通俗理解决策树
目录
- 前言
- 决策树的结构
- 决策树的构建
- 信息增益(ID3算法)
- 信息增益率(C4.5算法)
- 基尼指数(CART算法)
- 熵VS基尼指数
- 剪枝
- 优缺点及适用场景
- 参考文献
前言
从这一期开始,我们准备介绍一系列经典机器学习算法模型,主要包括逻辑回归,支持向量机,决策树,因子分析,主成分分析,K-Means聚类,多元线性回归,时间序列,关联规则,朴素贝叶斯,隐式马尔可夫,协同过滤,随机森林,XGBoost,LightGBM等,一般会涵盖算法模型的引入背景,算法模型依赖的数学原理,算法模型的应用范围,算法模型的优缺点及改进建议,工程实践案例等。既适合刚入门机器学习的新手,也适合有一定基础想要进一步掌握算法模型核心要义的读者,其中不免会涵盖许多数学符号,公式以及推导过程,如果你觉得晦涩难懂,可以来"三行科创"微信交流群和大家一起讨论交流。
决策树的结构
我们在做决策的时候往往会权衡各种利弊综合各方面因素做出最有利的决定,举个例子,三叔在考虑周二晚上要不要去打羽毛球,首先会考虑最近身体状况是否适合运动,然后会考虑当天的天气是否下雨,是否有好朋友同去,是否有场地等因素最后决定是否去打羽毛球,如果把这些因素及判定用下面竖向的流程图画出来正如一棵倒立的树,决策树因此而得名。
类似自然界中的一棵树木由树根树干树枝树叶组成,决策树也是由一些结点(Node)和一些边(Edge)连接而成的一个具有层次关系的集合,由树的根部出发,一级一级往上生长,一个结点的上一级称为其父级,对应父结点,下一级称为其子级,对应子结点,边(Edge)连接父结点和子结点,决策树就是一种树形结构。
-
根结点
没有父结点的结点称为根结点,表示要判断的最终决策,如上图棕色填充的矩形。 -
分支结点
既有父结点,也有子结点的节点称为分支结点,表示要进行某种判断的对象,对象进行判定得到的不同结果形成2个或者多个分支,进入到下一层级的子结点,如上图中蓝色填充的圆形都是用来判断的分支结点。 -
叶结点
叶结点是没有子结点的结点,也叫末端结点,表示判断出来的结果,如图中黄色填充的菱形,根结点到每个叶结点均形成一条路径规则。 -
结点的度
一个结点能够分出多少分支,分支的数目称为该结点的度,如果分支数最大不超过2,那么就是二叉树结构,叶结点的度为0。 -
树的深度(高度)
树的深度也叫树的高度,是指从根结点到叶结点的所有路径规则中,其中经过最多层级的那条路径的层级数称为树的深度。
决策树的构建
有了决策树的结构后,那么如何构建一棵决策树,让其成为一个自上而下,分而治之的有机整体呢?假设给定的数据集为
D = ( [ X 1 , y 1 ] , [ X 2 , y 2 ] , ⋯ , [ X m , y m ] ) T D=([X_1,y_1],[X_2,y_2],\cdots,[X_m,y_m])^T D=([X1,y1],[X2,y2],⋯,[Xm,ym])T
其中, X i = ( x i 1 , x i 2 , ⋯ , x i n ) X_i=(x_{i1},x_{i2},\cdots,x_{in}) Xi=(xi1,xi2,⋯,xin) 表示第 i i i 个实例样本的 n n n 个特征的取值, y i y_i yi 表示第 i i i个实例样本的标签, m m m 为实例的个数。
- 计算数据集关于每一个特征的相关指标;
- 根据分裂规则,选择最优的一个特征作为第一个分支结点,把具有相同划分取值的样本归到同一个子数据集,进入下一层级;
- 对分裂后的结果再选择最优的特征作为下一个分支结点;
- 如果子数据集的标签只有一种,则是叶结点,直接打上标签;如果子数据集的标签不止一种,继续寻找最优的划分结点对数据集进行划分;
- 不断递归调用第2步~第3步,直到所有特征全被全部用完或者所划分出路径都清楚了,跳出循环,完成决策树的构建。
从上面决策树的构造可以看到,一棵决策树的构建关键是不断依据这个分裂规则去找最优特征作为划分结点,分裂规则就给出了一个评判标准,常见的有基于信息增益,对应ID3算法,基于信息增益率,对应C4.5算法和基于基尼指数,对应CART算法。
信息增益(ID3算法)
1948年信息论之父克劳德·艾尔伍德·香农从热力学中借用“熵1 ”的概念第一次提出信息熵(information entropy)用来描述信源的不确定性,解决信息的测度问题。通常,一个信号源发送出什么信号是不确定的,衡量它可以根据其出现的概率来度量,出现机会多,概率大,不确定性就小;反之不确定性就大,因此,不确定性函数 H H H是概率 P P P的减函数,同时还要求两个独立信号所产生的不确定性等于各自不确定性之和,即 H ( P 1 , P 2 ) = f ( P 1 ) + f ( P 2 ) H(P_1,P_2)=f(P_1)+f(P_2) H(P1,P2)=f(P1)+f(P2), 同时满足这两个条件的恰好有对数函数
H ( P ) = − P ∗ l o g 2 ( P ) H(P)=-P*log_2(P) H(P)=−P∗log2(P)
最简单的信号源是仅取0和1两个元素,即二元信源,其概率分别为 p p p 和 1 − p 1-p 1−p( 0 ≤ p ≤ 1 0 \leq p \leq 1 0≤p≤1),该信源的熵函数图形

从图形可以看到,当 p = 0.5 p=0.5 p=0.5的时候,信息熵最大,最可怕的就是这种模棱两可的状态,当 p = 0 p=0 p=0或 p = 1 p=1 p=1的时候,信息熵等于0,极端的就是这种完全确定状态。
一般的,假设信源发出的信号有 d d d种取值 { x 1 , ⋯ , x d } \{x_1,\cdots,x_d\} {x1,⋯,xd}, 对应出现的概率为 { p 1 , ⋯ , p d } \{p_1,\cdots,p_d\} {p1,⋯,pd},这时信源的不确定性定义为所有信号不确定性的和,称为信息熵
E ( x 1 , ⋯ , x d ) = − ∑ i = 1 d p i l o g 2 ( p i ) E(x_1,\cdots,x_d)=-\sum\limits_{i=1}^d p_ilog_2(p_i) E(x1,⋯,xd)=−i=1∑dpilog2(pi)
在现实中,对于具体数据集来说,需要利用样本的频数来对概率进行估计。依然沿用之前的数据集
D = ( [ X 1 , y 1 ] , [ X 2 , y 2 ] , ⋯ , [ X m , y m ] ) T D=([X_1,y_1],[X_2,y_2],\cdots,[X_m,y_m])^T D=([X1,y1],[X2,y2],⋯,[Xm,ym])T
假设数据集标签有 k k k个类别: s 1 , ⋯ , s k s_1,\cdots,s_k s1,⋯,sk,即 y y y 的k个取值范围,每个类别出现的概率可估算
∣ s j ∣ m \frac{|s_j|}{m} m∣sj∣
其中, ∣ s j ∣ |s_j| ∣sj∣表示类别 s j ( 1 ≤ j ≤ k ) s_j (1\leq j \leq k) sj(1≤j≤k)中样本数, m m m为总样本数,即用 s j s_j sj出现的频数来对概率进行估计,这样数据集 D D D的总体信息熵
E ( s 1 , ⋯ , s k ) = − ∑ j = 1 k ∣ s j ∣ m l o g 2 ∣ s j ∣ m E(s_1,\cdots,s_k)=-\sum\limits_{j=1}^k \frac{|s_j|}{m}log_2 \frac{|s_j|}{m} E(s1,⋯,sk)=−j=1∑km∣sj∣log2m∣sj∣
有了信息熵的概念就好定义信息增益和信息增益率,用某个特征划分数据集之后的信息熵与划分前信息熵的差值称为关于该特征的信息增益(information gain)。假设用特征 f j f_j fj 去划分数据集 D D D, 且设划分后的信息熵为 E ( f j ) E(f_j) E(fj), 于是,关于特征fj的信息增益
G a i n ( f j ) = E ( s 1 , ⋯ , s k ) − E ( f j ) Gain(f_j)=E(s_1,\cdots,s_k)-E(f_j) Gain(fj)=E(s1,⋯,sk)−E(fj)
对于确定的数据集,其在划分前的信息熵是确定的,由公式可以看到划分后 E ( f j ) E(f_j) E(fj)越小, G a i n ( f j ) Gain(f_j) Gain(fj)越大,说明特征 f j f_j fj对划分提供的确定性信息越多,选择该特征作为划分对象后的不确定性程度越小。ID3算法2就是一个经典的决策树学习算法,其核心是在各层级结点都用信息增益作为判断准则进行特征选择,使得在每个被选择的特征对象进行分裂后,都能获得最大的信息增益,树结构的不确定性最小,使得树的平均深度较小,划分效率较高。
由于ID3算法采用信息增益作为分裂判断准则,由熵函数的性质可以发现,信息增益会倾向选择出现两极分化的特征作为优先划分对象,即高度分支特征,然后这类特征在现实中不一定是最优的属性,同时ID3算法只能处理离散特征,对于连续型特征,在划分之前还需要对其进行离散化预处理,为了解决的选择高度分支特征倾向和离散特征局限的问题,便有采用信息增益率作为特征划分标准的C4.5决策树学习算法。
信息增益率(C4.5算法)
与ID3算法取信息增益绝对量作为特征划分标准不同,C4.5算法采用信息增益率准则,信息增益率是在信息增益的基础上加一个惩罚系数用来做平衡调节,当出现高度不均衡分支特征的时候,其信息熵小,信息增益值大,于是给一个较小的惩罚系数,反之给一个较大的惩罚系数。用公式写出来就是
信 息 增 益 率 = 惩 罚 系 数 ∗ 信 息 增 益 信息增益率=惩罚系数*信息增益 信息增益率=惩罚系数∗信息增益
惩罚系数 c c c常定义为数据集 D D D以特征 f f f作为随机变量的熵的倒数,即
c = 1 G ( f ) = 1 − ∑ i = 1 k ∣ D i ∣ ∣ D ∣ l o g 2 ∣ D i ∣ ∣ D ∣ c=\frac{1}{G(f)}=\frac{1}{-\sum\limits_{i=1}^k\frac{|D_i|}{|D|}log_2\frac{|D_i|}{|D|}} c=G(f)1=−i=1∑k∣D∣∣Di∣log2∣D∣∣Di∣1
其中, k k k为特征 f f f的类别数, ∣ D ∣ |D| ∣D∣为数据集 D D D所含样本数, ∣ D i ∣ |D_i| ∣Di∣为特征 f f f的第 i i i类别的所含样本数,且 ∑ i 1 k ∣ D i ∣ = ∣ D ∣ \sum\limits_{i1}^k|D_i|=|D| i1∑k∣Di∣=∣D∣。从公式可以看出,当特征高度分化时,其对应的信息增益值较大,但其倒数较小,惩罚系数较小;反之,惩罚系数较大,惩罚系数恰巧起到一个平衡调节作用。C4.5 算法流程和 ID3 算法流程大致差不多,信息增益和信息增益率都是借用信息论里的知识来作为判定准则,有其局限性,下面要介绍CART算法则是用基尼指数来作为划分标准的,能够更直白的刻画划分优劣的实际情况。
基尼指数(CART算法)
基尼指数(Gini index)用来刻画模型的不纯度,表示一个随机选中的样本被分错的概率,也叫基尼不纯度(Gini impurity),如果被分错了,我们就称其不纯,当然,我们希望这种错误越少越好,也就是模型纯度越高越好,基尼指数越小,模型的不纯度越低,反过来,纯度越高,模型被划分的越好,因此,选择那些基尼指数越小的特征作为划分对象。
假设数据集有 m m m个类别,样本点属于第 i ( 1 ≤ i ≤ m ) i(1\leq i \leq m) i(1≤i≤m) 类别的概率为 p i p_i pi,那么该数据集的基尼指数定义为
G i n i ( p ) = ∑ i = 1 m p i ( 1 − p i ) = 1 − ∑ i = 1 m p i 2 Gini(p)=\sum\limits_{i=1}^mp_i(1-p_i)=1-\sum\limits_{i=1}^mp_i^2 Gini(p)=i=1∑mpi(1−pi)=1−i=1∑mpi2
其中, ∑ i = 1 m p i = 1 \sum\limits_{i=1}^mp_i=1 i=1∑mpi=1。
在CART3决策树学习算法中,如果数据集 D D D 根据特征 f f f被分割成 D 1 , ⋯ , D k D_1,\cdots,D_k D1,⋯,Dk个子数据集,那么在特征 f f f下条件下,数据集 D D D的基尼指数可以写成
G i n i ( D , f ) = ∑ i = 1 k ∣ D i ∣ ∣ D ∣ G i n i ( D i ) Gini(D,f)=\sum\limits_{i=1}^k\frac{|D_i|}{|D|}Gini(D_i) Gini(D,f)=i=1∑k∣D∣∣Di∣Gini(Di)
熵VS基尼指数
既然熵和基尼指数都可以用来作最优特征选择判断,下面通过二分类来看一下两者的差别
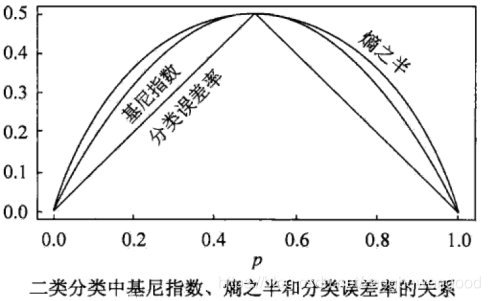
从两者在二分类中的表现曲线看到,熵之半曲线的凸性要强于基尼指数曲线的凸性,且当概率为0.5的时候,两者均达到最大值。
剪枝
关于特征划分以及划分的三种标准已经介绍清楚了,按标准来,在有限的样本空间总是可以划分完毕,但有时候,我们不能让一棵树无限生长,即使这棵树对已有的数据集划分的一清二楚,但是对未知的数据集却有可能表现的非常糟糕,这就是人们常说的过拟合,这时候就需要对其进行剪枝,使得模型的泛化能力更强。养过向日葵的朋友知道,向日葵是一种向上生长在顶端开花的植物,如果新芽从侧面长出来,就要掐掉,否则向日葵就会开出满天星的效果。决策树的剪枝与养花的剪枝技术如出一辙,决策树里面的剪枝是指用父结点代替其下面的所有子结点作为一个叶结点,下面两个小图比较形象的刻画剪枝过程
对比上下两个树形结构图发现,后者直接用B结点代替掉了其子结点 D 和子结点E,并且自己作为一个叶结点,使得树的结构更加简单4,剪枝就是用更加简单的树结构去替代更加复杂的树结构,然后评估这种替代带来的利弊。常用的剪枝技术有先剪枝和后剪枝。
先剪枝是指增加一些划分终止的条件,提前结束树的生长,这与生物学中为了维护向日葵的顶端优势而先把侧芽掐剪掉是一回事。比如,事先设定分裂的阈值(信息增益值,信息增益率,基尼指数),当分裂前后的所求得的参数小于阈值就不再划分了,该结点作为叶结点。
后剪枝是指在一棵树生长“完全”后再对其进行剪枝,这与你平时看到的园艺工人用一个大大的剪刀把道路两旁景观树木修剪成某形状是一回事。
依然用上面的两个树图来说明,如果是从第一个图到第二个图是后剪枝,而跳过第一个图直接到第二个图是先剪枝。现实中,往往采用后剪枝办法,常见的后剪枝技术有REP(Reduced Error Pruning)方法,PEP(Pessimistic Error Pruning)方法,CCP(Cost-Complexity Pruning)方法及EBP(Error-Base-Pruning)方法。
优缺点及适用场景
- 优点
1,非常形象,具有层次感,易于理解,解释起来也简单;
2,可以将决策过程可视化,让输入到输出看起来有理有据;
3,效率高,决策树一旦构建就能够反复使用,每一次预测的最大计算次数不超过决策树的深度。
4,能够处理数值型变量和类别型变量;
5,能够处理多输出问题;
- 缺点
1,有时候树太深太枝繁叶茂容易导致过拟合;
2,对异常数据比较敏感,尤其对不平衡的数据集容易表现出偏爱;
3,容易出现过拟合。
4,当类别太多时,错误可能就会增加的比较快。
决策树属于有监督的算法,常用来提炼有用的规则,某种知识的探测,探索特征与标签的映射关系,探索各特征对标签影响相对大小等。
参考文献
1,https://blog.csdn.net/xbinworld/article/details/44660339
2,https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html
3,https://zhuanlan.zhihu.com/p/268619723?utm_source=wechat_session

热力学中的热熵是表示分子状态混乱程度的物理量。 ↩︎
由J.Ross Quinlan于20世纪70年代末期和80年代初提出。 ↩︎
CART是classification and regression tree 的缩写,意味着CART还可以处理回归问题。 ↩︎
模型的复杂度往往用正则化项或者惩罚项来刻画,模型越复杂,其取值越大,风险越大,泛化能力越弱。 ↩︎
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!