flink-sql查询配置与性能优化参数详解-1.13
1. 版本说明
本文档内容基于flink-1.13.x,其他版本的整理,请查看本人博客的 flink 专栏其他文章。
2. 查询配置
默认情况下,Table 和 SQL API 已经配置好了可以接受的性能对应的配置。
取决于 table 程序的需要,可能还需要配置一些必要的参数给优化器。比如,无界流程序可能需要确定必要的状态大小上限。
2.1. 概述
在 table environment 对象中, TableConfig 对象提供了当前会话的配置选项。
对于公共和重要的配置选项, TableConfig 对象提供了 getter 和 setter 方法,详情请查看内置文档。
对于更近异步的配置,用户可以直接访问底层的 key-value map 表。下面的章节列出了所有可用的选项,以用于调整 Flink Table 和 SQL API 程序。
注意:因为配置在优化操作期间,可能会在不同的时间点被读取,所以需要在实例化完 table environment 后尽快设置。
java
// 实例化 table environment
TableEnvironment tEnv = ...// 访问 configuration
Configuration configuration = tEnv.getConfig().getConfiguration();
// 设置底层 key-value 选项
configuration.setString("table.exec.mini-batch.enabled", "true");
configuration.setString("table.exec.mini-batch.allow-latency", "5 s");
configuration.setString("table.exec.mini-batch.size", "5000");
scala
// 实例化 table environment
val tEnv: TableEnvironment = ...// 访问 configuration
val configuration = tEnv.getConfig().getConfiguration()
// 设置底层 key-value 选项
configuration.setString("table.exec.mini-batch.enabled", "true")
configuration.setString("table.exec.mini-batch.allow-latency", "5 s")
configuration.setString("table.exec.mini-batch.size", "5000")
SQL CLI
Flink SQL> SET table.exec.mini-batch.enabled = true;
Flink SQL> SET table.exec.mini-batch.allow-latency = 5s;
Flink SQL> SET table.exec.mini-batch.size = 5000;
2.2. 任务执行配置
以下选项可用于调优查询执行的性能。
| 键 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| table.exec.async-lookup.buffer-capacity Batch Streaming | 100 | Integer | 异步查找join触发的最大异步i/o操作的数量。 |
| table.exec.async-lookup.timeout Batch Streaming | 3 min | Duration | 异步操作完成的异步超时时间。 |
| table.exec.disabled-operators Batch | (none) | String | 主要为了测试。用逗号分隔的算子名称列表,买个名称代表一类禁止操作的算子。可以被禁止的算子包括:“NestedLoopJoin”, “ShuffleHashJoin”, “BroadcastHashJoin”, “SortMergeJoin”, “HashAgg”, “SortAgg”。默认不禁止任何算子。 |
| table.exec.mini-batch.allow-latency Streaming | 0 ms | Duration | MiniBatch 缓存输入数据的最大延迟时间。MiniBatch 可以优化数据缓存,以减少state状态访问。MiniBatch 在允许的时间间隔内收到最大的缓存数据量时触发。注意:如果table.exec.mini-batch.enabled设置为true,该值必须大于0。 |
| table.exec.mini-batch.enabled Streaming | false | Boolean | 是否开启MiniBatch 优化。MiniBatch 可以优化数据缓存,以减少state状态访问。默认false禁用。可以设置为true来开启。注意:如果开启mini-batch,则必须设置’table.exec.mini-batch.allow-latency’和’table.exec.mini-batch.size’。 |
| table.exec.mini-batch.size Streaming | -1 | Long | MiniBatch 可以缓存的最大输入数据数量。MiniBatch 可以优化数据缓存,以减少state状态访问。MiniBatch 在允许的时间间隔内收到最大的缓存数据量时触发。注意:如果table.exec.mini-batch.enabled设置为true,该值必须为正值。 |
| table.exec.resource.default-parallelism Batch Streaming | -1 | Integer | 设置所有算子的默认并行度(比如aggregate,join,filter)。该配置的优先级高于StreamExecutionEnvironment (实际上,该配置会覆盖StreamExecutionEnvironment 设置的并行度)。-1表示不设置默认并行度,然后使用StreamExecutionEnvironment设置的并行度。 |
| table.exec.shuffle-mode Batch | ALL_EDGES_BLOCKING | String | 设置执行的shuffle模式。 可用值有: ALL_EDGES_BLOCKING: 所有edges使用阻塞shuffle. FORWARD_EDGES_PIPELINED: Forward edges will use pipelined shuffle, others blocking. POINTWISE_EDGES_PIPELINED: Pointwise edges will use pipelined shuffle, others blocking. Pointwise edges include forward and rescale edges. ALL_EDGES_PIPELINED: All edges will use pipelined shuffle. batch: 和 ALL_EDGES_BLOCKING 一样,过期值。 pipelined:和 ALL_EDGES_PIPELINED 一样,过期值。 注意:阻塞shuffle表好似数据在被发送到消费者之前,将会全部产生,pipelined shuffle表示数据一旦产生,就会立即被发送给消费者。 |
| table.exec.sink.not-null-enforcer Batch Streaming | ERROR | 枚举 可用值: ERROR DROP | 决定当 NOT NULL 字段遇到 null 值时,flink 怎么处理。 可用值: ERROR:NOT NULL 字段遇到 null 值时抛出运行时异常。 DROP:NOT NULL 字段遇到 null 值时直接丢弃数据。 |
| table.exec.sink.upsert-materialize Streaming | AUTO | 枚举 可用值: NONE AUTO FORCE | 由于分布式系统中的 shuffle 会造成 ChalgeLog 数据的乱序,所以 sink 接收到的数据可能在全局的 upsert 中乱序,所以要在 upsert sink 之前添加一个 upsert 物化算子。该算子接收上游 changelog 数据,并且给下游生成一个 upsert 视图。 默认情况下,在唯一 key 遇到分布式乱序时,该物化算子会被添加,也可以选择不物化(NONE),或者是强制物化(FORCE)。 可选值有:NONE、AUTO、FORCE。 |
| table.exec.sort.async-merge-enabled Batch | true | Boolean | 是否异步合并排序的溢出文件。 |
| table.exec.sort.default-limit Batch | -1 | Integer | 在使用order by语句后,用户没有使用limit语句,则默认使用该设置limit值。-1表示忽略该限制。 |
| table.exec.sort.max-num-file-handles Batch | 128 | Integer | 外部归并排序的最大扇入文件数。该配置限制每个算子操作的文件数量。如果该值设置过小,可能会导致中间合并。但是如果设置过大,则会导致被同时打开的文件数太多,占用内存,并导致随机读取。 |
| table.exec.source.cdc-events-duplicate Streaming | false | Boolean | 指定任务中的CDC(更改数据获取)source产生重复更改事件时,框架是否需要进行去重,获取一致性结果。CDC source会产生所有的更改事件,包括:INSERT/UPDATE_BEFORE/UPDATE_AFTER/DELETE。比如:kafka source使用Debezium 格式化。该配置默认值为false。 然而,有重复更改事件是一种常见的情况。因为CDC工具(比如Debezium),在遇到失败时,会使用至少一次语义,因此,在异常情况下,Debezium 会交付重复的更改事件到kafka,然后flink将获取到重复的时间。这可能会导致flink查询产生错误的结果,或者是不期望遇到的异常。 因此,如果CDC工具设置的至少一次语义,则要求更改此配置。开启该配置要求CDC cource定义PRIMARY KEY主键。主键将用于对更改事件去重,并且生成有状态的changelog流。 |
| table.exec.source.idle-timeout Streaming | 0 ms | Duration | 当一个source在超时时间内没有接收到任何数据时,它将被标记为临时空闲。这允许下游任务在其空闲时不需要等待来自该source的水印而发送其水印。缺省值为0,表示不开启source空闲检测。 |
| table.exec.spill-compression.block-size Batch | 64 kb | MemorySize | 溢出数据时用于压缩的内存大小。内存越大,压缩比越高,但是作业消耗的内存资源也更多。 |
| table.exec.spill-compression.enabled Batch | true | Boolean | 是否压缩溢出数据。目前,我们只支持对sort、hash-agg和hash-join算子压缩溢出数据。 |
| table.exec.state.ttl Streaming | 0 ms | Duration | 设置状态保留的最小空闲时间,比如:状态未被更新。状态在空闲时间小于设置的最小时间时永远不会被清除,并且将会在空闲时间超过设置值后被清除,默认为永远不清除状态。注意:清除状态要求状态请求额外的空间时才会发生。默认值为0,表示永远不清除状态。 |
| table.exec.window-agg.buffer-size-limit Batch | 100000 | Integer | 设置group window agg算子中使用的窗口元素缓冲区大小限制。 |
2.3. 优化配置
以下配置可用于调整查询优化器,以获得更好的执行计划。
| 键 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| table.optimizer.agg-phase-strategy Batch Streaming | AUTO | String | AUTO:不指定聚合策略。根据情况选择两阶段聚合或者是一阶段聚合。 TWO_PHASE:指定使用两阶段聚合,两阶段包括:localAggregate和globalAggregate。如果聚合不支持两阶段聚合优化,则会采用一阶段聚合。 ONE_PHASE:指定使用一阶段聚合,只包括:CompleteGlobalAggregate。 |
| table.optimizer.distinct-agg.split.bucket-num Streaming | 1024 | Integer | 配置切分distinct聚合时的bucket桶的总数。该数字用于第一阶段聚合,其用来通过“hash_code(distinct_key)%BUCKET_NUM”计算出额外的分组key,以将数据打散到不同子任务。 |
| table.optimizer.distinct-agg.split.enabled Streaming | false | Boolean | 告诉优化器,是否将 distinct 聚合切分为两级,比如:COUNT(DISTINCT COL)、SUM(DISTINCT COL)。第一级聚合会根据 distinct_key 计算出来的 hashcode 值和 bucket 数值将数据进行 shuffle。该优化在 distinct 聚合发生数据倾斜时十分有用,并且可以增加任务的性能。默认为 false。 |
| table.optimizer.join-reorder-enabled Batch Streaming | false | Boolean | 在优化器中启用join重新排序。默认为禁用。 |
| table.optimizer.join.broadcast-threshold Batch | 1048576 | Long | 当执行 join 时,可以将表的所有数据广播到所有 worker 节点的最大字节数。设置该值为 -1 可以禁用广播。 |
| table.optimizer.multiple-input-enabled Batch | true | Boolean | 当设置为true时,优化器将会合并pipelined shuff 到一个多输入算子,以减少shuff,优化性能。默认值为true。 |
| table.optimizer.reuse-source-enabled Batch Streaming | true | Boolean | 当设置为true时,优化器将尝试发现重复的表source,然后重用他们。要启用该设置,必须设置table.optimizer.reuse-sub-plan-enabled为true。 |
| table.optimizer.reuse-sub-plan-enabled Batch Streaming | true | Boolean | 当设置为true时,优化器将尝试发现重复的子任务,然后重用他们。 |
| table.optimizer.source.predicate-pushdown-enabled Batch Streaming | true | Boolean | 当设置为true时,优化器将谓词下推为 FilterableTableSource,默认为true。 |
2.4. 表配置
以下选项可用于调整表计划器的行为。
| 键 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| table.dml-sync Batch Streaming | false | Boolean | 指定DML任务(比如插入操作)为异步/同步执行。默认为异步执行,因此可以同时提交多个DML任务。如果设置为true,则插入操作会等待任务完成才会结束。 |
| table.dynamic-table-options.enabled Batch Streaming | false | Boolean | 是否启用用于动态表的 OPTIONS 提示,如果禁用,则指定 OPTIONS 之后会抛出异常。 |
| table.generated-code.max-length Batch Streaming | 64000 | Integer | 指定一个阈值,将生成的代码拆分为子函数调用。Java的最大方法长度为64kb。如果有必要,则可以通过该参数设置更细的粒度。 |
| table.local-time-zone Batch Streaming | default | String | 定义当前会话的本地时间时区id。该值用于转化或转化为TIMESTAMP WITH LOCAL TIME ZONE时间类型。在内部实现中,timestamps with local time zone通常表示UTC时区(0时区)。然而,当将该类型转化为不包含时区的数据类型(比如TIMESTAMP、TIME、简单的STRING)时,将会用到会话时区设置。该值可以使用完全的名称(比如:“America/Los_Angeles”),也可以使用自定义的时区ID(比如:“GMT+08:00”)。 |
| table.planner Batch Streaming | BLINK | 枚举 可用值: BLINK、OLD | 使用“blink”或“old”计划器,默认为blink计划器。对于TableEnvironment来说,该设置用于创建TableEnvironment对象,而且对象创建之后无法修改该设置。注意:old计划器将会在flink 1.14版本中移除,因此该配置将会被废弃。 |
| table.sql-dialect Batch Streaming | default | String | 定义转化SQL查询的方言。不同的方言支持不同的SQL语法,目前支持default和hive方言。 |
2.5. SQL Client配置
下面的配置可以调整 sql client 的行为。
| 键 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| sql-client.execution.max-table-result.rows Batch Streaming | 1000000 | Integer | 设置 table 模式的最大缓存行数。如果数据行数超过了指定的值,则会采用 FIFO 形式提取数据。 |
| sql-client.execution.result-mode Batch Streaming | TABLE | 枚举 可用值: TABLE CHANGELOG TABLEAU | 展示查询结果的模式,可用值为:table、tableau、changelog。 table 模式会在内存中物化结果,并且在一个常规、分页的表视图中展示他们。 changelog 模式不会物化结果,并且会展示连续查询产生的结果流。 tableau 模式更像是一个传统的方式,将结果直接按照 tableau 格式展示到屏幕上。 |
| sql-client.verbose Batch Streaming | false | Boolean | 是否输出冗余的输出。如果设置为 true,将会打印异常堆栈信息,否则只会输出异常原因。 |
3. 性能调整
3.1. 介绍
SQL是数据分析中使用最广泛的语言。Flink的Table API和SQL使用户可以用更少的时间和精力去开发高效的流分析应用程序。
此外,Flink Table API和SQL都被进行了有效的优化,集成了大量查询优化和算子优化实现。但是并不是所有的优化都是默认启用的,所以对于某些查询任务,可以通过开启一些配置来提高性能。
下面我们将介绍一些有用的优化选项和流聚合的内部结构,这些配置在某些情况下会带来很大的性能优化。
下面提到的流聚合优化现在都支持分组聚合和窗口TVF聚合。
3.2. MiniBatch聚合
默认情况下,分组聚合算子会逐个处理输入记录,即:
- 从
state状态读取累加器 - 将记录
累加/撤回到累加器 - 将
累加器写回状态 - 下一个记录将从(1)再次进行处理。
这种处理模式可能会增加 StateBackend 的开销(特别是 RocksDB StateBackend)。此外,生产中常见的数据倾斜会使问题更加严重,使任务更容易处于反压状态。
MiniBatch 微批处理聚合的核心思想是将大量输入缓存到聚合算子内部的缓冲区中。当输入记录集合被触发进行处理时,每个key只需要访问一次状态。这可以显著减少状态开销并获得更好的吞吐量。
但这可能会增加一些延迟,因为它会先缓冲一些记录而不是立即处理它们。这是吞吐量和延迟之间的权衡。
下图解释了MiniBatch处理聚合如何减少状态操作。
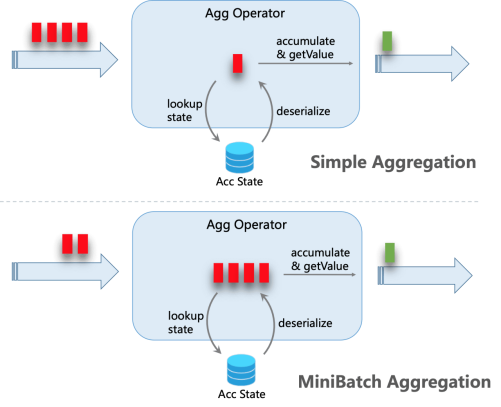
解释:上面是一个记录读取一次状态,写入一次状态。下面是多个相同key的记录缓存之后,访问一次状态,写入一次状态。
默认情况下,分组聚合会禁用 MiniBatch 优化。
为了启用此优化,需要设置 table.exec.mini-batch.enabled、table.exec.mini-batch.allow-latency、table.exec.mini-batch.size。
详情请参阅查询配置页面。
无论上述配置如何,窗口 TVF 聚合始终启用 MiniBatch 优化。窗口 TVF 聚合缓冲区记录在托管内存中,而不是 JVM 堆中,因此没有过载 GC 或 OOM 问题的风险。
下面的示例展示如何启用这些选项。
java
// 实例化 table environment
TableEnvironment tEnv = ...// 访问 flink 配置
Configuration configuration = tEnv.getConfig().getConfiguration();
// 设置底层 key-value 配置
configuration.setString("table.exec.mini-batch.enabled", "true"); // 开启 mini-batch 优化
configuration.setString("table.exec.mini-batch.allow-latency", "5 s"); // 缓存输入数据 5 秒
configuration.setString("table.exec.mini-batch.size", "5000"); // 每个聚合操作任务可以缓存的最大数据条数为 5000 条
scala
// 实例化 table environment
val tEnv: TableEnvironment = ...// 访问 flink 配置
val configuration = tEnv.getConfig().getConfiguration()
// 设置底层 key-value 配置
configuration.setString("table.exec.mini-batch.enabled", "true") // 开启 mini-batch 优化
configuration.setString("table.exec.mini-batch.allow-latency", "5 s") // 缓存输入数据 5 秒
configuration.setString("table.exec.mini-batch.size", "5000") // 每个聚合操作任务可以缓存的最大数据条数为 5000 条
sql
set 'table.exec.mini-batch.enabled' = 'true'; -- 启用mini-batch
set 'table.exec.mini-batch.allow-latency' = '5 s'; -- 使用 5s 时间去缓存输入记录
set 'table.exec.mini-batch.size' = '5000'; -- 每个聚合算子任务最多可以缓存的最大记录数量
3.3. Local-Global
local-global 算法通过将分组聚合分为两个阶段来解决数据倾斜问题,即先在上游进行局部聚合,然后在下游进行全局聚合,类似于 MapReduce 中的 Combine + Reduce 模式。例如有以下 SQL:
SELECT color, sum(id)
FROM T
GROUP BY color;
数据流中的记录可能是倾斜的,因此一些聚合算子的实例必须处理比其他实例多得多的记录,这就导致了热点问题。
本地聚合可以在上游先将具有相同键的一定数量的输入积累到单个累加器中,全局聚合将只接收少量的累加器,而不是大量的原始输入。
这可以显著降低网络shuffle和状态访问的成本。本地聚合每次累积的输入记录数量基于微批聚合的时间间隔。这意味着本地聚合依赖于启用微批聚合。
下图显示本地-全局聚合如何提高性能。
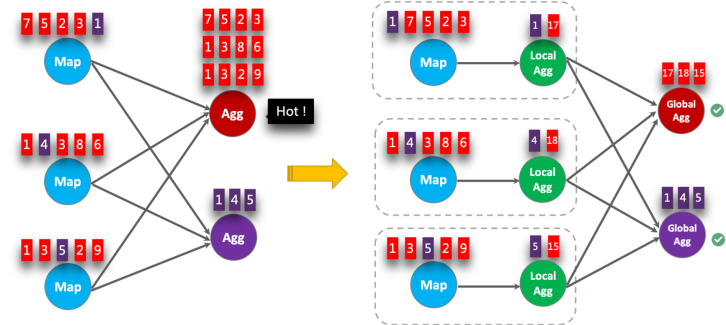
解释:左边聚合,聚合算子会收集所有输入,因此上面的聚合算子收到很多原始记录,造成了热点问题。
右边聚合,上游的本地聚合会先将输入在进行和聚合算子相同的操作,将输入根据key来进行聚合,下游的聚合算子只需要接收上游本地聚合之后的累加器即可,因此可以显著减少下游聚合算子的输入数据量。
下面的示例说明如何启用本地-全局聚合。
java
// 实例化 table environment
TableEnvironment tEnv = ...// 访问 flink 配置
Configuration configuration = tEnv.getConfig().getConfiguration();
// 设置底层 key-value 配置
configuration.setString("table.exec.mini-batch.enabled", "true"); // 本地-全局聚合依赖于开启微批聚合
configuration.setString("table.exec.mini-batch.allow-latency", "5 s");
configuration.setString("table.exec.mini-batch.size", "5000");
configuration.setString("table.optimizer.agg-phase-strategy", "TWO_PHASE"); // 启用两阶段聚合策略,比如:本地-全局聚合
scala
// 实例化 table environment
val tEnv: TableEnvironment = ...// 访问 flink 配置
val configuration = tEnv.getConfig().getConfiguration()
// 设置底层 key-value 配置
configuration.setString("table.exec.mini-batch.enabled", "true") // 本地-全局聚合依赖于开启微批聚合
configuration.setString("table.exec.mini-batch.allow-latency", "5 s")
configuration.setString("table.exec.mini-batch.size", "5000")
configuration.setString("table.optimizer.agg-phase-strategy", "TWO_PHASE") // 启用两阶段聚合策略,比如:本地-全局聚合
sql
set 'table.exec.mini-batch.enabled' = 'true'; -- 本地-全局聚合依赖于开启微批聚合
set 'table.exec.mini-batch.allow-latency' = '5 s'; -- 使用5s时间去缓存输入记录
set 'table.exec.mini-batch.size' = '5000'; -- 每个聚合算子任务最多可以缓存的最大记录数量
set 'table.optimizer.agg-phase-strategy' = 'TWO_PHASE'; -- 启用两阶段聚合策略,比如:本地-全局聚合
3.4. 切分DISTINCT聚合
本地-全局优化对于一般聚合(SUM、COUNT、MAX、MIN、AVG)的数据倾斜是有效的,但在处理 distinct 聚合时性能并不理想。
例如,如果我们想要分析今天有多少独立用户登录。我们可能会进行以下查询:
SELECT day, COUNT(DISTINCT user_id)
FROM T
GROUP BY day;
COUNT DISTINCT 不擅长于减少记录,如果 DISTINCT 键(即user_id)的值是稀疏的,即使启用了本地-全局优化,也没有多大帮助。
因为累加器仍然包含几乎所有的原始记录,全局聚合将成为瓶颈(大多数重量级累加器都由一个任务处理,即在同一天)。
切分 distinct 聚合优化的思想是将不同的聚合(例如 COUNT(distinct col))分解为两个层次。第一个聚合按分组键和附加的bucket总数进行shuffle。
bucket 键使用 HASH_CODE(distinct_key) % BUCKET_NUM 计算。默认情况下,BUCKET_NUM 是 1024
,可以通过 table.optimizer.distinct-agg.split.bucket-num 配置。
第二个聚合按原始分组键进行 shuffle,并使用 SUM 聚合来自不同 bucket 的 COUNT DISTINCT 值。因为相同的 distinct 字段值只会在相同的bucket中计算,所以转换是等价的。
bucket 键作为一个额外的分组键,分担分组键中热点的负担。bucket键使任务具有可伸缩性,以解决 distinct 聚合中的数据倾斜/热点问题。
拆分不同的聚合后,上面的查询将被自动重写为下面的查询:
SELECT day, SUM(cnt)
FROM (SELECT day, COUNT(DISTINCT user_id) as cntFROM TGROUP BY day, MOD(HASH_CODE(user_id), 1024))
GROUP BY day;
下图显示分割 distinct 聚合如何提高性能(假设颜色代表天数,字母代表 user_id)。
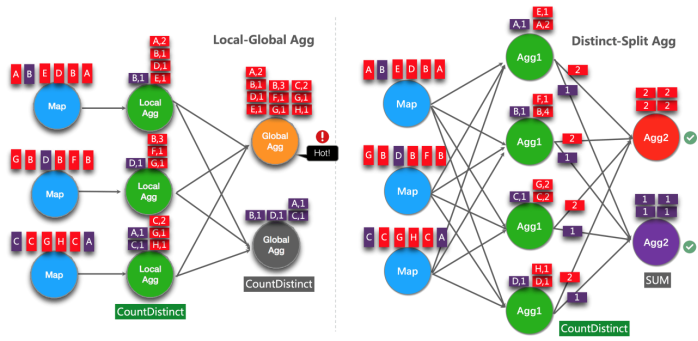
解释:左图聚合,本地聚合会先对相同键进行聚合,以减少数据量,全局聚合的一个算子也还是会收到所有他所应该聚合的所有同一天的累加器。
右图聚合,agg1 设置 bucket 为4,然后将 map 的输入值通过天的 hash 和 bucket 取余,放到不同的 agg1 并行度,agg1 接收到数据后,进行聚合。
agg2 只需要接收每个 agg1 里不同颜色中 user_id 的数量即可(一个颜色中有两个 user_id,就传递数字 2),然后对接收到的数量进行累加即可。
注意:上例只是一个简单的示例。除此之外,Flink还支持分割更复杂的聚合查询,例如,多个 distinct 聚合具有不同的 distinct 键(例如 COUNT(distinct a), SUM(distinct b)),
与其他非不同的聚合(例如SUM, MAX, MIN, COUNT)一起使用。
目前,分割优化不支持包含用户自定义的 AggregateFunction 的聚合。
下面的示例演示如何启用分割distinct聚合优化。
java
// 实例化 table 环境
TableEnvironment tEnv = ...tEnv.getConfig() // 访问高级配置.getConfiguration() // 设置底层 key-value 配置.setString("table.optimizer.distinct-agg.split.enabled", "true"); // 开启 distinct 切分聚合
scala
// 实例化 table 环境
val tEnv: TableEnvironment = ...tEnv.getConfig // 访问高级配置.getConfiguration // 设置底层 key-value 配置.setString("table.optimizer.distinct-agg.split.enabled", "true") // 开启 distinct 切分聚合
sql
set 'table.optimizer.distinct-agg.split.enabled' = 'true' -- 启用distinct聚合分割
3.5. 在DISTINCT上使用FILTER改进
在某些情况下,用户可能需要计算来自不同维度的UV(唯一访问者)的数量,例如来自Android的UV,来自iPhone的UV,来自Web的UV和总UV。很多用户会选择 CASE WHEN 来实现这个需求,例如:
SELECTday,COUNT(DISTINCT user_id) AS total_uv,COUNT(DISTINCT CASE WHEN flag IN ('android', 'iphone') THEN user_id ELSE NULL END) AS app_uv,COUNT(DISTINCT CASE WHEN flag IN ('wap', 'other') THEN user_id ELSE NULL END) AS web_uv
FROM T
GROUP BY day;
建议使用 FILTER 语法而不是 CASE WHEN。因为 FILTER 更符合SQL标准,且能获得更大的性能优化。FILTER 是用于聚合函数的修饰符,用于限制聚合中使用的值。将上面的示例替换为 FILTER 修饰符,如下所示:
SELECTday,COUNT(DISTINCT user_id) AS total_uv,COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('android', 'iphone')) AS app_uv,COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('wap', 'other')) AS web_uv
FROM T
GROUP BY day
Flink SQL优化器可以识别相同 distinct 键上的不同筛选器参数。例如,在上面的示例中,所有三个 COUNT DISTINCT 都在 user_id 列上。
这样,Flink就可以只使用一个共享状态实例而不是三个状态实例来减少状态访问次数和状态大小。在某些任务中可以获得显著的性能优化。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!