新来一遍
从产品的角度看,这些问题最主要的原因是没有一个统一且完整的指标平台,今天我们从指标平台的角度聊聊上面问题的解法。指标平台不同于报表平台,其关键在于与投放平台耦合,自动呈现各策略数据。可以分为四个环节:
……")
图1
每个环节都极为重要,本文我们重点聚焦前两个环节——“数据底座”部分,因为只有指标算出来,数据才有用武之地,数据驱动才有落地的可能。
一、简单说说指标
无论指标平台多么复杂,最终都会以指标的形态对外呈现,因此我们先梳理一下指标的逻辑,看如下需求描述:“企业运营人员投放一些经营策略,策略运行一段时间后需要分析效果,于是设计一些指标,并联系数据人员给出数据需求……”。从这一描述可以看出,指标与各个业务场景紧密耦合,随业务场景的变化指标形态也千变万化,列几个指标感受一下:
- “页面点击UV”
- “成单笔数”
- “页面浏览时长”
- “成单金额”
- “XX区域客户总账户余额”
- “XX活动达标率”
- “理财客户持仓金额年日均净增”
这其中既有与动作相关的事件类指标,也有与结果属性相关的状态类指标,我们把指标做一下拆分:
……")
图2
公式中四个元素的组合即为指标,通过这一公式我们重新描述一下上面的指标:
……")
表1
业务场景的梳理是为了让我们能更完整体系的看清指标的本质,从而抽象出共性,形成指标的底层逻辑,共性抽象的越完整,功能模块的适用性越强。在上面公式的基础上我们进一步细化指标逻辑:
……")
图3
上述过程协助我们充分理解指标逻辑、梳理指标应用场景和算法。那么,这些指标具体该如何通过平台落地呢?指标又如何定义和分类呢?我们再细细往下拆解……
二、指标平台逻辑
平台的构建是指标有效加工和计算的基础,因此,在详细介绍指标之前,我们先梳理一下指标平台的整体框架:
……")
图4
指标平台整体的结构可以分为如上五个模块:指标库、数据报告、计算引擎、底表模型、数据库(更多细致组件在这个图中暂不描述,可以依据各企业场景做调整)。这五个模块与上面的四个环节相对应,本文我们从数据报告说起,聊一聊底表模型和指标库的能力和特性:
1. 数据报告
数据报告是平台与业务人员交流的聚焦点,各种应用场景都体现在上面,结合不同业务场景,在数据报告中需要呈现的内容如下:
- 常用指标类型:事件类、当前值类状态指标、动态期初期末净增、固定期初期末净增、汇总值类、累加类六种类型。
- 常用数据表达方式:数据表格、趋势图(柱状图)、饼图三类。
- 数据分析四件套:客群选框、时间选框、指标选框、效果归因。
- 报告元数据:策略投放数据、信息变更记录、分析结论。
报告中指标数据主要分为趋势数据和整体数据,图形样式有如下两种表达方式:
……")
图5
不同角色的人在平台上看数据的视角也不相同:
- 企划/财务:聚焦不同时间段的投产比,因此会对固定期初期末净增值、趋势图有较强依赖
- 业务运营:聚焦上线策略的效果以及对自身经营任务的达成情况,因此对数据分析模块、动态期初期末净增类指标需求较高
- 平台产品:聚焦不同页面、渠道入口、广告位整体效果,如果有问题,可以追溯到具体策略,这一角色对事件类指标、固定期初期末净增、汇总值有较多需求
- 高层领导及财报审计等:会更关注当前业绩规模,因此会对当前值状态类指标、固定期初期末净增指标有较高关注
通过上面的描述,数据报告的支持模块至少应该涵盖:指标定义库、图表编辑器、归因功能模块和报告编辑看板,将这四块功能有效串联,实现数据的有效呈现:
……")
图6
2. 指标库
指标是指标平台的灵魂,指标库将指标配置的逻辑结构化,在指标平台中起到承上启下的作用,不仅能为上层平台提供分析所需的各种指标,更能通过指标计算评估数据治理的效果。
指标库的功能主要有:定义指标、组装SQL、将SQL下压到计算引擎、对外输出口径、对外输出计算结果。指标库中输出的指标包含:指标名称、指标ID、指标口径和指标计算结果四个元素,指标能在不同平台之间流转,确保各个平台之间指标口径一致且显性。
另外,添加指标的属性信息(例如:所属业务线、标签信息、所属经营任务等)则可以构建出指标标签体系,有效增加指标的扩展性且能协助业务线完成整体经营体系设计。
指标配置的结构化必然对底表数据结构有要求,因此我们在指标库中设计三个环节来规范底层数据结构,即:数据表管理、事件管理、指标设计,下文做一下详细介绍:
(1)数据表管理
数据表管理起到两个作用:一个是对能进入平台的表进行约束,另一个是进行表模型维护。从数据整体角度讲,这一功能是底层数仓的元数据管理模块,通过这一模块可以梳理出数仓中表的逻辑关系,数据表管理模块中主要维护的表模型有:单表模型、星状模型;
单表模型是最直观的建指标方式,用户只需要选择表对应事件,确定算子,选择这一表中的字段作为过滤规则,以此来确定指标口径,平台会依据这一口径拼装SQL,直接下压到计算引擎中计算,计算结果会返回到上层应用平台。
星状模型是在单表的基础上进行了一层扩展,在一个事实表的基础上关联多张维表,计算过程中能够通过维表筛选出更复杂/更完整的规则。星状模型如下:
……")
表2
在指标库表管理模块中需要将事实表与维表建立关联关系(以某一主键建立left join、right join、inner join等多种连接方式),关联关系建立后在指标设计的过滤规则中可以选到维表中的字段。
此处做一下备注:
- 由于雪花模型自身复杂性,设计成本较高,且雪花模型可以拆解成星状模型来应用,因此平台设计过程中暂时不考虑。
- 星状模型的引入会增加指标设计的复杂度,例如:维表中字段发生变化(千元户从0变成1);事实表跨日计算时是否需要关联最新维表;维表一般是全量表事实表多是增量表,两者之间有何关联规则等,由于本文是进行主流程梳理,细节不做过多描述)。
这一模块的页面形态如下:
……")
图7
数据显示逻辑有三种:
- 平台独立一个数据库:用到的表可以直接导入到这一库中,库中存在的表直接呈现在表管理页面中,这一方式在数据导入过程中需要在单表层面上做好清洗:确定主键、确定时间字段,数据导入库中后,再通过页面进行。
- 平台直接构建在统一数仓上:取数仓上的元数据信息统一呈现在这一页面模块,在页面上进行表分层分级管理,然后确定主键和时间字段,并关联其他维表,形成对应数据模型。
- 平台独立数据库,同时对接元数据平台:在页面上选择表元数据后,后台自动调起导数逻辑,表数据导入到平台数据库中,在平台页面上做分层分级管理,这一逻辑对页面形态有些调整,页面添加“表新增”功能,点击后可以录入表信息,如下:
……")
图8
完成表分层分级维护后,需要对表中内容进行规范和指定,例如:事件表可以指定事件,状态表可以指定统计时间等。
点击“状态”中的“属性”按钮,可以对表中字段进行维护:
……")
图9
点击“数值类型”下拉按钮可以选择“int/list/float/datetime/string”等类型,不同的类型在指标计算过程中要求不同,list类型不能进行“字典”上传,其他类型可以通过上传csv文件来维护字段内容。
(2)事件/时间管理
事件管理作为指标库的必须字段不仅涵盖事件类指标一种类型,状态类指标/汇总类指标也需要在这里做时间指定,两者指定的逻辑略有不同:
- 事件类指标模式:生产上直接流转下来的事件数据往往是单事件模型,即一条记录中只有一个动作、一个动作发生时间,但是在实际应用过程中,出于使用方便会以客户为主键,将多个事件整合到一张表中,形成多事件模型,在构建事件时能基于场景需要灵活指定事件时间。
- 状态/汇总时间类指标模式:多为用户属性信息,即一条记录中只有dt时间字段,没有用来表示用户动作发生的时间字段,因此在构建事件时将dt作为时间字段构建伪事件。
指定的事件会存储在事件管理模块,其页面样式如下:
……")
图10
在这里呈现的事件都能在指标设计过程中选得到。
(3)指标设计
经过前两个步骤的梳理,指标定义模块可以正常使用,这一模块的对应界面如下:
……")
图11
上面的指标设计页面中,我们可以看到指标的完整结构:事件名+算子+过滤规则(思考与上面指标表达式的区别),这一结构依赖于底层表模型,在页面上通过选择事件名、过滤规则来确定计算范围,通过不同算子来确定计算方式。
通过如上逻辑,我们可以组装出大部分指标样式,包括点击、成单、余额等。
三、指标分类和加工
介绍完指标库的整体结构,我们有了指标加工流水线,接下来详细介绍一下指标的分类和加工过程。
从流程角度我们梳理出指标对应的关系链如下:

图12
可以看到指标的基本形态有事件类指标和状态类指标,结合计算场景形成了净增类指标和累加类指标,共形成四种指标类型,我们逐一介绍:
1. 事件类型指标设计模型
事件类指标是指与客户动作发生相关的指标,例如:点击率、成单率,每个动作都会携带一个对应的时间,其数据结构主要为:

表3
这一类型的指标多为增量表(二次加工的多事件模型存在全量表),每天记录当天发生的行为,统计过程中需要用到的算子有count()、sum()、count(distinct……)三种类型,跨日期统计频次较高,每日趋势图、整体数据、不同时间段逻辑较容易梳理:
事件类增量表的表结构基本如下:
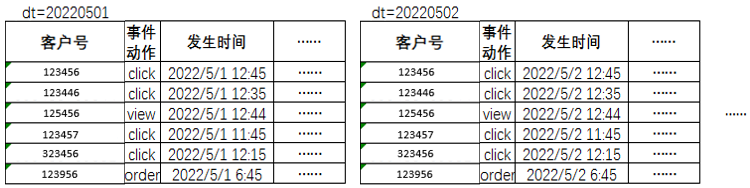
表4
指标的设计样式为:
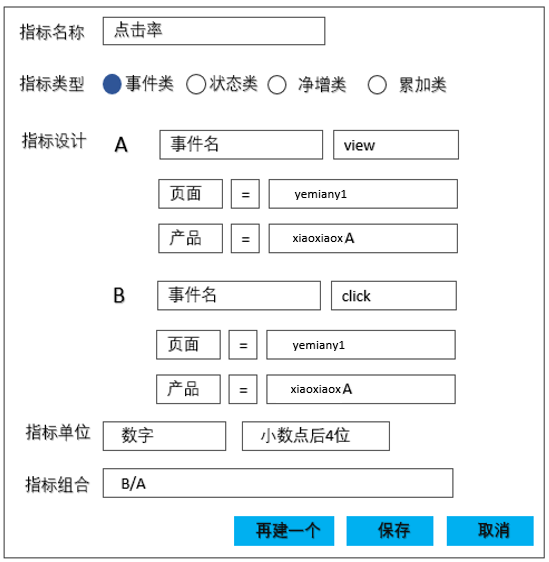
图13
在页面上填充“事件名、算子、过滤规则”、完善指标计算所需要的口径、同时在指标组合位置组装出指标的计算逻辑,即可完成指标定义过程。
在事件类指标的逻辑中,我们可以看出,上面三个模块的逻辑关系为:

图14
指标定义好后,我们该如何计算呢?
从表结构中可以明确有两种计算方式:增量表计算、全量表计算。
这两种计算的差异主要体现在统计范围的选择上:增量表计算需要跨多日汇总,而全量表计算只需要计算最新DT。
结合上面的逻辑关系我们可以得出如下两个逻辑:
其一:指标计算引用的如果是增量表:则统计范围以事件发生时间为标准,例如:统计10月3日~10月7日的点击UV,只需要按照事件发生时间进行数据圈选,如果是离线数据,则需要根据事件发生时间确定出对应的dt范围(事件日期==dt日期),然后在这一范围内进行相应指标计算。
SQL中对应的where条件描述如下:
- 整体数据为:“dt=between 事件开始日期 and 事件结束日期”
- 每日数据为:“dt=between 事件开始日期 and 事件结束日期 group by dt”
其二:指标计算引用的如果是全量表:则统计范围首先会选出最新dt,然后在最新dt数据表中基于事件发生时间圈选数据范围(事件日期包含在最新dt中),然后再计算对应指标。
SQL中对应的where条件描述如下:
- 整体数据为:“dt=max(dt)以及事件时间=between 事件开始时间 and 事件结束时间”
- 每日数据为:“dt=max(dt)以及事件时间=between 事件开始时间 and 事件结束时间 group by 事件日期”
结合指标设计过程中的过滤条件,我们就可以拼装出完整的SQL逻辑,将逻辑下压到计算引擎中即可得到对应的数据。
2. 状态类型指标设计模型
状态类指标通常用来描述用户最新的信息,分为余额类和属性类。
这一类指标有如下几个特点:
- 数据多存储在全量表中,每个dt记录全量用户的最新状态
- 表中通常没有用来记录动作的时间字段
- 数据存储以单表模型为主,表中信息定时刷新
例如:
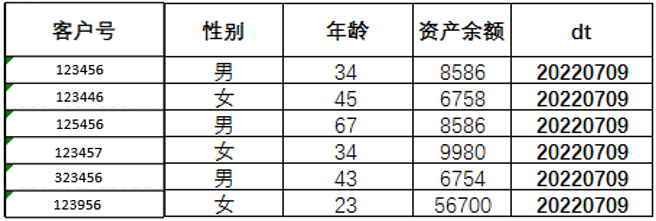
表5
这一类指标的页面配置逻辑为:
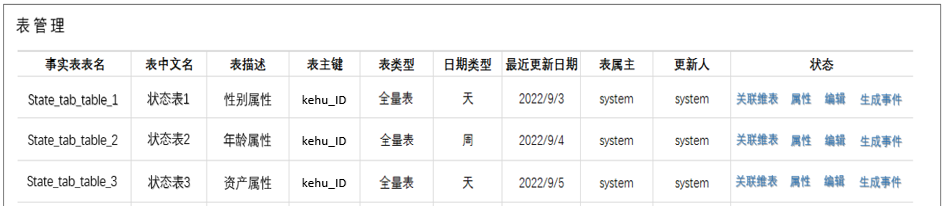
图15
将状态类明细表导入到平台数据库中,“表管理”页面中看到这一表信息后,将dt作为事件时间定义事件名称(事件日期==dt日期),这一事件对应的时间用来计算趋势图。
SQL中对应where条件描述如下:
- 整体数据为:“dt=max(事件日期)”
- 每日数据为:“dt=between 事件开始日期 and 事件结束日期 group by dt”

图16
此处定义的事件是以dt为时间创建,因此事件与表之间的对应关系为1:1。
定义好的事件可以直接用在指标定义环节:
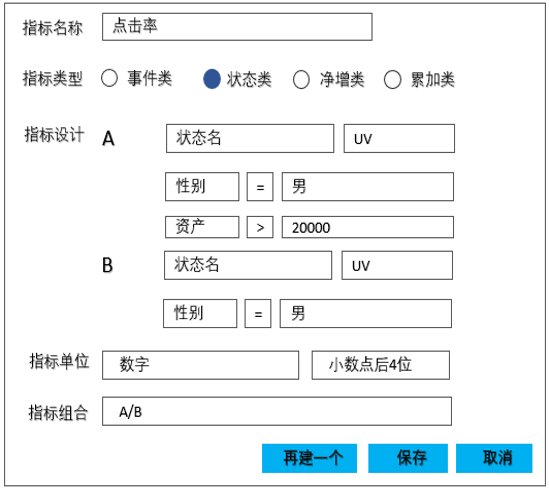
图17
此时,指标的对应关系变为:

图18
状态类指标中有两类小众的数据结构:
其一:为增量表状态指标,配置过程中与全量表状态指标类似,计算过程中存在一定差异。
SQL中对应where条件描述如下:
- 整体数据为:“dt= between 事件开始日期 and 事件结束日期”
- 每日数据为:“dt=between 事件开始日期 and 事件结束日期 group by dt”
其二:为月日均类指标,配置过程基于全量表完成,计算过程中跨多个dt,对应算子优化较为便捷。
SQL中对应描述如下:
- 整体数据为:“select sum(多dt对应字段)/count(多dt数量) …… where dt= between 事件开始日期 and 事件结束日期”
- 每日数据相对较为复杂,需要记录两个时间:其一是取均值时间段,其二是数据观察时间段,具体逻辑在下文中有专门描述
3. 净增类型指标设计模型
上面我们描述两类最常见的指标:状态类、事件类,这两类指标是平台应用中最常见的两类指标,逻辑处理相对简单,我们再回过头来看一下这个指标表达式:

图19
净增类指标在前两类指标的基础上深化了“时间”元素的应用场景:出现了“期末-期初”的逻辑。
梳理净增类指标的逻辑我们可以得出如下几种类型:
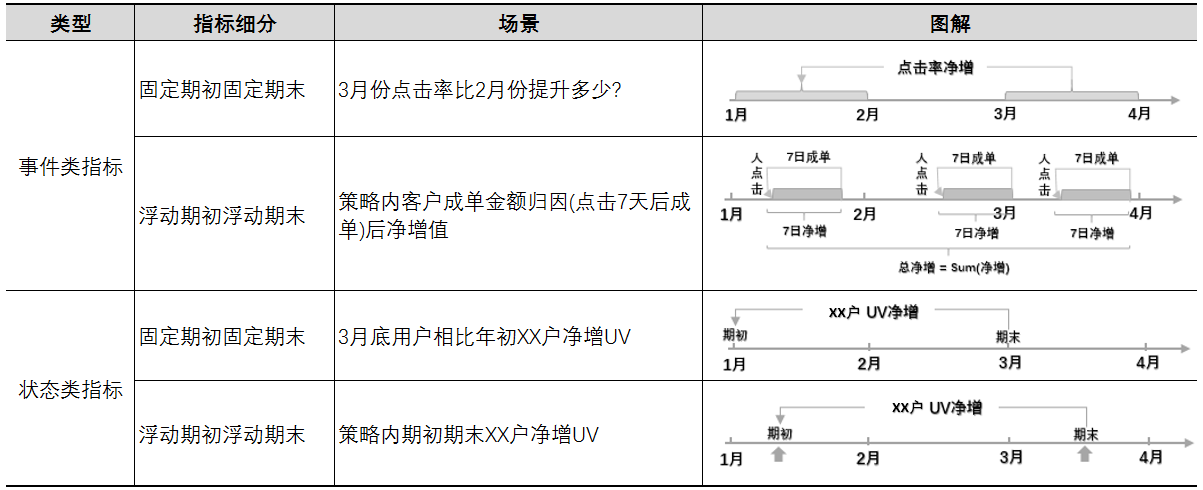
表6
这四种类型在指标设计上不需要对页面有太多调整,最直接的方式为优化算子,我们逐一做一下拆解:
(1)事件类固定期初期末净增
这一类指标有两个特点:
- 固定期初期末是从整体的角度衡量团队或部门的综合效果
- 事件类指标是通过圈选某个时间段,计算期间总量
最常见的指标为:活跃类的同环比指标;
最常用的部门为:企划/财务团队,用来定期衡量运营/业务团队的经营效果,运营/业务团队也会使用这一指标来衡量其整体经营效果;
最常见的统计时间为:期初是去年同月、今年1月份、上个月,期末是当月。
在这一逻辑下,表管理及事件管理模块没有变动,依然保持事件类表模型,在指标设计模块中最直接的调整方式为算子优化:
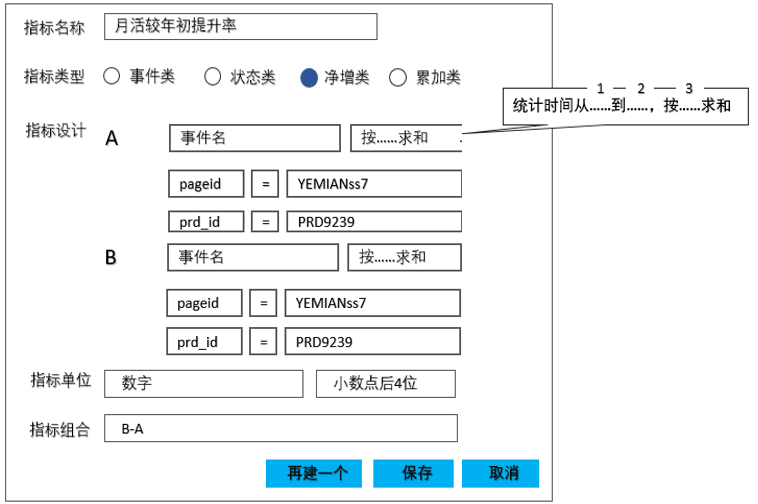
图20
选择净增类指标时,指标设计中默认呈现出A、B两个指标。
“统计时间从……到……,按……求和”这一算子可以作为净增类求和指标的计算逻辑,主要为了解决如下计算逻辑:

图21
- 点击算子的1号位置:弹出简化版的时间选框,选择期初的开始-结束时间
- 点击算子的2号位置:弹出简化版的时间选框,选择期末的开始-结束时间
- 点击算子的3号位置:求和算子是对数值型字段进行求和计算,点击弹出事件对应表中数值型字段(数值型字段可以在表管理界面中维护和修改)
- 净增类指标即为上面的方式计算两个值,然后计算差值,作为净增量
同类型的算子有另外两个:
- “统计时间从……到……,按……计数”
- “统计时间从……到……,按……去重计数”
指标设计中对应的SQL样式及指标组合公式为:
整体数据为:
- A:Select sum(3号位字段) …… where dt>=1号位中开始时间 and dt<=1号位中结束时间
- B:Select sum(3号位字段) …… where dt>=2号位中开始时间 and dt<=2号位中结束时间
- 计算净增:ins_data = B-A
每日数据是针对期初期末浮动的指标类型,日期增加一天,对应数值刷新一次,如果是期初期末固定的指标,对应的计算是一个值,对应不呈现每日数据,趋势图也不做数据呈现。
(2)事件类浮动期初期末净增
这一指标类型包含两种细分类型,对应的图形表达为:
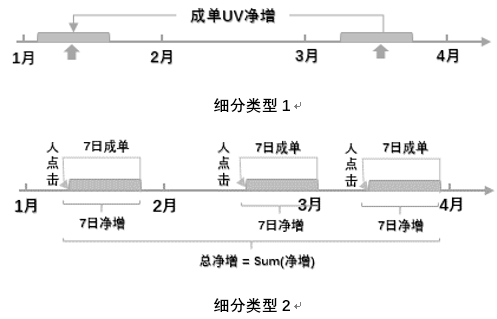
图22
对于细分类型1:
使用的算子可以做对应调整为:
- “统计时间从…
…向后统计…
…日,按……求和”
- 在1号位选择开始统计的日期,作为期初比较值
- 在2号位选择从开始日期向后统计N日,拼接出统计时间段t+N,后续随时间向后滑动
- 在3号位选择时间段中需要统计的字段,该字段为int和float类型
细分类型1中的配套算子为:
- “统计时间从…
…向后统计…
…日,按……计数”
- “统计时间从…
…向后统计…
…日,按……去重计数”
指标设计中对应的SQL样式及指标组合公式为:
- A最新值SQL为:select sum(3号位字段) …… where dt >= 期初1号位日期 and dt <= 期初1号位日期+2号位数值
- B最新值SQL为:select sum(3号位字段) …… where dt >= 期末1号位日期 and dt <= 期末1号位日期+2号位数值
- 最新值净增为:B-A
- A每日值SQL为:select sum(3号位字段) …… where dt >= 期初1号位日期 and dt <= 期初1号位日期+2号位数值 group by 1号位日期
- B每日值SQL为:select sum(3号位字段) …… where dt >= 期末1号位日期 and dt <= 期末1号位日期+2号位数值 group by 1号位日期
- 每日值净增为:B-A
对于细分类型2:
使用场景有一些变动,例如:在某一策略中统计某个人点击后7天的成单情况,由于策略中人数不固定,因此统计t+N的数量不固定,无法使用细分类型1中的算子计算,因此新增几个算子如下:
“基于事件向后统计… …日,按… …求和”。
这一算子的统计逻辑为:
- 在事件类型指标设计过程中,首先会选择一个事件,在这一事件的基础上向后统计N日,按照2号位的字段求和
- 2号位字段对应也是一个事件,如果事件发生时间在1号位约束时间范围内,则按照3号位字段计算,如果不在则不做计算
细分类型2中的配套算子为:
- “基于事件向后统计…
…日,按…
…事件……计数”
- “基于事件向后统计…
…日,按…
…事件……去重计数”
由于这一逻辑较为复杂,因此我们梳理事件对应的表结构为:
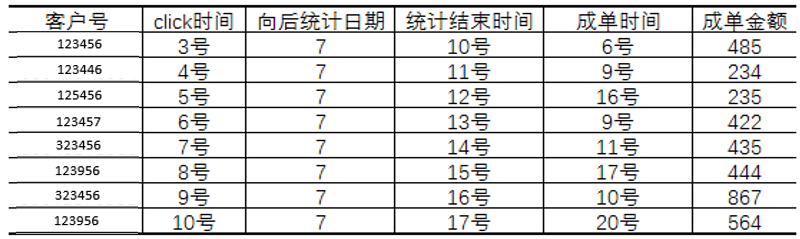
表7
指标设计中对应的SQL样式及指标组合公式为:
- A最新值SQL为:select sum(case when 成单时间 >= click时间 and 成单时间 <= 统计结束时间 then 成单金额 else 0 end) …… where dt >= 期初1号位事件最新发生日期 and dt <= 期初1号位事件最新发生日期+2号位数值
- B最新值SQL为:select sum(case when 成单时间 >= click时间 and 成单时间 <= 统计结束时间 then 成单金额 else 0 end) …… where dt >= 期末1号位事件最新发生日期 and dt <= 期末1号位事件最新发生日期+2号位数值
- 最新值净增为:B-A
- A每日值SQL为:select sum(case when 成单时间 >= click时间 and 成单时间 <= 统计结束时间 then 成单金额 else 0 end) …… where dt >= 期初1号位事件发生日期 and dt <= 期初1号位事件发生日期+2号位数值 group by 1号位事件发生日期
- B每日值SQL为:select sum(case when 成单时间 >= click时间 and 成单时间 <= 统计结束时间 then 成单金额 else 0 end) …… where dt >= 期末1号位事件发生日期 and dt <= 期末1号位事件发生日期+2号位数值 group by 1号位事件发生日期
- 每日值净增为:B-A
如上两种场景是在事件类表的场景下进行计算,如果整个表中没有事件发生时间,只有dt字段,则不适合用上面算子计算。
(3)状态类固定期初期末净增
这一类型的指标也包含两种细分类型,对应的图形表达为:

图23
细分类型1主要是获取期初和期末两个dt,其计算特点为:
- 固定选择两个dt,作为计算的数据基础
- 两个dt各自求和,然后做净增计算
对应的算子有:
- “基于时间…
…,按…
…求和” - 在1号位置选择需要计算的时间,后续所有的计算都是在这个dt的基础上进行
- 在2号位置选择参与计算的字段,算子针对这一字段求和
指标设计中对应的SQL样式及指标组合公式为:
- A期初值SQL为:select sum(2号位字段) …… where dt = 1号位时间
- B期末最新值SQL为:select sum(2号位字段) …… where dt = 1号位时间
- 对应的净增值为:B-A
在固定期初类指标中,每日净增的计算只需要依照加挂策略的开始时间,然后每天计算净增值,得到每日提升值。
配套算子有如下两个:
- “基于时间…
…,按…
…计数” - “基于时间…
…,按…
…去重计数”
细分类型2主要是在状态类指标中跨dt计算,由于每个dt中都存储了全量的数据,因此跨dt计算能进行求均值、最值等。
时间段指标统计也存在两个思路:滑动N日、按照自然月。
滑动N日:期初是个相对固定的值,期末数据每日向后滑动,每日计算过去30日均值;
日期滑动需要有一个相对变量,即当下日期的时间表示为{yyyyMMdd},滑动逻辑统一用这一字段做加减计算,例如:过去30日滑动为“{yyyyMMdd-30d}-{yyyyMMdd}”,对应算子为:
- “统计时间从…
…到…
…,按……单日求和取均值”
- “统计时间从…
…到…
…,按……单日求和取最大值”
- “统计时间从…
…到…
…,按……单日求和取最小值”
- “统计时间从…
…到…
…,按……单日计数取均值”
- “统计时间从…
…到…
…,按……单日计数取最大值”
- “统计时间从…
…到…
…,按……单日计数取最小值”
- “统计时间从…
…到…
…,按……单日去重计数取均值”
- “统计时间从…
…到…
…,按……单日去重计数取最大值”
- “统计时间从…
…到…
…,按……单日去重计数取最小值”
这一计算方式每天都有一次计算,对应趋势图为每日数值。
按照自然月:则需要对上面算子中时间值进行特殊处理,能够选到每月月初时间{yyyyMMdd -start M}。
(4)状态类浮动期初期末净增:
浮动期初期末对应的指标类型与上文固定期初期末指标类型相似,不同点在于期初期末的时间是可以变动的,此时只需要在算子中灵活应用“{yyyyMMdd -start M}”、“{yyyyMMdd -Nd}”、“向后N日”三个时间变量即可,上面三个场景完整覆盖的情况下,这一场景也可以得到保障,此处不做赘述。
4. 累加类型指标设计模型
上文我们详细描述了净增类指标的各个场景,复杂度相对较高,不过也正因为这样的复杂度才能帮助我们更有效的提升算子的适配能力。
在这一环节中,我们介绍最后一种类型的指标,即:累加型指标。
这一指标的特点是每天的数据都来自于昨天数据与今天新增数据,逐日累加,在每个最新的dt中包含全量数据。
累加类指标的适用范围较小,其最直接的价值在于减少性能压力,每次计算都使用最新dt中的数据,这一类型的计算主要有两种处理方式:
- 在数据库中直接处理成累全量表,然后在指标设计过程中采用状态类指标方式计算。
- 在数据库中存储最原始的两类表:增量表、全量表,然后在指标设计的算子中增加类全量类型的算子。
此处我们重点介绍一下第二种方式:
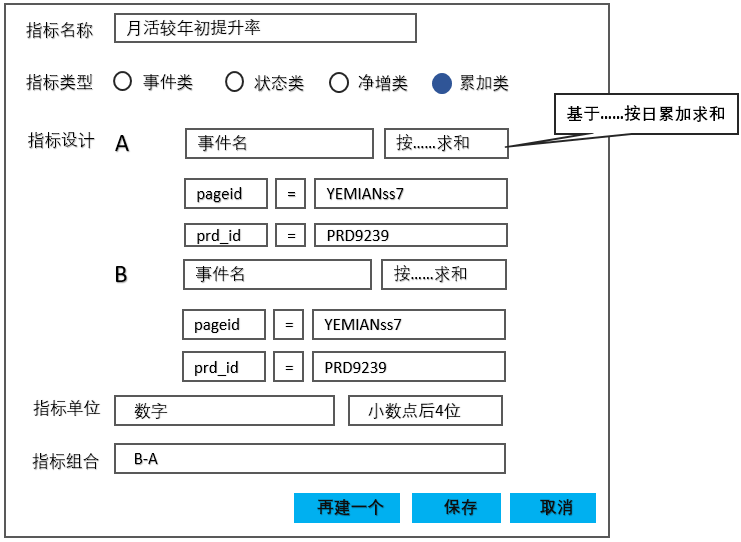
图24
累加逻辑按照数值类型可以有如下几种:订单金额类(求和/求均值)、0-1与或类(与或计算)、客户量类(计数/去重计数)等。
按照一定的逻辑将数值汇总到最新dt中,后续的统计全按照最新dt计算,整体逻辑相对简单,不过数据处理起来需要有一些前置工作,以“基于…
…按日累加求和”算子为例:
第一步:数据累加:
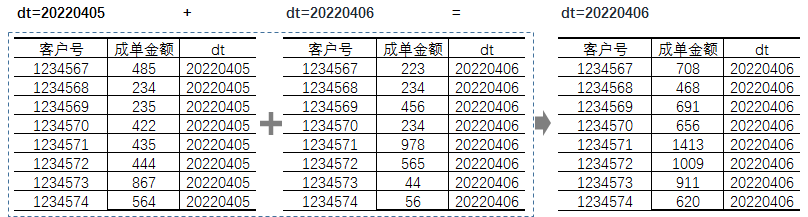
表8
第二步:按照最新dt计算指标:
- 对应的SQL为:select sum(1号位字段) …… where dt = 最新日期
- 每日数据则为:select sum(1号位字段) …… where dt >= 策略生效日期 group by dt
除累加求和外,相关算子还有:
- “基于…
…按日累加求均值”
- “基于…
…按日累加求最大值”
- “基于…
…按日累加求最小值”
- “基于…
…按月累加求均值”
- “基于…
…按月累加求最大值”
- “基于…
…按日累加求最小值”
……
四、后记
文章写到这里算是告一段落,在这篇文章中我们梳理了指标的加工流水线——指标库,并在流水线的基础上梳理指标的分类和加工过程。两条链路相互协同下,指标计算结果可以快速输出,同时输出指标的口径和属主,数据使用人员能够明明白白使用指标,随着指标库中指标的累积和使用规范的完善,企业中看数据的问题会逐渐减少,不过对于平台性能的压力需要做一些权衡。
构建完整的数据底座是数据驱动的根基,根基稳则驱动强,根基不稳则寸步难行。下一篇文章我们继续梳理后两个环节,在强有力的数据底座上,首先要做的就是要梳理出能让业务看得懂的报告:《数据报告最重要的是让业务看得懂……》,欢迎大家讨论~
为我投票
我在参加评选,希望喜欢我的文章的朋友都能来支持我一下~
点击下方链接进入我的个人参选页面,点击红心即可为我投票。
每人每天最多可投35票,投票即可获得抽奖机会,抽取书籍、
野水晶体,微信公众号:livandata。金融行业的互联网老兵,聚焦数据驱动,将算法、数据融入产品设计与运营策略,构建金融增长方法论。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
