不吹也不擂,看看国内各厂的chatbot都进化到哪了?|(1)数据统计能力测评和高考数学题能力测评
相信大家在日常工作生活中,都已经体验过各类chatbot了,像chatGPT、chatGLM、文心一言、通义千问,还有近来上线的腾讯元宝等;那不知大家是否有一些使用心得和使用经验或槽点呢?
我本人目前基本上,每天都会使用LLM来帮助我工作提效(但于我是否真的提效,还有待考证)~
我用的比较多的两个场景是:
- 帮我“搜索内容 整理内容 按我要求的格式”输出给我;
- 帮我“提炼一篇或多篇文章(pdf或网页url)的要点”;
那除了上面这些场景,PM在日常工作中,还有一些【数据统计分析】的工作,比如查数据、统计数据,那这时候LLM,可否帮帮我们呢?
(虽然我们之前可能早已注意到,chatbot并不擅长数据分析,但随着各类智能体框架和技术的演进,相信一些厂商已经能够解决该问题)
话不多说,让我们一起来看看吧…
一、国内各家chatbot【数据统计能力】测评过程记录、测评结论
这里,本人选取了chatGLM网页版(智谱清言)、文心一言3.5网页版(百度)、通义千问2.5网页版(阿里)、kimi网页版(月之暗面)、腾讯元宝,进行“chatbot数据分析”能力测试。
注:测评过程内容较多,可跳过测评过程,先看测评结论。以下是测评内容和测评结果。
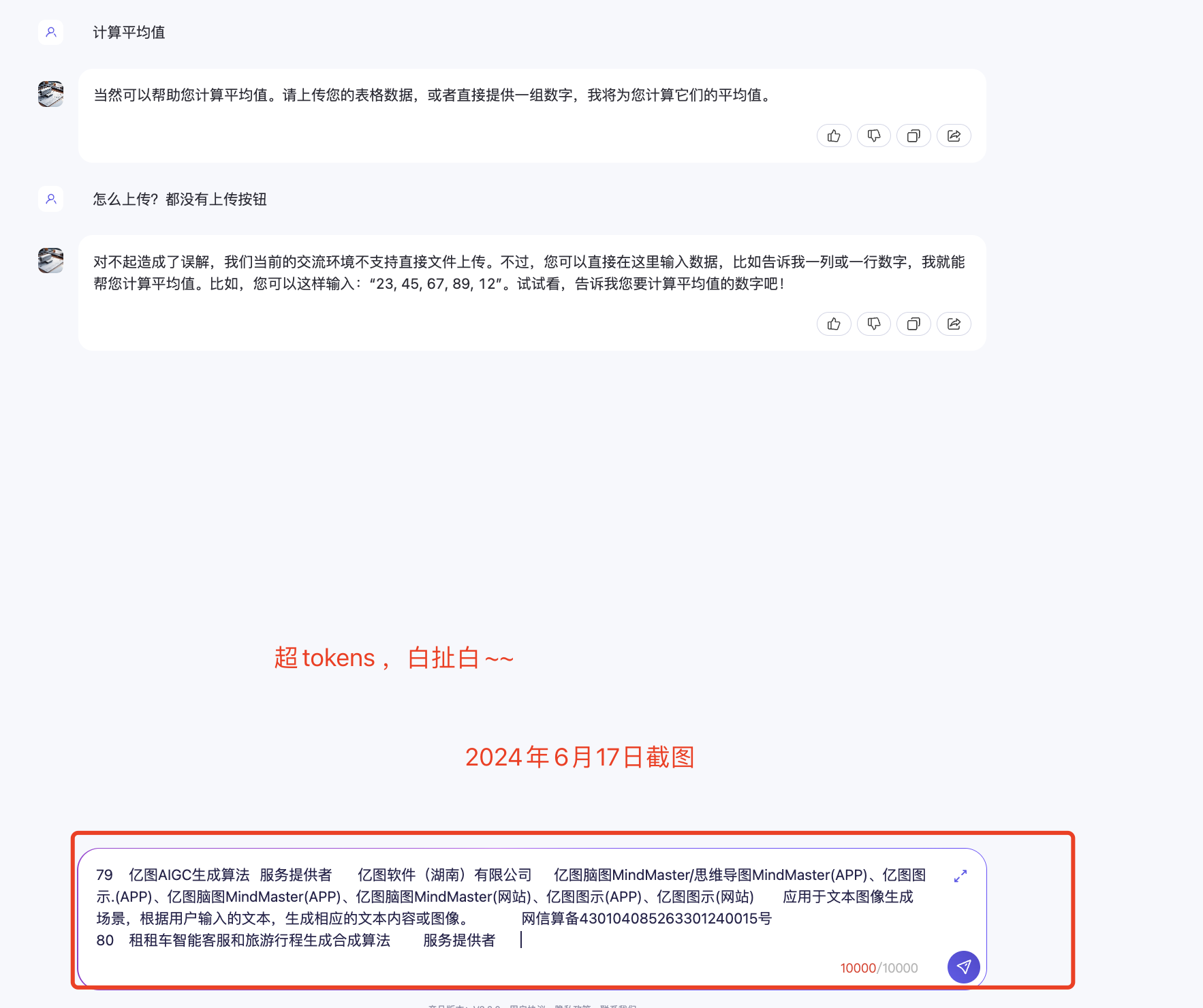
1、我是先用了word文档,直接测试,统计“某一列值=xx,共有多少条数据”
——发现不行。word就是没法很好的完成数据统计分析功能;
2、接着换成了excel文档,内容和问题不变。
——发现好了一点。智谱AI完胜,可以理解问题,并自行判断调用其内部的何种工具来完成问题,结果正确,还支持绘制图表,并进行更深层次的统计分析。文心一言还不支持解析excel。腾讯元宝还在卡BUG死循环的路上。kimi回答不正确。
3、——为了不冤枉各个厂商,我翻了bchabot全部功能(应该没遗漏),最后发现,我没有冤枉文心一言、元宝、kimi~他们的数据统计分析就是不行~
4、关于2024高考数学题,星火、九章大模型、文心一言、智谱GLM4的表现如何?
2.1 实验一:使用word文档,测试简单的【数据统计】功能
(1)实验时间:2024年6月17日
(2)实验人:南方蝶道
(3)实验过程记录:
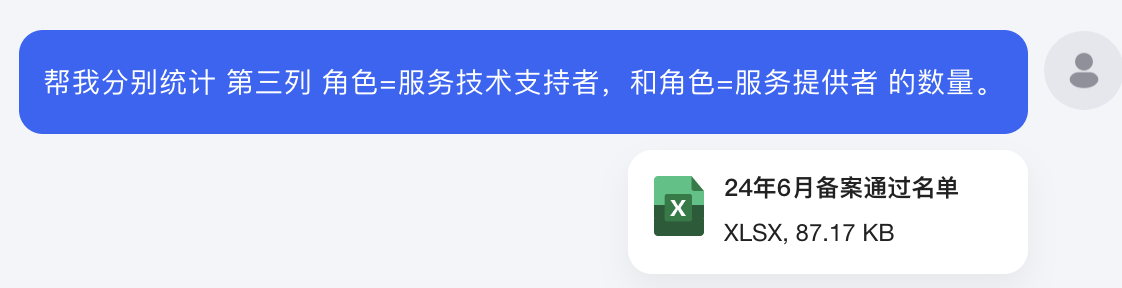
使用文档:境内深度合成服务算法备案清单(2024年6月) (1).docx
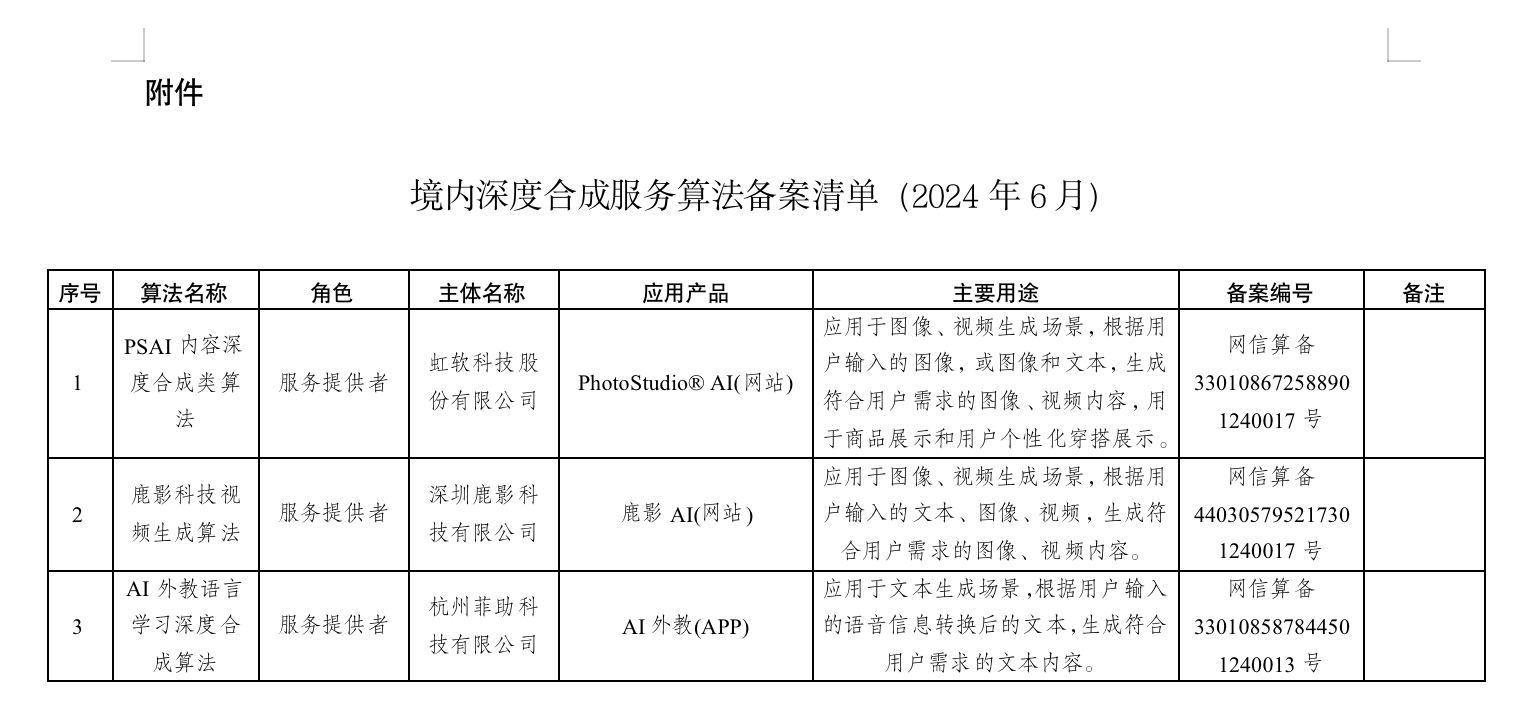
p.s. 共有492条数据,服务提供者=389条;服务技术支持者=103条;
测试输入:
测试结果输出:
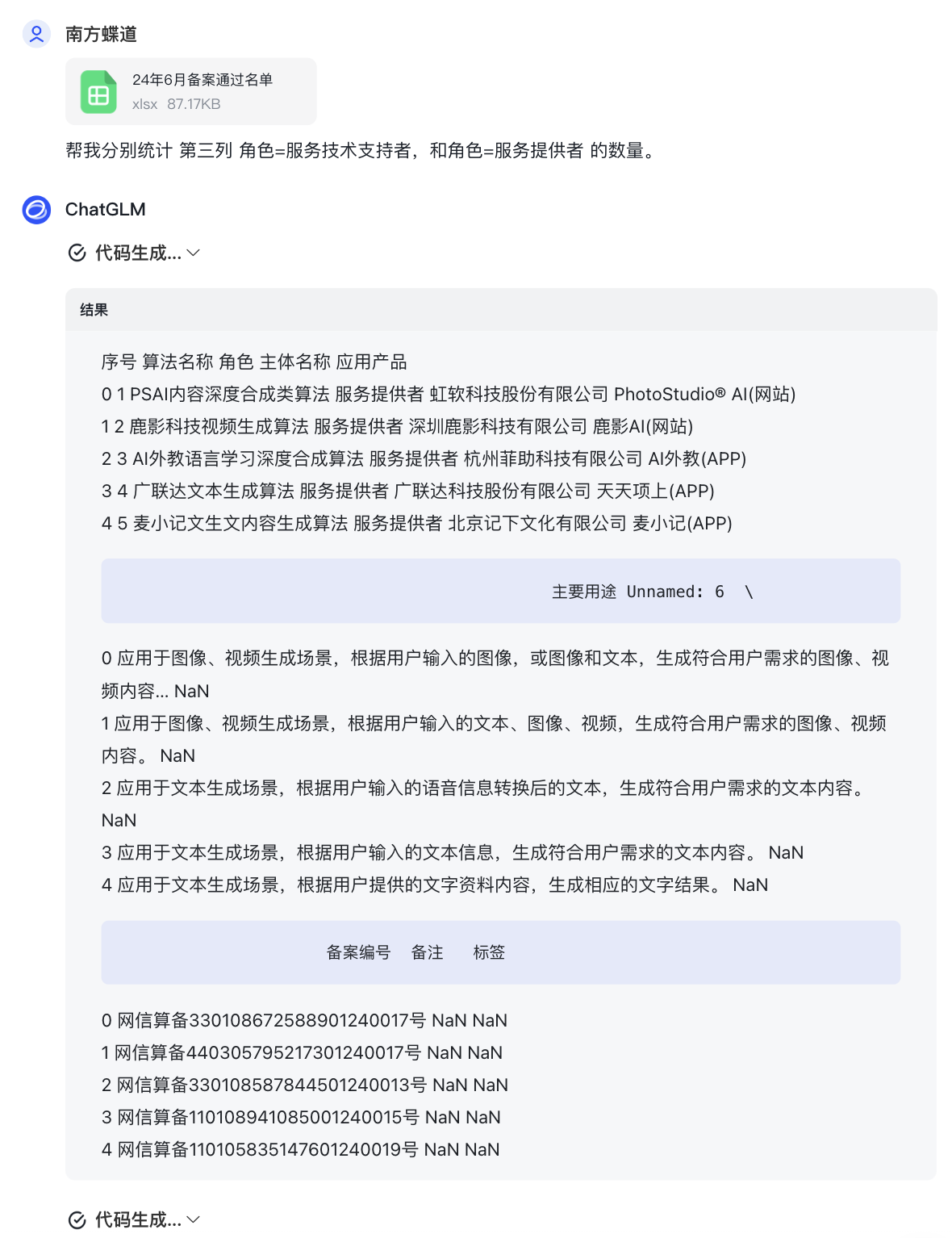
(1)chatGLM-4.0网页版-输出结果:

(2)百度文心一言3.5网页版-输出结果:
回答报错、不正确。
第一次系统默认调用【阅读助手】插件,报错(这个插件总是报错,这是我遇到的第五六次了…)
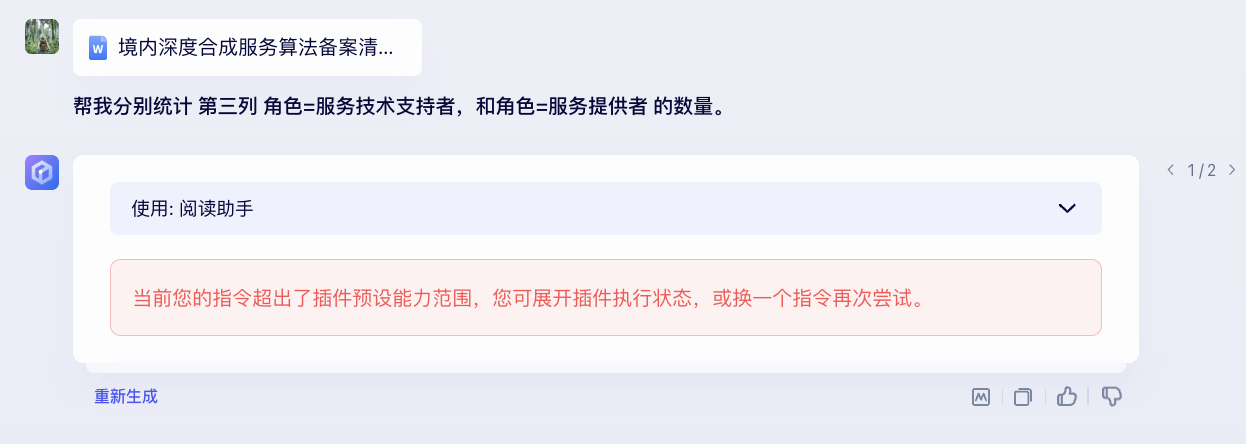
第二次系统给的结果如下:
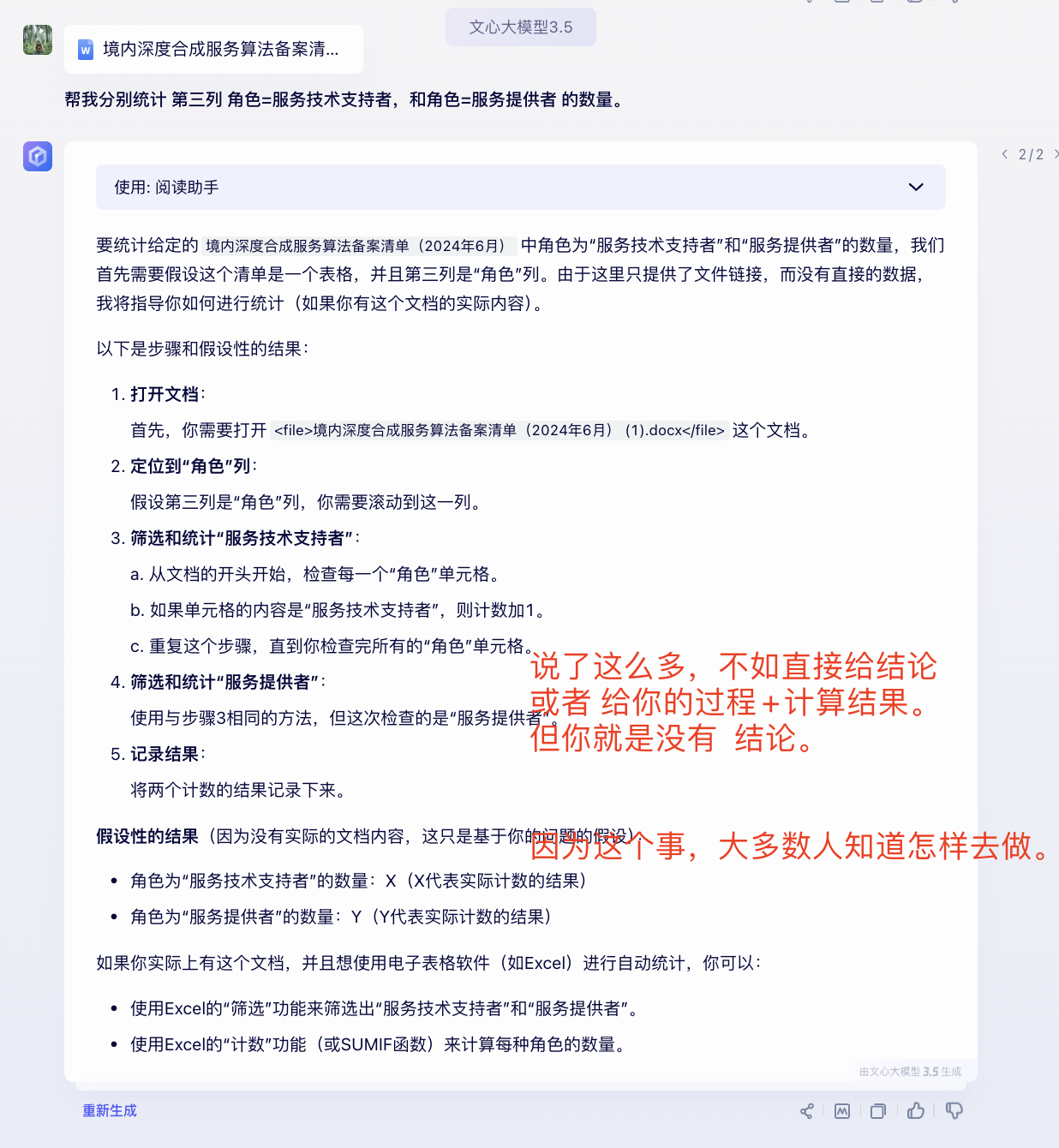
(3)阿里通义千问2.5网页版-输出结果:
回答不正确

(4)kimi网页版-输出结果:
回答不正确
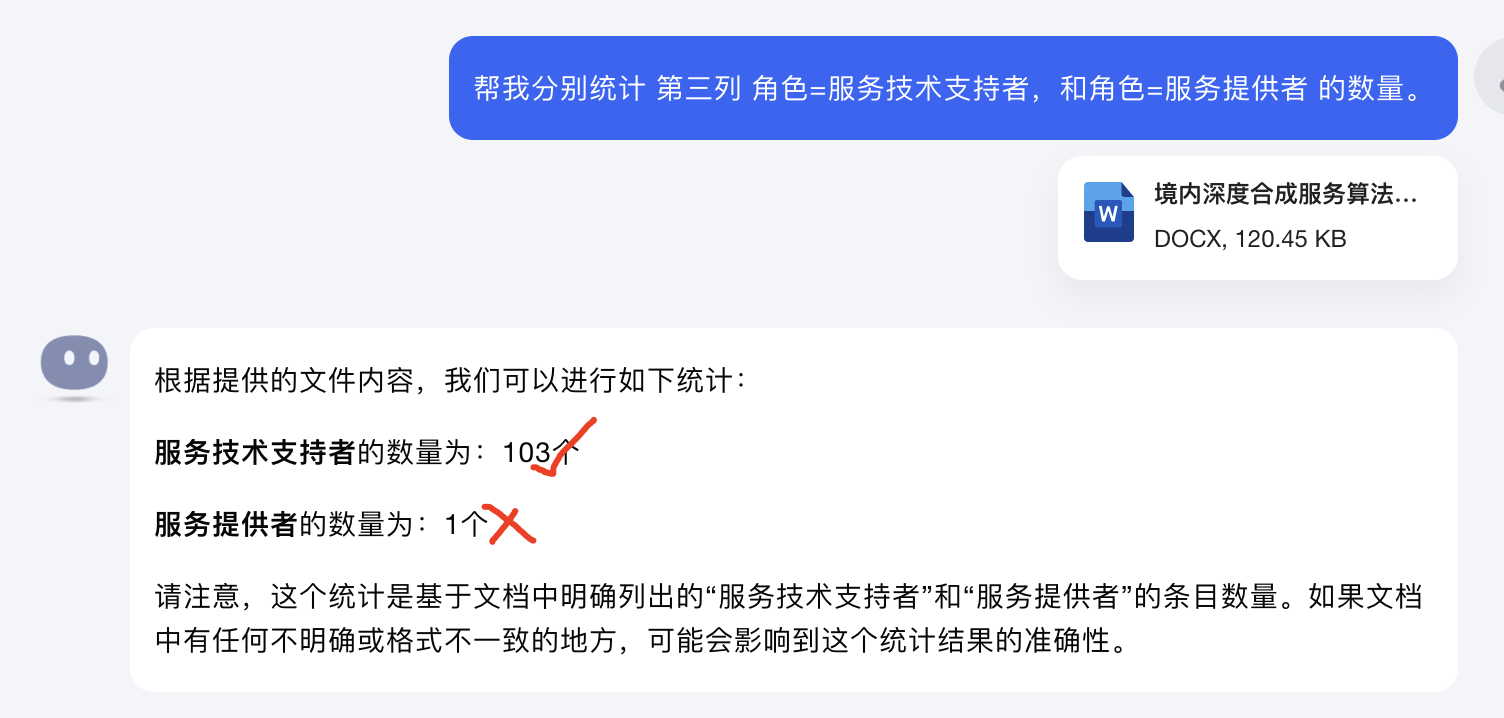
(5)腾讯元宝网页版-输出结果:
回答不正确
实验一结论:
可以看到,当使用word文档,对chatbot进行数据统计提问时,各个厂商的chatbot均不能完成任务,哪怕是简单的“统计某一列中值=XX 的行数等于多少” ,现阶段的chatbot也不能完成。
okay,是输入方式不对,我们改成 EXCEL文件作为输入,进行测试。详见下面的实验二。
2.2 实验二:使用excel文件,测试简单的【数据统计】功能:统计某一列 [数值=xx] 的行数有多少
(1)实验时间:2024年6月17日
(2)实验人:南方蝶道
(3)实验过程记录:
使用文件:24年6月备案通过名单.xlsx
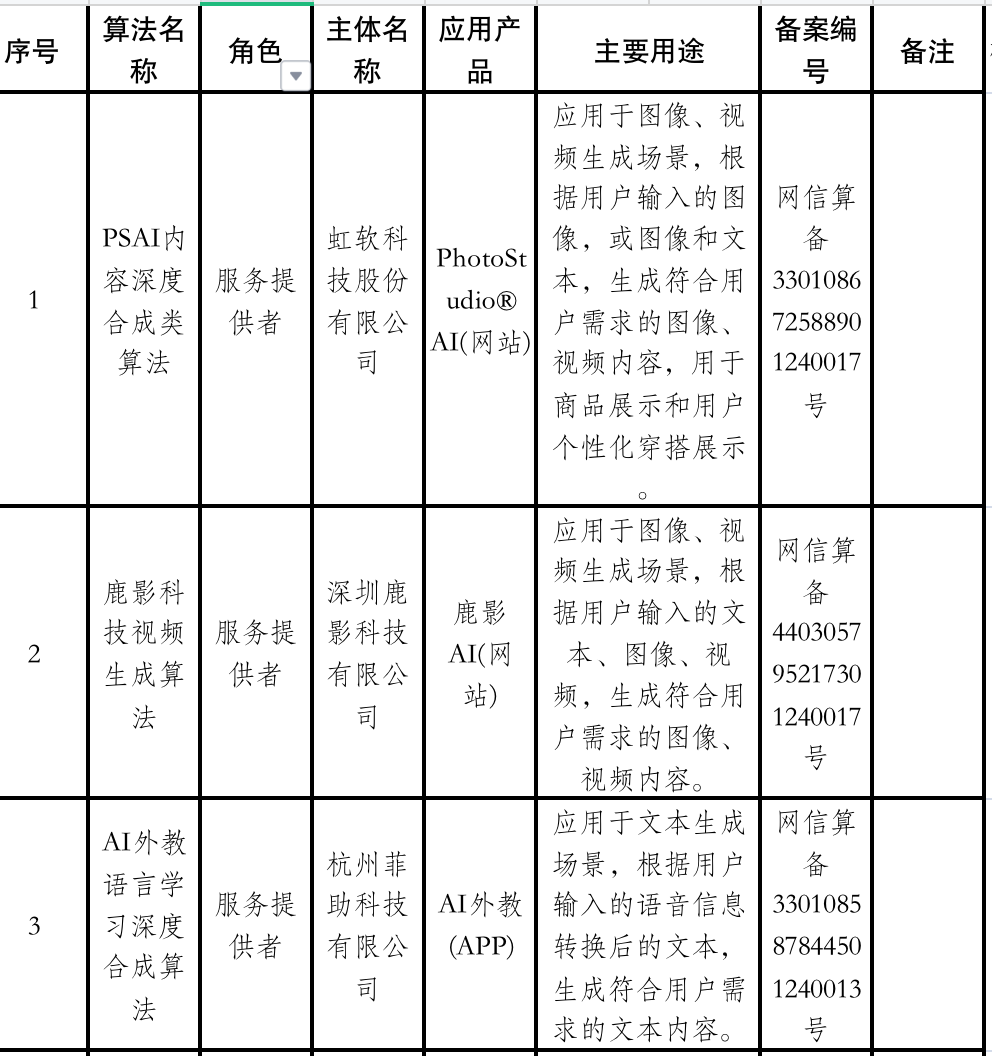
p.s. 共有492条数据,服务提供者=389条;服务技术支持者=103条;
测试输入:
测试结果输出:
(1)chatGLM-4.0网页版
下面结果表明:chatGLM不仅数据分析问题可以计算正确,还可以绘制统计图表~

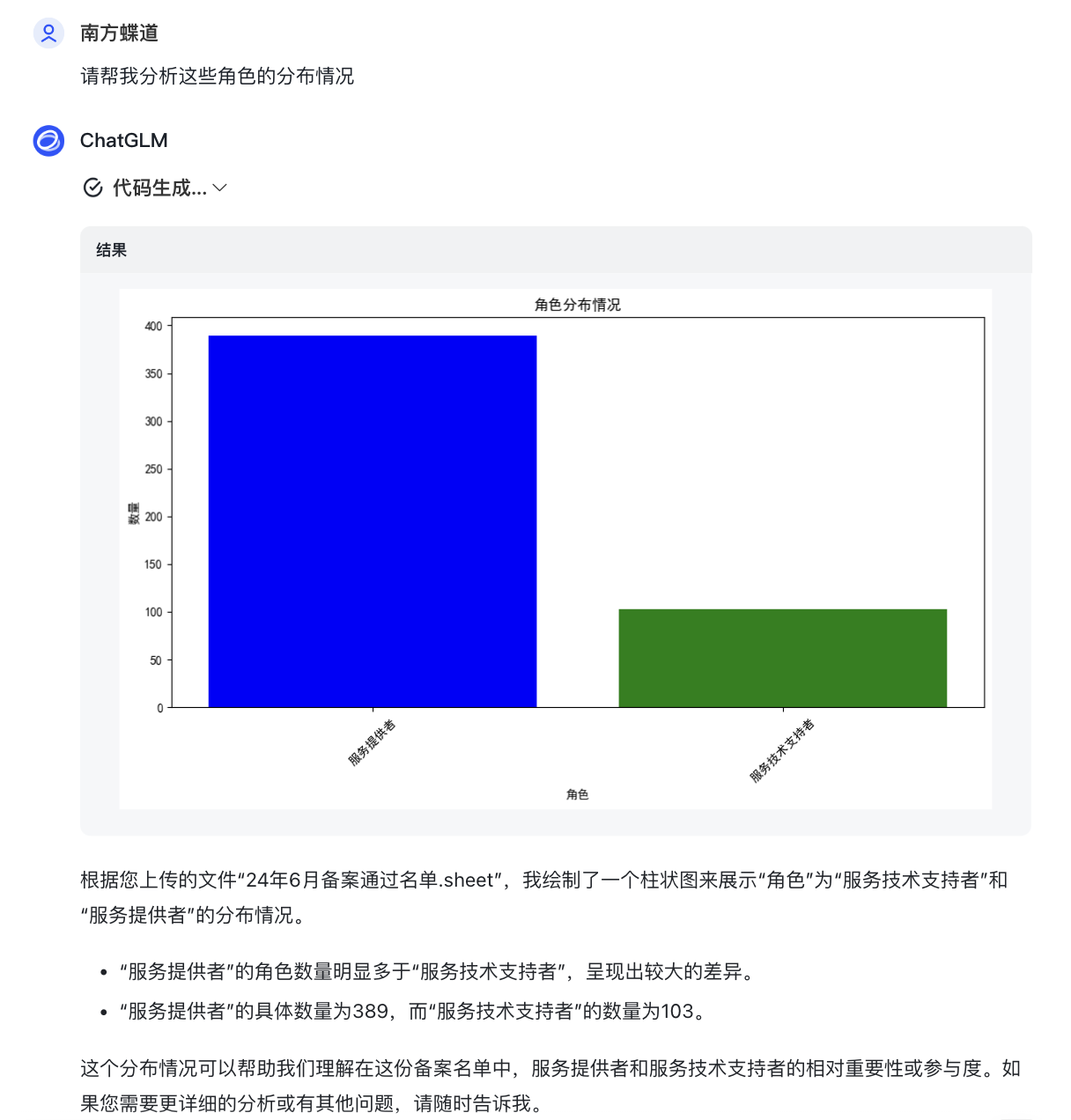
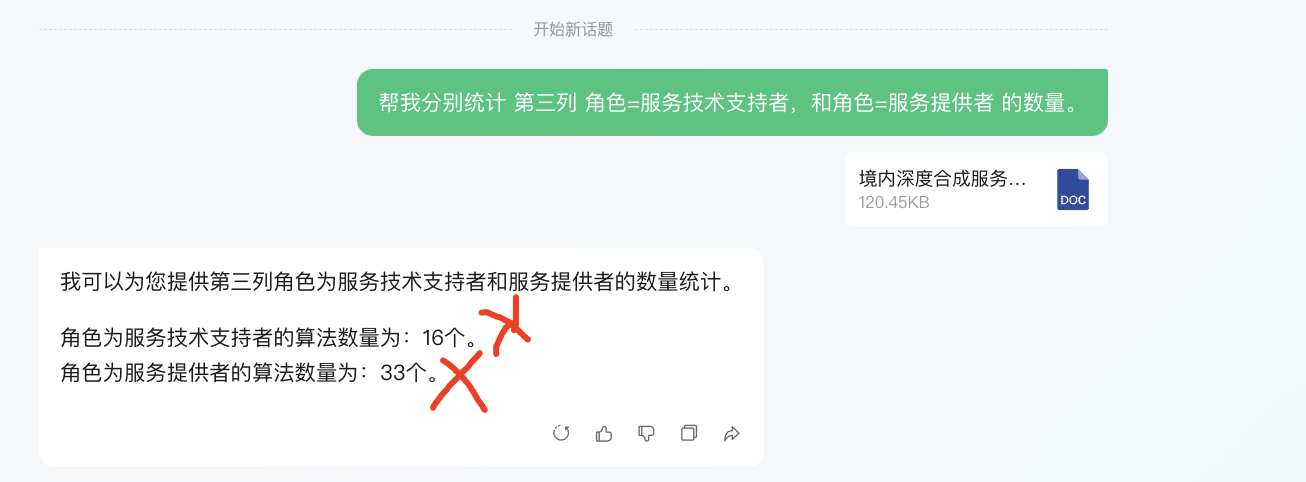
再问它一个统计问题:“帮我统计 涉及“多模态”字样的 ,且角色为 “服务技术支持者”的数据有多少条,并给出具体的数据行”

(2)百度文心一言3.5网页版-输出结果:
文心一言chatbot默认的对话窗口,不支持解析excel。即不支持上传excel文件,仅支持pdf、word和图片类型文件。

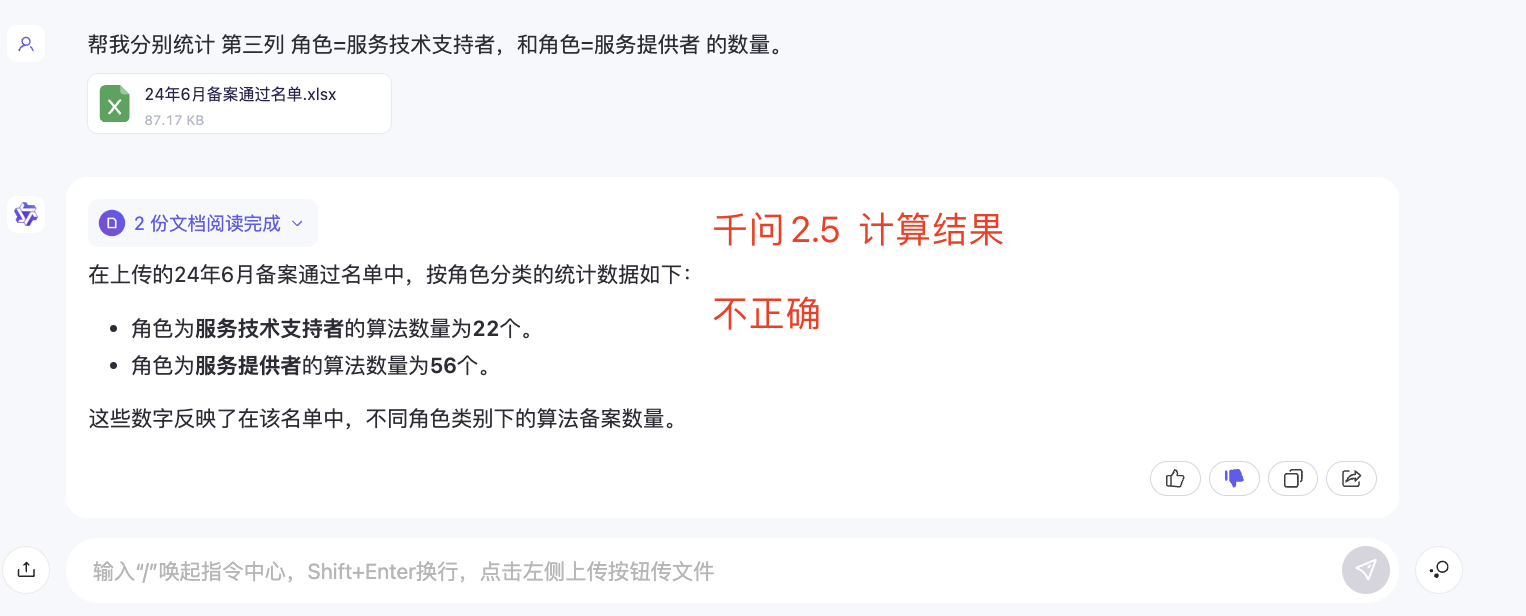
(3)阿里通义千问2.5网页版-输出结果:
计算不正确
(4)kimi网页版-输出结果:
算了2遍,都不对。
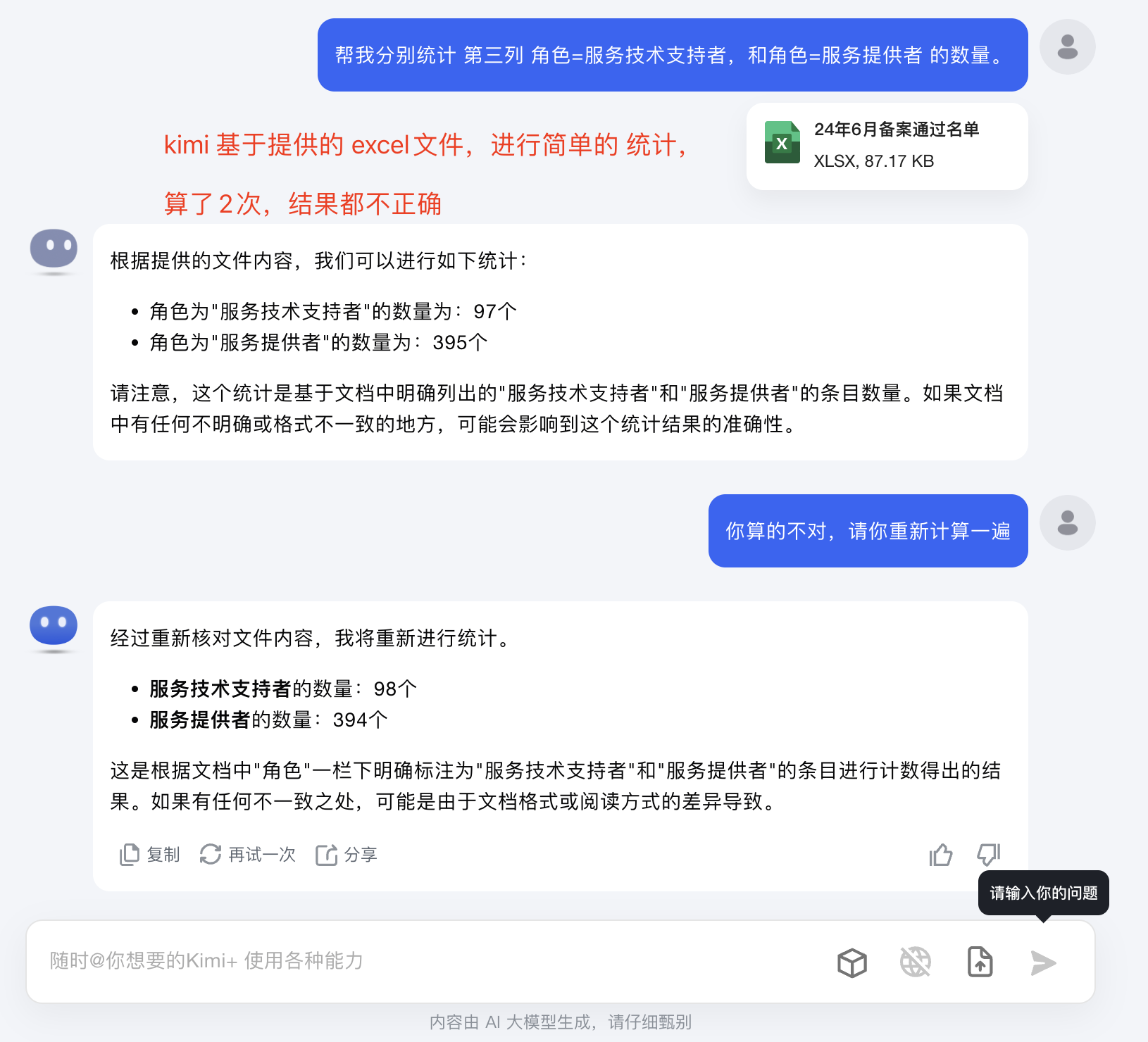
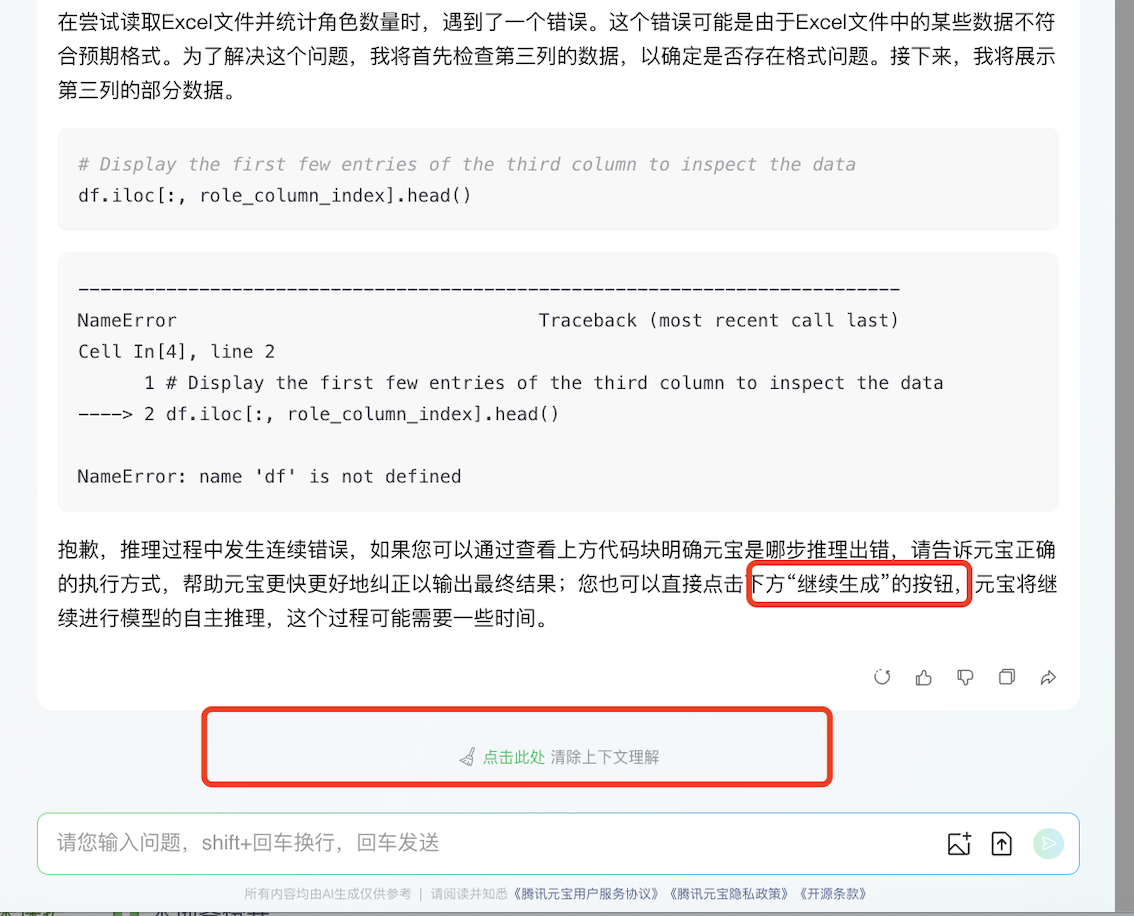
(5)腾讯元宝网页版-输出结果:
自己报错,执行不下去中断了问题。

再试一遍:还是同样的报错。显然,这不是偶发BUG。
报错问题详见:https://yuanbao.tencent.com/bot/app/share/chat/177e6bdd9125a1df7fdeac80574fd415
实验结论:
由实验二各个厂家chatbot的实际测试结果,“数据统计功能“哪家强?——相信大家也一目了然。
1、智谱AI(GLM-4)不仅给出了正确的计算结果,还可以给出相关问题并绘制”数据分布图表“;kimi给出了结论,但计算错误;腾讯还在报错卡BUG执行不下去的路上;百度还不支持excel数据分析,任重而道远~
综上,智谱AI chatbot在【数据统计分析】的路上,进化的最快、能力最强!
在2024年6月17这个时间节点,在”Excel数据统计&分析“这一命题任务上,chatGLM完胜!这一点毋庸置疑~ 它能够分析问题->自主判断调用其系统内部的【代码生成助手】→自动执行任务→给出结果&且结果正确。
emmm,但本着开放包容、不冤枉任何一家chatbot的原则,下面再深入看看,是不是各家chatbot有其它隐藏着的excel技能(如Excel数据分析智能体啥的),只是我没有发现?
——嗯,下面再来深入看一看吧…
2.3 实验三:腾讯元宝、百度文心一言、阿里通义千问、kimi chatbot【数据分析】功能深挖
(1)实验时间:2024年6月17日
(2) 实验人:南方蝶道
(3)实验过程记录:
(3.1)百度chatbot–【数据分析】功能深挖,到底有没有?
之前在实验二中,我们发现文心一言chatbot,压根不支持在【对话框】中对excel类型的文件进行上传和解析;
下面看一看其【插件商城】、【智能体中心】(百宝箱)里面是不是有相关的彩蛋?
(1)文心一言-【插件商城】截图:
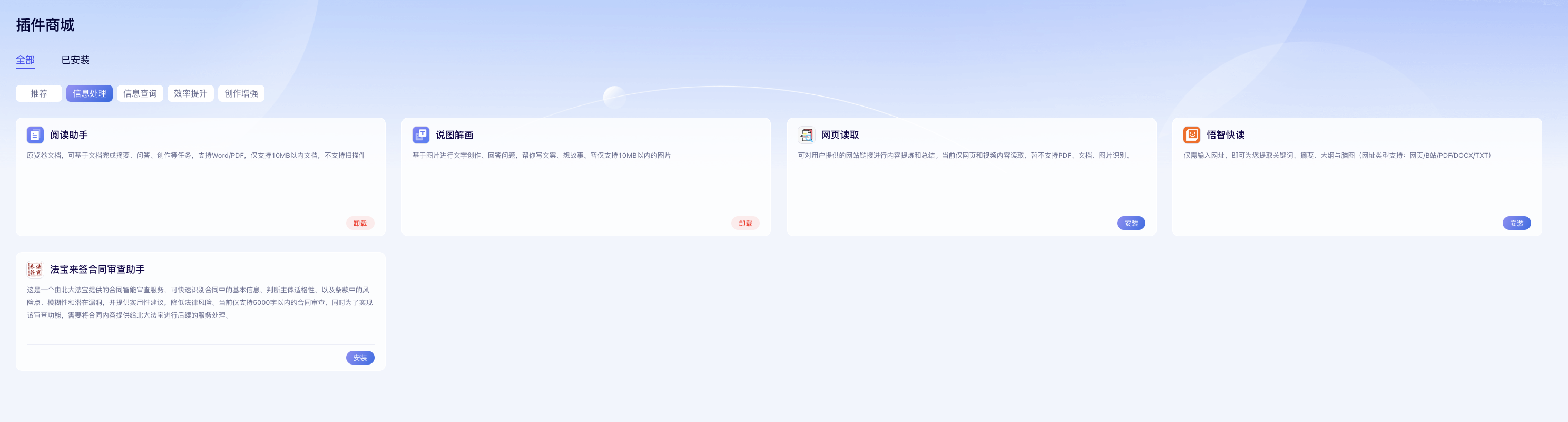



翻了一圈【文心一言-插件商城】,没有看到【数据分析】相关的插件~
(2)文心一言-【百宝箱】截图:
直接搜excel相关的智能体/指令,百宝箱搜索结果中给了4个,嗯,但是也没有能干”excel数据统计分析“这件事的。

再试一试“代码”、“sql”相关的:
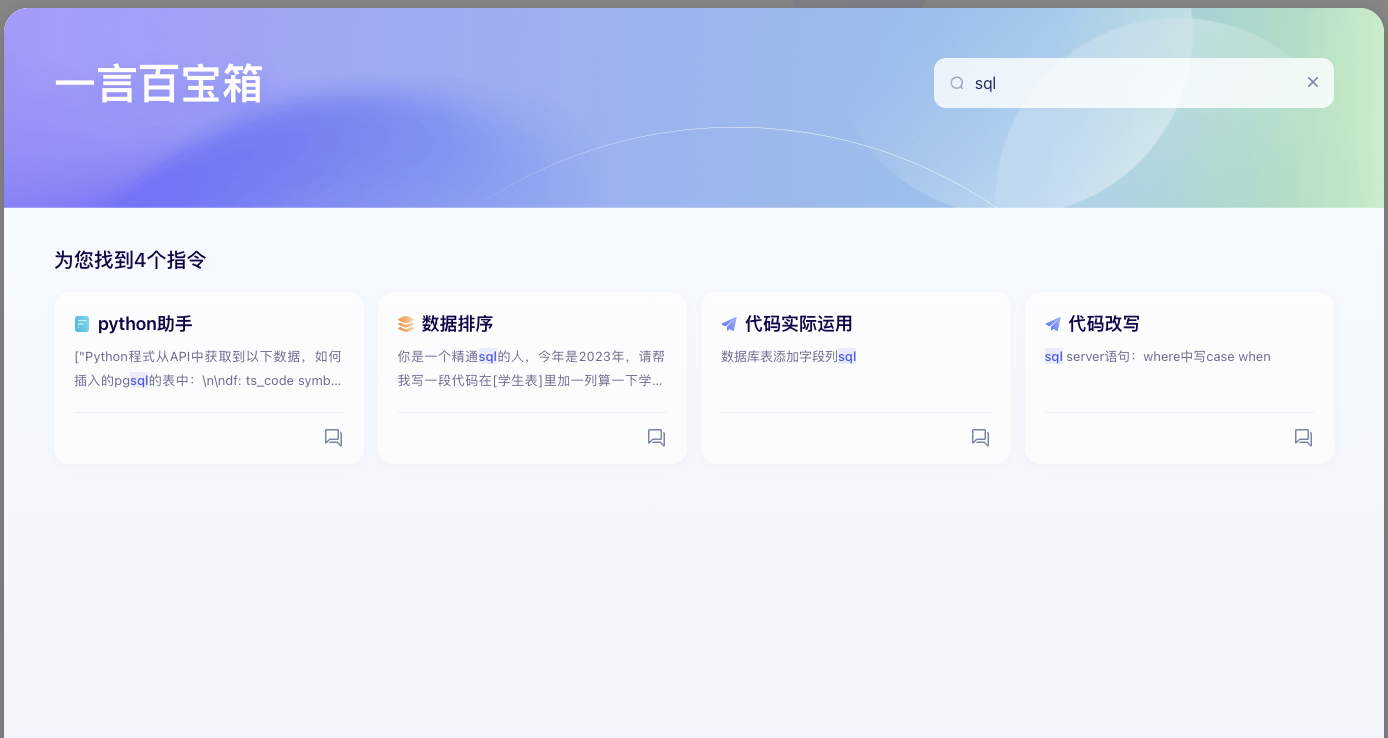

至此,文心一言chatbot鉴定完毕,现阶段(2024年6月)就是不支持【数据统计分析】,看来只能挪步至隔壁【千帆大模型平台】了~~
后面翻一翻【千帆大模型】平台上的智能体,是否有”数据统计分析“相关的。
(3.2)腾讯元宝–【数据分析】功能深挖
搜一搜元宝是否有 excel相关的智能体?——emmm,Nothing~(下图是24年6月17日截图)

再试一试 是否有“代码生成”(参照智谱AI)相关的智能体?——emm,也没有。(下图是24年6月17日截图)

(3.3)阿里通义千问–【数据分析】功能深挖
(1)通义千问-效率导航-工具箱:无“数据分析”相关;

2)通义千问-智能体:提供了excel相关的智能体,但是测评下来,智能体的功能单一、质量不高,无法完成任务(如不支持传excel文件、有1000的token限制等);


(3.4)kimi–【数据分析】功能深挖
下面是kimi 的”kimi “智能体列表全部的截图(2024年6月17日),可以看到在这个节点,kimi智能体中心没有【数据统计分析】相关的~
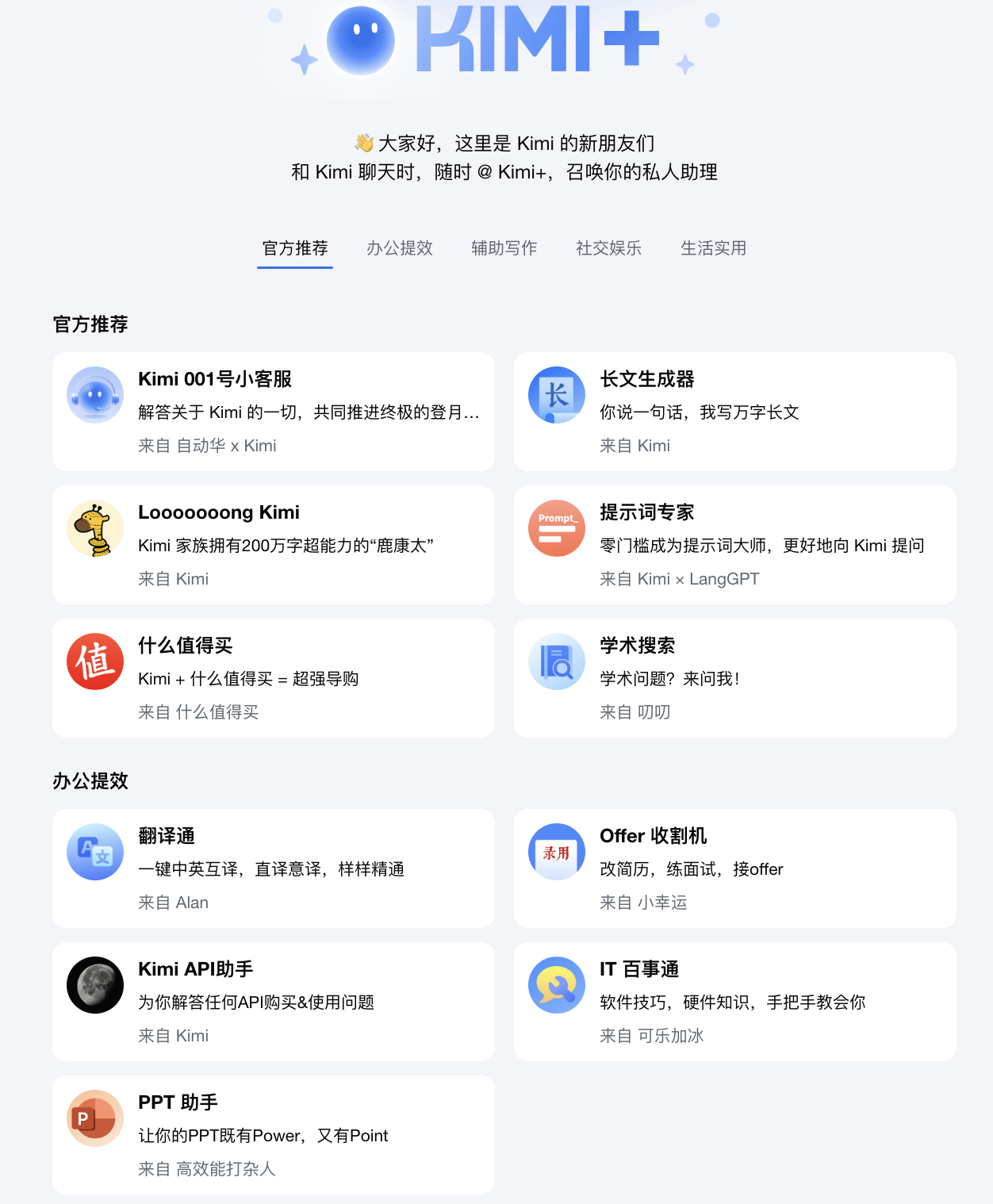

实验三结论:
看来,我没有冤枉各家chatbot,真的没有更多的数据统计分析能力…
二、各种PR稿鼓吹大模型可以做高考数学题,真的能吗?
结论是:现阶段,还不能~ 但有机会,任重而道远~~
这里给大家奉上一篇,我个人认为写的不错的文章(《当AI遇上高考数学题,4个大模型“考生”“成绩单”出炉》,6月19日发表的,下称文章1),文章中的一些核心观点和测评过程中遇到的大模型问题,给大家分享一下(他山之石、可以攻玉):
该篇文章选择了4个大模型,分别是【星火大模型(v3.5版本)】、【文心一言(3.5版)】、【智谱清言(GLM-4)】通用大模型,和 以数学能力见长的教育垂类模型:【九章大模型】。
测评数据:选取的是2024全国高考数学–新课标1卷–客观题部分,进行测评。其中包括8道单选题、3道多选题、3道填空题。
此外,由于试题中存在图形、大量数学符号,该篇文章,为防止以文本形式输入题目产生偏差,统一选择以图片形式呈现题目并提供给大模型进行解答。
测评表现和测评结果:
四位“考生”此次作答正确率:从高到低依次为星火大模型(85.71%)、九章大模型(78.57%)、智谱清言(28.57%)、文心一言(7.14%)。
尽管做题结果正确,但各个模型做题的推理过程,均禁不起推敲;
——那么究竟差在哪了?
“第一,题目识别上存在比较大的困难,涉及一些数学符号、分式等会影响识别效果,还有一些图形、表格识别存在问题,以及一些数学专业术语的表述识别也不够精准。
第二,几个大模型在逻辑推理能力上还存在不足。
第三是解题方法较为单一,大模型似乎只能按照固定的模板去答题,而不能依据题目的特征因地制宜地选择最优方法。”
——以上观点,均来自《文章1》
(1)文心一言(v3.5)–2024年-高考数学客观题表现
– 该篇文章测评中可以发现:
①文心一言具备读取图片内容的能力,但无法识别仅带有复杂分数的公式和图形。
– 例如单选题第3题,明明成功读出题目中的“⊥”符号为“垂直”,却在后面的步骤中理解为“平行”(题面中未出现任何平行相关字眼或符号),经提示,文心一言发现理解错误,却在再次解答时又出现理解偏差。
——这就是大模型普遍均存在的让人头疼的“幻觉之一”(上下文矛盾问题);
②文心一言解答数学题并不是用数理逻辑,而是试图用文字论证的方式去猜测一个接近的结果。
– 从单选题第5题的答题情况不难看出;
③文心一言几乎对每一题都进行了详细的推理,但最终大部分题目都得出了错误的答案。
④ 文心一言:优秀的文科生,但理科真的差;
“文心一言在答数学题能力上虽然逊色,但通过一系列的追问、对话可以发现,这位“考生”对语义语境的把控能力非常优秀,很容易明白用户在说什么,在用户补充提醒的时候,它很快就可以知道根据新信息去解释上面的题目。”——文章1。
(2)智谱清言(GLM-4)–2024年-高考数学客观题表现
①智谱清言也存在上下文矛盾的幻觉问题。
在第12题中,经过一番分析后,智谱清言告诉用户无法计算出结果。
在第13题中,智谱清言重复地分析、发现问题、重新审视问题,又一遍一遍地发现行不通,进行了十轮以上的死循环(在我之前测试,我发现腾讯元宝也有这个问题…后面和大家分享),直到人工点击暂停才停下。
②智谱清言的解答比较简洁,一般会直接回应题目,有一定的逻辑性和条理性。
③但答案不是特别详细,也没有深入分析。
④有些题目的回答和标准答案的匹配度不高,有些题目虽然答对了,但会漏掉一些关键点。
(3)星火大模型、九章大模型——2024年-高考数学客观题表现
①如果说文心一言是个“不错的文科生”,那么【星火大模型】和【九章大模型】,就是典型的“理科生”,虽然非常擅长解题,但上下文语义语境的理解是它们的弱势。
– 例如,当用户对【星火大模型】提出:
Q:“上面这道题可以再详细分析一下吗”时,星火并不能理解指向的是什么,而是回答:
星火大模型回答:“很抱歉,由于我无法看到您提到的具体问题,所以无法为您提供更详细的分析。请提供问题的详细信息,以便我能够更好地帮助您。”
–当用户对【九章大模型】追问:
Q:“请你检查一下这道题,D选项到底对不对”;
九章:“当然可以,请您提供题目的具体内容,包括选项D的表述,我会尽力帮助您检查。”
——说明其比较擅长解题,但很难联系上下文语境语义来与用户互动对话。并不明白用户问的是什么。
②九章大模型的部分解题过程也存在瑕疵。
在一道多选题中,九章大模型在推理中明明认为C选项错误,但最后又把C选为正确答案,“这个表述上下文之间没啥逻辑关系,让人摸不到头脑。”上述数学专业人士指出。
② 星火和九章 对题目的处理上:
1)九章大模型在图片题目识别上,会先在输入文本框中识别读取出题面,并以文本形式呈现,用户可在框内确认题目的准确性。若发现识别错误,点击即可出现数学符号的辅助输入工具栏,进行编辑修改,防止题目读取错误。
2)而星火大模型,没有上面这个步骤。直接回答,所以不知道题目识别环节理解了多少。
三、写在最后的一点思考
我的一些观点:
1、PR稿吹得天花乱坠,但是实际落地,一堆工程问题需要解决;
——这是因为厂商需要“造梦”,以获得资本的青睐;
——所以我们要建好心里预期,不要抱过高期待;
2、新技术的出现,于世界、于我们都是好事,我们要拥抱它,同时需要给予它一些耐心和包容性~
3、大模型之于教育场景(辅导服务,课后点评,辅助解题等)有很多想象空间,但同时也有很长的一段路要走…
写在最后:
1、希望本文对各位小伙伴了解chatbot能力和市场,有所帮助~~
但是但是,借用本文内容的观点和内容,请注明来源链接~~ 禁止直接抄袭~
2、除了本文的chatbot【数据统计】能力测评外,本人还系统进行了“AI搜索 写作”、“图片理解”、“长文档解析和问答”、“Agent搭建”等各项能力测评,后续有时间同大家分享~
本文参考资料:
[1]当AI遇上高考数学题,4个大模型“考生”“成绩单”出炉 — 新京报
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
