C++实现读取多种编码格式文本文件
Unicode字符集
首先明确一个概念:字符集(Charset)和字符编码(Character Encoding)
字符集,表示的可以是字符的一个集合。比如“中文”就是一个字符集,不过这样描述一个字符集并不准确。想要更精确一点,我们可以说,“第一版《新华字典》里面出现的所有汉字”,这是一个字符集。这样,我们才能明确知道,一个字符在不在这个集合里面。比如,我们日常说的 Unicode,其实就是一个字符集,包含了 150 种语言的 14 万个不同的字符。Unicode字符集包括了我们常用ASCII码,即用0-127来表示控制字符、数字、英文符号、英文大小写,常用汉字的编码范围为0x4E00~0x9FBF,同时能够支持表示日文、韩文等其他语言的字符。
unicode字符集范围分配:https://blog.csdn.net/thomashtq/article/details/39081233
汉字的unicode范围:https://www.qqxiuzi.cn/zh/hanzi-unicode-bianma.php
而字符编码则是对于字符集里的这些字符,怎么一一用二进制表示出来的一个字典。我们上面说的 Unicode,就可以用 UTF-8、UTF-16,乃至 UTF-32 来进行编码,存储成二进制。
字符编码
字符编码定义了字符集在计算机中的二进制存储方式,常用的编码方式有utf-8编码,utf-16编码,utf-32编码。utf-8编码用1-6个字节来表示unicode字符集中的所有字符,utf-16占用2个字节或者4个字节,utf-32占用4个字节。
utf-8编码
“UTF-8是针对Unicode的一种可变长度字符编码,它可以来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理ASCII字符的软件无须或只进行少部份修改后,便可继续使用。”这句话的意思是ASCII码用一个字节表示的字符,utf-8编码后仍然用一个字节表示。utf-8编码规则如下:
1、对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2、对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。

下面以汉字“是”为例,"是“的unicode码为0x662F(01100110 00101111),可以发现0x662F处在第三行的范围内(0000 0800 - 0000 FFFF),因此"是“的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从"是“的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。编码后的为E698AF(11100110 1001100 10101111)
下面看一下,对”wildweeds是一个努力的男生“utf-8编码后的二进制流,使用的查看软件为WinHex.exe。

有的文本软件(比如Windows记事本)在创建utf-8编码文件时会加上一个bom头(EF BB BF)来方便识别,一共3个字节。使用WinHex查看:

从上面可以得知,英文字符占用一个字节,大多数中文字符占用3个字节,”wildweeds是一个努力的男生“这句话里有9个英文字符和8个中文字符,于是可以得到不带bom头的文件大小为9+8×3=33(bytes),带有bom头的文件大小为9+8×3+3=36(bytes)。
utf-16 编码
utf-16编码也是unicode字符集编码的一种,采用两个字节或者4个字节来编码一个字符。也就是unicode字符集中小于等于两个字节的字符采用双字节进行编码,大于两个字节的字符采用2个双字节进行编码。于是原来的ASCII码采用双字节表示,例如字符’a’的十六进制ASCII码为0x61,编码后为0x0061,大部分汉字的unicode字符都能用双字节表示,于是我们所知的大部分汉字的utf-16编码即为unicode字符。查询unicode字符集,可以得到如下汉字的unicode的字符:
| 汉字 | unicode |
|---|---|
| 是 | 0x662F |
| 一 | 0x4E00 |
| 个 | 0x4E2A |
| 努 | 0x52AA |
| 力 | 0x529B |
| 的 | 0x7684 |
| 男 | 0x7537 |
| 生 | 0x751F |
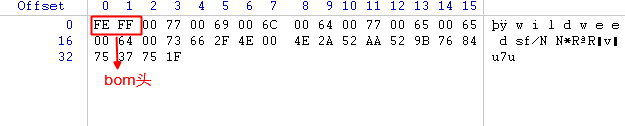
我们都知道,对于单个字节而言,不存在字节顺序的问题,对于双字节、四字节和八字节则存在大小端的问题,因此为了区分大小端,utf-16编码有一个bom(byte order mark)头用来标识字节流的顺序。utf-16的bom头为0xFEFF,大端是读取得到的字节流为FE FF,小端模式下读取到的为FF FE。对“wildweeds是一个努力的男生”采用utf-16编码结果如下:
utf16 BE编码(大端):
utf16 LE编码(小端):
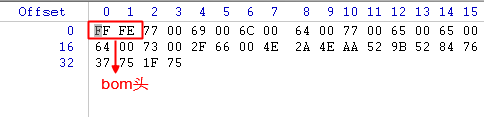
采用utf-16编码时中文字符和英文字符都占用两个字节,bom头占用两个字节,因此文件大小为(9+8)*2+2=36(bytes)。
部分内容参考以下博文:https://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
多编码格式文件读取
从上面我们可以看到,文本文件的编码方式有UTF-8,UTF-8 BOM,UTF-16 BE,UTF-16 LE等方式,下面写一个简单的程序来自适应读取这四种编码格式的文件,由于大部分笔记本电脑都是小端字节序,因此需要将大端字节序转换成小端字节序。
std::string 接收UTF-8编码格式,用std::cout输出到屏幕;
std::wstring接收宽字符UTF-16编码格式,用std::wcout输出到屏幕。
#include WinHex与不同格式文件下载地址
以上是我学习汉字编码时对所查阅资料的一些整理,如果有叙述错误或者不准确的地方,还请批评指正!大家一起学习进步!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!