用户研究提供什么价值?
上一篇文章讨论了消费品行业和互联网行业中用户研究的差异,在进一步思考互联网用户研究工作之前,我们首先聊一聊用户研究工作究竟在提供什么价值。
讨论用户研究工作价值时,常见的思路是从商业问题切入,例如在立项初期,可以通过用研判断需求是否存在;在设计阶段,可以通过用研验证产品可用性;在迭代时,可以通过用研获得启发、预测策略效果等等。
这样看起来,用户研究是在不同环节有不同效用的“万金油”。那么用户研究产出的内容是否有一些共性?不同业务、不同阶段的负责人在启动用户研究时,是否可以有共通的期待?作为用研同学,在向他人解释用研工作时,是否有更加概括而又能让人一下子理解的表述方式?
这一篇尝试从用户视角(也就是使用用户研究结论的同学的视角)回答一下用户研究究竟在提供什么价值,这既涉及“用户研究员的工作价值”,也可以是“业务同学做用户研究的价值”。
一、用户研究方法拆解
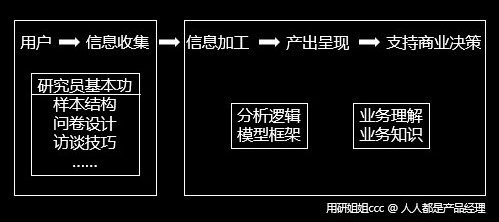
用户研究的工作是从用户侧拿到信息,以支持商业决策。
拿信息是研究员的基本功,具体包括找谁、问什么、怎么问等等。从信息加工到给出结论,再到支持决策,除了基础统计方法,还涉及分析逻辑、模型框架,对产研设计营销等领域的知识,以及对业务逻辑的深度理解。
二、用户研究价值拆解
什么是一次好的用户研究?个人认为标准是:能提升决策质量的研究是好的研究。
那么一份用研结果如何支持商业决策?
可以拆解为以下三个层面:提供代入感,提供分析模型,提供统计数据。
三、用户研究价值1:提供代入感
代入感能让我们对用户感同身受,发现“不知道自己不知道”的东西。
1. 代入感是什么
代入感不是解读数据,不是用复杂的统计学方法找规律,而是运用本能的同理心,将自己的头脑和心思作为工具,加工用户信息,获得主观的、感性的体会。
产生代入感的前提是人与人有相似的底层需求、理解能力、情感本能等等,在这样的基础上,如果能够充分呈现用户的生活环境、过往经历、信息媒介、使用情景等信息,就可以让业务同学感同身受地领会到用户的感受和需求。
项飙老师在《把自己作为方法》一书中有一段关于“理解”的描述很精彩,摘录如下:
理解是人的本性的一部分,作为心理机制,一点都不难,如果说理解有难度,其实是一个位置问题,看你愿不愿意把自己摆在对方的位置上。很多时候人们拒绝这样做,因为有利益在里面……
什么叫“理解的学术”,不一定要把对方的心理机制像心理分析师一样写出来,主要就是位置的问题,把他在这个社会的位置讲清楚,把他所处的关系、所处的小世界描述清楚,大家自然就理解了。
这是用户研究工作非常有魅力的一个地方。你有机会面对真实的用户,与真实的用户对话可以瓦解某些天马行空的设想;在不专业且没什么耐心的用户面前,之前坐在办公室里拍脑袋想出来的一些主意也会显得苍白而幼稚。
举一个小例子,曾经为一个线下活动做效果评估,在对用户进行访谈时,我眼睁睁看着对方说着说着话就闭上了眼睛,因为他参加了一整天活动已经非常疲惫了。
之前可能也在问卷答案中看到过类似“活动时间过长”这样的反馈,但这样面对面的感受还是不一样的。
还有一次去京郊某地做项目,这个地方其实属于北京,但当地出租车司机会说“你们从北京来呀?”,这样的措辞体现着本地居民对该地区的理解:行政划分上是北京,却不是那个超一线大都市北京。这种细微的感知难以从常规的统计数据中获得,只有在现场、在用户身边才能发现。
代入感不只有“在场”时能感受到,也可以通过解读报告来代入。这也是为什么调研报告中往往会提及用户社会信息,比如性别、年龄、收入等,目的之一就是提供代入感,了解社会背景能理解用户群生活在怎样的环境中,进而理解他们的观点、态度、感受。
2. 代入感的价值
代入感为什么重要?逻辑和数据为什么不足够?因为“人”太复杂了,与人相关的信息很多,维度很多,运作机制很复杂,人的逻辑不是物理的逻辑,描述人的模型都会压缩维度。
比如各种行为模型、需求分析模型、用户分层模型,模型的简洁意味着损失大量信息,模型和数据在某种层面上是在远离真实。
理解复杂的“人”的一个方式就是代入,直接从对方的视角看ta的世界。
这可以避免遗漏逻辑,比如忽视某些因果规律、忽视重要信息,也可以重新反思自己头脑中是否存在未经审视的假设。
3. 代入感的应用与局限
从研究方法来看,定性研究的结构更加开放,能够提供更多生活细节,也会记录详细的用户语句、用户行为,所以能够提供更强的代入感,比如访谈、座谈会、入户观察、陪同消费、观察使用。
另外还有一个很棒的获得“代入感”的方式:体验半天客服工作,亲自倾听客户投诉。相信一定会收获满满,哈哈。
另一方面,“代入感”作为研究产出的问题也很明显:
- 效率低。每个用户都很不同,逐一代入的方式效率太低了。
- 普适性弱。从不同人的身上捕捉到不同的逻辑,如何取舍?不同的研究员有不同的感受,如何整合?
- 难以传达。研究过程中获得的代入感如何同步给未参与研究的同学?
因此我们接下来的两个工具:分析模型和数据信息。
四、用户研究价值2:提供分析模型
分析模型是从纷繁的信息中梳理出逻辑主线,有时候已知信息已经很多了,却没有分析思路,便陷入“不知道自己知道”的状况,合适的分析模型可以解决这个问题。
用户研究模型和产品运营方法论有什么区别?和商业分析模型有什么区别?针对同一个问题,可能有不同的分析模型,又该如何选择?
不同模型有不同侧重、不同视角、不同默认假设,甚至不同的价值取向。
举个例子:如何分析不同需求点的优先级?有以下几个常见的模型:
- 重要性x满意度的矩阵。横坐标重要度,纵坐标满意度。通过定量调研获得对于不同需求的重要度和满意度得分,如果一项需求处于“重要”且“不满”的象限,就认为应当优先改进。
- kano模型。针对每项需求询问:如果有该功能你觉得如何?如果没有该功能你觉得如何?(我很喜欢-理应如此-无所谓-勉强接受-很不喜欢)根据两个得分将需求分成五种:魅力属性、期望属性、必备属性、无差别属性、反向属性。
- 投入产出比。针对每个需求,评估覆盖用户量、单用户收益、时间&人力成本,选择投入产出比最高的需求优先满足。
重要性x满意度模型假设:对于用户的每个需求,都是满意度越高越好。
但kano模型的假设是:有些需求只需要达到及格线,不需要做到太好(必备属性),比如日常自行车骑行速度,对普通用户来说能够满足通勤使用就好,不需要达到竞赛水平;有些需求则是可以缺失,但如果被满足会让很多人喜欢(魅力属性),比如手机防水功能;同时存在一些需求是越满意越好(期望属性),比如性价比越高越好。
以上两个模型背后的价值取向是:让用户满意、喜欢。
而投入产出比的模型则是在考虑人群需求的基础上,进一步量化成本和收益。相比之下,“用户满意”只是一个中间变量,最终目标是最小成本获得最大收益。前两个模型并不是认为成本和收益不重要,而是成本收益问题不在这一步解决。

用户研究项目相关分析模型最大的特点就是包含用户反馈数据,并对用户数据有更多处理。常见的思路包括:花样用户分层(比如NPS/RFM,比如交叉、降维、聚类等统计方法),花样描绘行为态度(又叫UA,比如旅程地图/各种漏斗/各种深度x广度象限图),花样找相关关系,等等。
看到一个模型时,可以思考一下这个模型的假设是什么,默认的价值观是什么,适用场合是什么,是否补充了自己原本缺失的视角。模型没有绝对的好坏,模型领进门,修行靠个人。
五、用户研究价值3:提供数据信息
统计数据是将认知进一步量化,在“知道自己不知道”时的定向收集信息,找到“最大”、“最多”、“最相关”等东西,这背后带有一点功利主义的逻辑。
大多数用户研究项目都需要有定量数据支持最终的结论,尤其在周期性项目中,统计数据和数据的变化情况就是报告的主要产出。
用户研究中的数据分析,与销量数据分析、线上行为数据分析等有什么差异呢?
1)信息更加丰富。比如可以了解想法、态度,以及生活背景、人际关系。
2)能够获得竞品数据。比如用户对不同产品的购买情况、对不同品牌的印象,等等。
3)样本结构非常非常重要。
这是非用研同学很容易忽视的一点。在分析销量数据、行为数据时,通常是直接拉取符合条件的全部数据,但用户研究无法触及全部用户,时间和成本也不允许过大的调研范围。
如何投放问卷?通过什么渠道,用什么话术吸引用户打开?回收的样本结构能否代表大盘样本?如果代表性有偏差,如何转化成可用的数据?这些问题是用户研究同学需要熟练掌握的。
所以作为用研同学,看到网络上各种报告时,往往会对调研对象、样本结构、发放渠道很敏感,如果报告没有给出这些信息,其结论的适用范围就很可疑。
4)问法非常重要。
用户调研是与用户的互动,如果要得到真实结果,就需要设计中立的,无引导性的问题,不能在问卷中透露或者暗示研究者的喜好;题目要简单易懂,不能有专业术语,每个选项要单一简洁,不能在同一个选项中包含冲突的内容,等等等等。
六、小结
所以,用户研究可以提供代入感,可以提供分析模型,可以提供统计数据,在不同的项目中会有不同的价值侧重。

作者:用研姐姐ccc;用户研究资深菜鸟,多年互联网用研经验+多年传统行业用研经验
本文作者 @用研姐姐ccc
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
