AliExpress基于Flink的广告实时数仓建设
点击上方蓝色字体,选择“设为星标”
回复"面试"获取更多惊喜
大数据面试提升私教训练营上线

Hi,我是王知无,一个大数据领域的原创作者。
放心关注我,获取更多行业的一手消息。
摘要:实时数仓以提供低延时数据指标为目的供业务实时决策,本文主要介绍基于Flink的广告实时数仓建设,主要包括以下内容:
1. 建设背景
2. 技术架构
3. 数仓架构
4. 实时OLAP
5. 实时保障
6. 未来规划
建设背景
广告是目前互联网流量变现的一种重要手段,广告投放的优化很大程度上依赖于广告效果数据,依托于广告曝光、点击、消耗、订单等指标调整广告投放策略,以达到最优投放效果。前期主要提供T+1效果数据,投放策略往往需要第二天才能做出调整,不能及时做出投放优化,特别在一些大促场景,实时优化显得尤为重要,需要及时调整例如人群、地域、出价等策略,以此为背景建设实时数据链路。
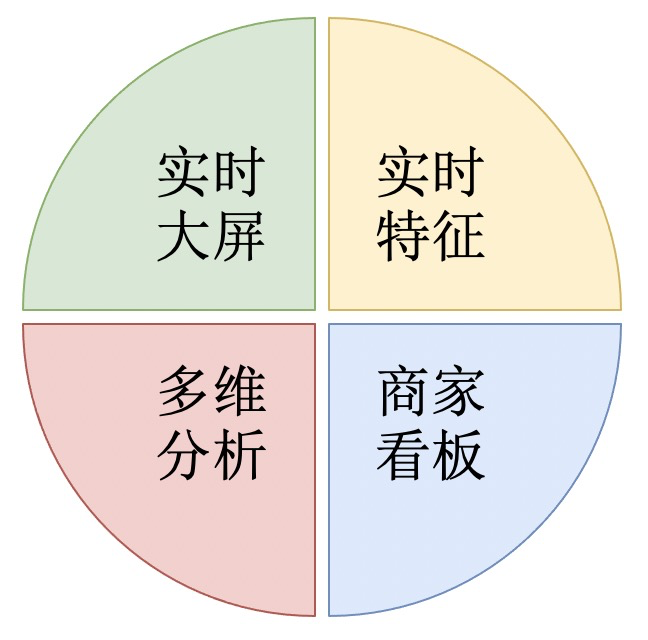
目前实时数据的场景主要有以下几种:
实时大屏:提供给运营、产品使用,展示核心的业务指标:曝光、点击、消耗等数据。
实时特征:提供给算法使用,统计用户维度的行为数据。
商家看板:提供给商家使用,展示商家的在不同维度的曝光、点击、消耗等数据。
多维分析:提供给运营、分析师使用,实时分析广告数据。
技术架构
依托新一代实时计算引擎Flink的兴起,在超高性能、数据一致性保障、SQL化编程方式等特点下推动了实时数仓的发展。
当前的整体技术架构图如下:
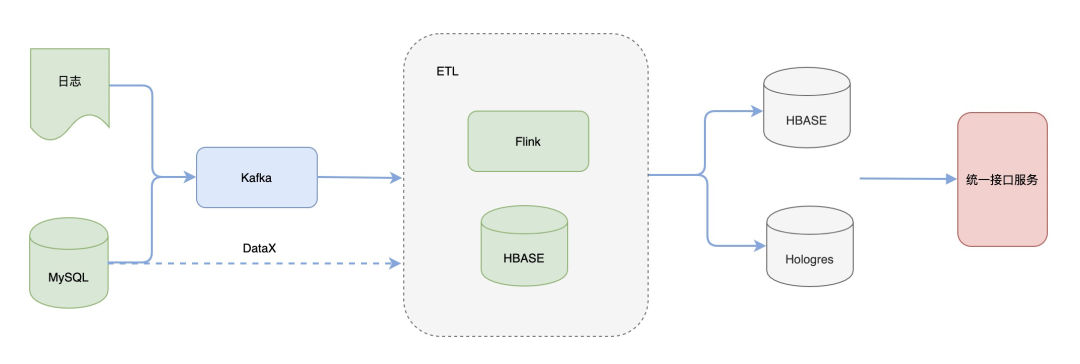
在数据源侧,一方面服务器日志数据与MySQL变更数据作为数仓的数据源,会被采集消息队列Kafka中;另外一方面MySQL 中的数据会通过DataX离线方式同步到HBASE中,通常是在维度建设初始化使用;
在数据加工侧,使用Flink作为计算引擎,HBASE作为维表存储数据库,Flink任务在处理的过程中会做一些数据解析、规范化、打宽、聚合等操作;
在数据服务侧,使用两种不同的存储引擎HBASE与Hologres,HBASE提供KV查询,应用于实时大屏、商家看板等固化查询场景, Hologres用于在线分析,应用于多维分析等场景,提供多维分析能力。二者由统一数据接口服务封装,对外提供查询。
数仓架构
数仓的分层搭建需要从复用、成本、质量、扩展性等方面去考虑,实时数仓的搭建,包括层次划分、命名、主题域划分、数据域划分与离线相差不大,目前划分层次如下:
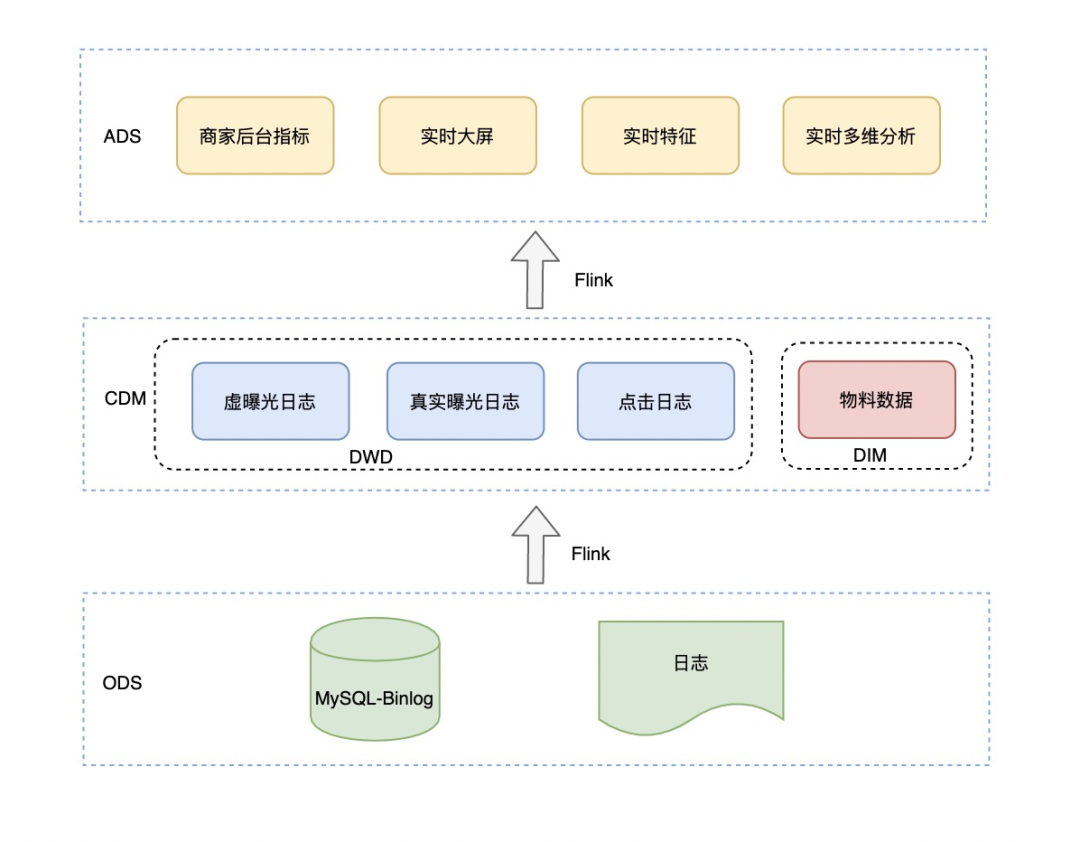
数据源层:DB日志与服务器日志,DB日志数据主要是广告商家、投放计划等物料数据;服务器日志是广告引擎曝光日志、广告点击日志、用户真实曝光日志;按照不同的业务属于又可以分为搜索广告日志、推荐广告日志。
中间层:分为DIM层与DWD层,DIM层即维度层,其数据来源于DB日志,通过离线全量+实时增量方式完整同步操作;明细层DWD建设很重要的一个要求就是能够被复用,因此将搜索、推荐广告日志做了水平合并供下游多方使用,另外一个是维度扩充,提前做维表信息关联,避免下游多次join操作。
应用层:按照应用场景划分为实时大屏、商家后台实时指标、实时特征、实时多维分析,提供了不同维度的曝光、点击、消耗等数据。
从当前分层架构来说,可以说与离线分层上有两个差异:
层次更少:离线中会存在汇总层与集市层,但是对于实时来说层次越多延时就越大,另外问题排查的难度就越大;
注重维度整合:离线中一般情况下大宽表出现在集市层,但是对于实时来说,在构建DWD层已经完成了维度整合操作,避免下游join操作,也就是通过空间换时间的策略。
实时OLAP
当前使用OLAP主要解决两方面的问题:
运营对于广告数据需求的多变性
运营对数据的需求变化性常常是大于广告商家看数的需求,如果都是使用Flink进行预计算完成的指标,那么其开发、运维成本是非常高的;
对mysql中的数据需要某个时间点的分析结果指标
mysql中的数据是可变的,经常会执行一些update操作,例如广告预算数据,预算是可实时变更的,需要知道每小时整的预算额。使用Flink去处理这类问题成本比较高、并且也不可复用。
基于以上问题,提出了实时OLAP的架构。
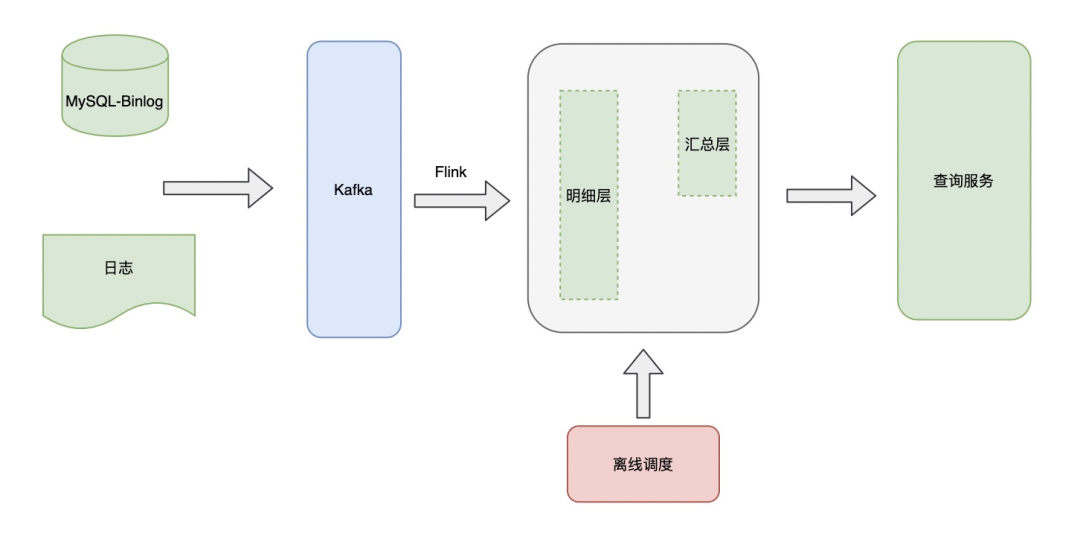
将明细数据通过Flink处理写入OLAP中,基于OLAP一方面完成在线数据查询,另外一方面通过离线调度处理OLAP中数据,进行一个简单的分层处理,最终提供给上层查询服务使用。
实时保障
整个实时数据体系保障,可分为稳定性保障、数据质量保障两个方面。
稳定性保障
稳定性保障目前主要从压测、任务等级划分、 监控三方面实施:
提前压测,应对流量高峰期,特别是大促场景下,提前做好资源保障、任务优化等措施。
制定保障等级,从任务影响面大小、数据使用方来划分,一般情况公司层面优先于部门层面,外部使用优先于内部使用, 高优先级任务需要优先/及时响应、必要情况下做双链路保障机制;
指标监控,监控任务failover情况、checkpoint指标、GC情况、作业反压等,出现异常告警。
数据质量保障
质量保障主要是保障数据正确性与时效性。
正确性
实时计算端到端的一致性,对数据正确性的影响,常用手段就是通过输出幂等方式保障,这种方式要求输出使用存储介质支持重写,对于不支持幂等的存储,比较常用的就是DWD层的kafka, 可能会产生重复的数据,那么在下游使用的时候可以使用row_number() 语法进行去重,保证相同的key不会被多次计算;
离线与实时的一致性,需要保证使用数据源一致、加工业务逻辑一致。
时效性
保障实时指标的时效性,常用的手段就是提前压测与监控。
提前压测:提前发现可能会影响任务处理速度的瓶颈,常见的就是数据倾斜、大状态的算子操作(join);
监控:监控任务当前的消费进度,在数据源处通过使用数据时间与当前系统时间对比判断其消费进度。
未来规划
实时DWS层建设
当前虽然做了统一DWD层的建设,但是在应用层商家看板、实时特征等的场景应用中,仍然存在重复建设的工作,例如小时维度的商品曝光指标被多个链路重复计算,这种存在数据一致性的风险,另外也会造成资源浪费,可以将公共的汇总指标抽象出来统一计算,建设DWS层。
实时OLAP 的深度应用
当前OLAP的应用场景主要是运营侧使用,但是对于商家侧看板数据也可以做进一步的应用。目前商家看板数据使用HBASE作为存储,然而实际的看数需求是需要排序、分页等操作,这个功能的实现大多数是通过将数据查询出来,然后基于内存去处理,这种方式开发成本高、不易维护,可通过OLAP天然支持排序、分页去解决这些问题。
基于Hologres的HASP架构简化数仓架构
Hologres 是阿里巴巴自主研发的一款交互式分析产品,其重要的理念就是HASP, 即hybrid serving/analytical processing,服务分析一体化,通过其行存结构提供高频kv查询,列存结构提供多维分析能力。可使用Hologres替换HBASE, 简化整个技术架构链路。
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!


2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
互联网最坏的时代可能真的来了
我在B站读大学,大数据专业
我们在学习Flink的时候,到底在学习什么?
193篇文章暴揍Flink,这个合集你需要关注一下
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
我们在学习Spark的时候,到底在学习什么?
在所有Spark模块中,我愿称SparkSQL为最强!
硬刚Hive | 4万字基础调优面试小总结
数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解析
【面试&个人成长】2021年过半,社招和校招的经验之谈
大数据方向另一个十年开启 |《硬刚系列》第一版完结
我写过的关于成长/面试/职场进阶的文章
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!