如何利用大模型获取用户数据,提升数字化营销效果
在数字化营销的领域,用户数据是一种非常宝贵的资源,它可以帮助我们了解用户的需求、偏好、行为和反馈,从而优化我们的产品设计、广告投放和用户增长策略。但是,如何有效地获取用户数据呢?传统的方法往往是通过人工的方式,比如设置问卷、访谈、调研等,来收集用户的意见和反馈。这种方法虽然可以获得一些有价值的数据,但是也有很多局限性,比如数据量小、数据质量低、数据更新慢、数据分析难等。随着人工智能技术的发展,特别是大模型的出现,我们有了一个更好的选择,那就是利用大模型来获取用户数据。
一、什么是大模型
大模型是指那些具有超大规模的人工智能模型,它们通常拥有数十亿甚至数万亿的参数,可以处理海量的数据,学习各种复杂的任务,生成各种有用的内容。大模型的代表有GPT-3、BERT、DALL-E等,它们在自然语言处理、计算机视觉、自然语言生成等领域都取得了令人惊叹的成果。大模型的优势在于它们可以利用大量的数据,从中提取出有价值的信息,生成出有用的内容,从而为我们提供更好的服务和体验。
二、大模型如何获取用户数据
大模型获取用户数据的方式主要有两种,一种是主动获取,一种是被动获取。主动获取是指我们利用大模型主动向用户提出问题,收集用户的回答,从而获得用户的数据。被动获取是指我们利用大模型监测和分析用户的行为,从而获得用户的数据。这两种方式都有各自的优缺点,我们可以根据不同的场景和目的,灵活地选择和结合使用。
1. 主动获取
主动获取的方式是比较直接和简单的,我们可以利用大模型来设计和生成一些问题,比如用户满意度调查、用户需求分析、用户反馈收集等,然后通过各种渠道。比如网站、社交媒体、电子邮件、短信等,向用户发送这些问题,收集用户的回答,从而获得用户的数据。这种方式的好处是可以获得一些比较明确和具体的数据,比如用户的评分、意见、建议等,这些数据可以帮助我们更好地了解用户的满意度、需求、问题等,从而改进我们的产品和服务。这种方式的缺点是需要用户的主动参与和配合,如果用户不愿意回答问题,或者回答不真实、不完整、不准确,那么我们就无法获得有效的数据,甚至会造成数据的偏差和误导。
为了提高用户回答问题的意愿和质量,我们可以利用大模型的一些特性,比如:
- 利用大模型的自然语言生成能力,生成一些有趣和吸引人的问题,比如用幽默、诙谐、奇思妙想等方式提问,或者用一些有趣的图片、视频、音频等素材辅助提问,从而激发用户的兴趣和好奇心,增加用户的参与度和互动性。
- 利用大模型的自然语言理解能力,分析用户的回答,给出一些合适的反馈,比如用赞扬、鼓励、感谢等方式回复,或者用一些有用的信息、建议、奖励等方式回复,从而增强用户的信任和满意度,提高用户的忠诚度和留存率。
- 利用大模型的自然语言适应能力,根据用户的特征,比如年龄、性别、地域、兴趣等,定制一些适合的问题,比如用不同的语言、风格、话题等方式提问,或者用不同的形式、难度、长度等方式提问,从而增加用户的舒适度和认同感,提高用户的回答质量和准确度。
2. 被动获取
被动获取的方式是比较间接和隐蔽的,我们可以利用大模型来监测和分析用户的行为,比如用户在网站上的浏览、点击、搜索、购买等行为,或者用户在社交媒体上的关注、点赞、评论、分享等行为,或者用户在实体店里的进入、停留、试用、购买等行为,从而获得用户的数据。这种方式的好处是可以获得一些比较隐性和深层的数据,比如用户的兴趣、偏好、习惯、动机等,这些数据可以帮助我们更好地了解用户的心理和行为,从而优化我们的产品和服务。这种方式的缺点是需要用户的隐私和安全,如果用户不知道或不同意我们收集和分析他们的行为数据,或者我们没有合理和合法地使用和保护这些数据,那么我们就可能会侵犯用户的权益,甚至会引起用户的反感和抵制。
为了保障用户的隐私和安全,我们可以利用大模型的一些特性,比如:
- 利用大模型的自然语言生成能力,生成一些清晰和友好的隐私政策,比如用简单、明确、透明的语言说明我们收集和使用用户数据的目的、方式、范围、期限等,或者用一些图表、示例、FAQ等方式说明我们如何保护和尊重用户数据的安全、完整、可控等,从而增加用户的了解和信任,获得用户的同意和支持。
- 利用大模型的自然语言理解能力,分析用户的反馈,给出一些合理的回应,比如用解释、道歉、改进等方式回复,或者用一些补偿、赔偿、赔礼等方式回复,从而减少用户的不满和抱怨,提高用户的宽容和谅解。
- 利用大模型的自然语言适应能力,根据用户的特征,比如敏感度、风险度、安全度等,调整一些合适的参数,比如收集和使用用户数据的频率、程度、范围等,或者提供和保留用户数据的选项、权限、期限等,从而增加用户的安全感和控制感,提高用户的隐私和安全。
三、数据来源
大模型获取用户数据的来源主要有两种,一种是线上数据,一种是线下数据。线上数据是指用户在互联网上的各种活动产生的数据,比如用户在网站上的浏览、点击、搜索、购买等行为,或者用户在社交媒体上的关注、点赞、评论、分享等行为,或者用户在电商平台上的浏览、收藏、加购、下单等行为。线下数据是指用户在现实世界中的各种活动产生的数据,比如用户在实体店里的进入、停留、试用、购买等行为,或者用户通过调查问卷、电话访谈、面对面交流等方式提供的数据。这两种数据都有各自的优缺点,我们可以根据不同的场景和目的,灵活地选择和结合使用。
1. 线上数据
线上数据的优点是数据量大、数据质量高、数据更新快、数据分析易。因为用户在互联网上的活动是可以被记录和追踪的,我们可以利用各种工具,比如网站分析、社交媒体分析、电商分析等,来收集和分析用户的线上数据,从而获得一些有价值的信息,比如用户的访问量、访问时长、访问路径、访问来源、访问设备、访问频率、访问偏好、访问目的、访问结果等。这些信息可以帮助我们了解用户的行为特征,比如用户是如何找到我们的产品或服务的,用户是如何使用我们的产品或服务的,用户是如何评价我们的产品或服务的,用户是如何转化为我们的客户或粉丝的,用户是如何推荐我们的产品或服务给其他人的等。这些信息可以帮助我们优化我们的产品或服务的设计、功能、内容、交互、体验等,从而提高用户的满意度、忠诚度、留存率、转化率、推荐率等,最终提升我们的数字化营销效果。
线上数据的缺点是数据隐私低、数据安全差、数据竞争激、数据分散多。因为用户在互联网上的活动是可以被记录和追踪的,我们也要面对一些风险和挑战,比如用户的隐私可能被泄露或滥用,用户的数据可能被窃取或破坏,用户的数据可能被竞争对手或恶意者利用或干扰,用户的数据可能分散在不同的平台或渠道,难以整合或统一等。这些风险和挑战可能会影响用户的信任和安全感,影响用户的参与和合作,影响用户的数据的真实性和有效性,影响我们的数据的收集和分析,最终影响我们的数字化营销效果。
为了克服线上数据的缺点,我们可以利用大模型的一些特性,比如:
- 利用大模型的自然语言生成能力,生成一些清晰和友好的隐私政策,比如用简单、明确、透明的语言说明我们收集和使用用户数据的目的、方式、范围、期限等,或者用一些图表、示例、FAQ等方式说明我们如何保护和尊重用户数据的安全、完整、可控等,从而增加用户的了解和信任,获得用户的同意和支持。
- 利用大模型的自然语言理解能力,分析用户的反馈,给出一些合理的回应,比如用解释、道歉、改进等方式回复,或者用一些补偿、赔偿、赔礼等方式回复,从而减少用户的不满和抱怨,提高用户的宽容和谅解。
- 利用大模型的自然语言适应能力,根据用户的特征,比如敏感度、风险度、安全度等,调整一些合适的参数,比如收集和使用用户数据的频率、程度、范围等,或者提供和保留用户数据的选项、权限、期限等,从而增加用户的安全感和控制感,提高用户的隐私和安全。
- 利用大模型的自然语言融合能力,将不同来源的线上数据融合在一起,比如将网站数据、社交媒体数据、电商平台数据等整合在一起,从而构建一个完整和全面的用户画像,比如用户的基本信息、兴趣爱好、消费习惯、购买意向、购买行为、购买结果等,从而提高用户数据的价值和效果。
2. 线下数据
线下数据的优点是数据真实性高、数据深度大、数据覆盖广、数据互动强。因为用户在现实世界中的活动是可以被观察和体验的,我们可以利用各种工具,比如实体店分析、调查问卷分析、电话访谈分析等,来收集和分析用户的线下数据,从而获得一些有价值的信息,比如用户的到店量、到店时长、到店路径、到店来源、到店设备、到店频率、到店偏好、到店目的、到店结果等。这些信息可以帮助我们了解用户的行为特征,比如用户是如何找到我们的实体店的,用户是如何在我们的实体店里体验我们的产品或服务的,用户是如何评价我们的实体店的,用户是如何转化为我们的客户或粉丝的,用户是如何推荐我们的实体店给其他人的等。这些信息可以帮助我们优化我们的实体店的设计、功能、内容、交互、体验等,从而提高用户的满意度、忠诚度、留存率、转化率、推荐率等,最终提升我们的数字化营销效果。
线下数据的缺点是数据量小、数据质量低、数据更新慢、数据分析难。因为用户在现实世界中的活动是有限和变化的,我们也要面对一些困难和挑战,比如用户的到店可能受到时间、地点、天气、交通等因素的影响,用户的体验可能受到心情、环境、人群等因素的影响,用户的评价可能受到情绪、态度、偏见等因素的影响,用户的数据可能难以收集和记录,难以整理和分析,难以更新和跟踪等。这些困难和挑战可能会影响用户的参与和合作,影响用户的数据的真实性和有效性,影响我们的数据的收集和分析,最终影响我们的数字化营销效果。
为了克服线下数据的缺点,我们可以利用大模型的一些特性,比如:
- 利用大模型的自然语言生成能力,生成一些有趣和吸引人的问题,比如用幽默、诙谐、奇思妙想等方式提问,或者用一些有趣的图片、视频、音频等素材辅助提问,从而激发用户的兴趣和好奇心,增加用户的参与度和互动性。
- 利用大模型的自然语言理解能力,分析用户的回答,给出一些合适的反馈,比如用赞扬、鼓励、感谢等方式回复,或者用一些有用的信息、建议、奖励等方式回复,从而增强用户的信任和满意度,提高用户的忠诚度和留存率。
- 利用大模型的自然语言适应能力,根据用户的特征,比如年龄、性别、地域、兴趣等,定制一些适合的问题,比如用不同的语言、风格、话题等方式提问,或者用不同的形式、难度、长度等方式提问,从而增加用户的舒适度和认同感,提高用户的回答质量和准确度。
四、数据处理
大模型获取用户数据后,还需要对用户数据进行一些处理,比如数据清洗、数据整合、数据分析等,从而提高用户数据的质量和价值,为我们的数字化营销提供更好的支持和指导。
1. 数据清洗
数据清洗是指对用户数据进行一些预处理,比如去除重复数据、缺失值处理、异常值处理等,从而提高用户数据的准确性和有效性。数据清洗的目的是为了消除用户数据中的一些噪音和干扰,比如用户的误操作、错误输入、恶意填写等,从而使用户数据更真实和可信。
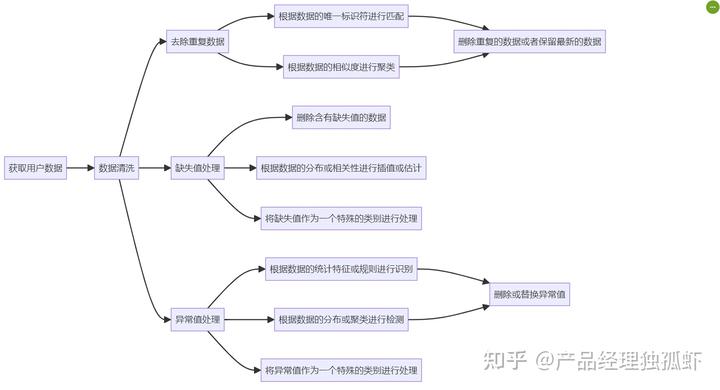
数据清洗的方法有很多,比如:
- 去除重复数据:重复数据是指用户数据中存在两条或多条相同或相似的数据,比如用户多次回答同一个问题,或者用户在不同的平台或渠道提供同样的信息等。重复数据会影响用户数据的统计和分析,造成数据的冗余和偏差。去除重复数据的方法是通过比较用户数据的内容、来源、时间等,找出并删除重复的数据,只保留一条最新或最完整的数据。
- 缺失值处理:缺失值是指用户数据中存在一些空缺或未填写的数据,比如用户没有回答某个问题,或者用户没有提供某些信息等。缺失值会影响用户数据的完整性和可用性,造成数据的不足和损失。缺失值处理的方法是通过补充或删除缺失的数据,使用户数据更完整或更简洁。补充缺失的数据的方法是通过推测或询问用户,填补缺失的数据,比如利用大模型的自然语言生成能力,生成一些合理的默认值或提示语,引导用户补充缺失的数据。删除缺失的数据的方法是通过筛选或忽略用户,删除缺失的数据,比如利用大模型的自然语言理解能力,分析用户的回答质量,筛选出或忽略掉那些缺失数据过多或过少的用户。
- 异常值处理:异常值是指用户数据中存在一些不符合正常规律或逻辑的数据,比如用户的回答过于极端、不一致、不合理等。异常值会影响用户数据的合理性和可信性,造成数据的误差和偏离。异常值处理的方法是通过检测或纠正异常的数据,使用户数据更合理或更一致。检测异常的数据的方法是通过比较或分析用户数据,找出并标记异常的数据,比如利用大模型的自然语言理解能力,分析用户的回答内容,找出并标记那些与其他用户或自身不一致或不合理的回答。纠正异常的数据的方法是通过修改或替换异常的数据,使用户数据更正常或更平均。修改异常的数据的方法是通过调整或修正异常的数据,使用户数据更接近正常的范围或逻辑,比如利用大模型的自然语言生成能力,生成一些合适的修改或修正语,引导用户修改或修正异常的数据。替换异常的数据的方法是通过删除或插入异常的数据,使用户数据更符合正常的分布或趋势,比如利用大模型的自然语言生成能力,生成一些合适的修改或修正语,引导用户修改或修正异常的数据。替换异常的数据的方法是通过删除或插入异常的数据,使用户数据更符合正常的分布或趋势,比如利用大模型的自然语言生成能力,生成一些合理的删除或插入语,引导用户删除或插入异常的数据。
2. 数据整合
数据整合是指对用户数据进行一些后处理,比如将不同来源的数据整合在一起,构建用户画像等,从而提高用户数据的完整性和价值。数据整合的目的是为了形成一个全面和统一的用户视角,比如用户的基本信息、兴趣爱好、消费习惯、购买意向、购买行为、购买结果等,从而使用户数据更有用和有意义。
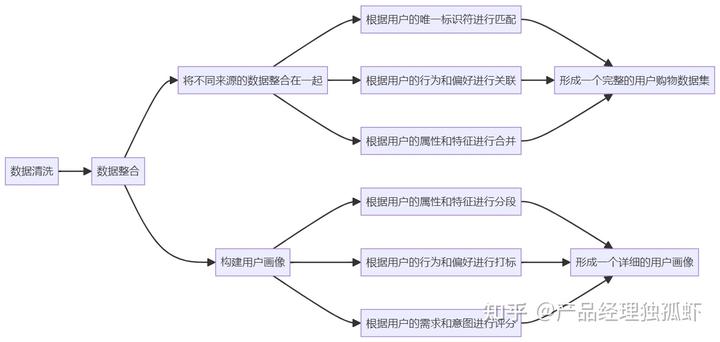
数据整合的方法有很多,比如:
- 将不同来源的数据整合在一起:不同来源的数据是指用户数据来自于不同的平台或渠道,比如线上数据和线下数据,或者网站数据、社交媒体数据、电商平台数据、实体店数据等。不同来源的数据可能有不同的格式、结构、内容、质量等,需要进行一些转换、匹配、对齐、补充等,才能整合在一起。将不同来源的数据整合在一起的方法是通过利用大模型的自然语言融合能力,将不同格式、结构、内容、质量的数据融合在一起,形成一个统一和标准的数据集,比如利用大模型的自然语言生成能力,生成一些转换、匹配、对齐、补充语,引导用户将不同来源的数据整合在一起。
- 构建用户画像:用户画像是指对用户数据进行一些分析和归纳,形成一个具有代表性和特征性的用户模型,比如用户的性别、年龄、地域、职业、教育、收入、家庭、兴趣、偏好、需求、问题、目标、动机、行为、反馈、评价等。用户画像可以帮助我们更好地了解用户的特点和需求,从而为用户提供更个性化和定制化的产品和服务。构建用户画像的方法是通过利用大模型的自然语言分析能力,对用户数据进行一些分类、聚类、关联、推断等,形成一个有层次和有逻辑的用户模型,比如利用大模型的自然语言生成能力,生成一些分类、聚类、关联、推断语,引导用户构建用户画像。
五、大模型在数据收集中的作用
大模型在数据收集中的作用是非常重要和显著的,它可以帮助我们获取更多、更好、更有用的用户数据,从而为我们的数字化营销提供更强大的支持和指导。大模型在数据收集中的作用主要体现在以下几个方面:
- 大模型对大量数据的处理能力:大模型可以处理海量的数据,从中提取出有价值的信息,生成出有用的内容,从而为我们提供更多的用户数据,比如用户的行为数据、反馈数据、评价数据等。这些数据可以帮助我们了解用户的需求、偏好、行为和反馈,从而优化我们的产品设计、广告投放和用户增长策略。
- 大模型对多源数据的融合能力:大模型可以融合不同来源的数据,从中构建出完整和全面的用户画像,从而为我们提供更好的用户数据,比如用户的基本信息、兴趣爱好、消费习惯、购买意向、购买行为、购买结果等。这些数据可以帮助我们更好地了解用户的特点和需求,从而为用户提供更个性化和定制化的产品和服务。
- 大模型对复杂数据的分析能力:大模型可以分析复杂的数据,从中发现出有意义的规律和趋势,从而为我们提供更有用的用户数据,比如用户的分类、聚类、关联、推断等。这些数据可以帮助我们更好地了解用户的心理和行为,从而优化我们的产品和服务。
六、总结
在本文中,我们介绍了大模型如何获取用户数据,提升数字化营销效果的方法和步骤,包括:
- 大模型获取用户数据的方式,主要有主动获取和被动获取两种,我们可以根据不同的场景和目的,灵活地选择和结合使用。
- 大模型获取用户数据的来源,主要有线上数据和线下数据两种,我们可以根据不同的场景和目的,灵活地选择和结合使用。
- 大模型获取用户数据后,还需要对用户数据进行一些处理,比如数据清洗、数据整合、数据分析等,从而提高用户数据的质量和价值,为我们的数字化营销提供更好的支持和指导。
- 大模型在数据收集中的作用是非常重要和显著的,它可以帮助我们获取更多、更好、更有用的用户数据,从而为我们的数字化营销提供更强大的支持和指导。
- 数据安全是指对用户数据进行一些保护和尊重,比如遵守数据保护法规、加密传输和存储数据、限制数据访问权限等,从而保障用户数据的安全、完整、可控。
希望这篇文章能对你有所帮助。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
