4类GPT产品模式、4个GPT小项目、4个商业化风险——AI产品经理视角
以下是从AI产品经理的视角,对最近2个月学习使用ChatGPT的总结,包含4类GPT产品模式、4个我做的小项目、4个商业化风险。
- 4类GPT产品模式是:Prompt类、Embedding类、Fine-Tune类、LLM类
- 4个GPT小项目是:内容生成、做个小程序、Embedding类项目、尝试Fine-Tune自己的GPT
- 4个商业化风险是:GPT迭代速度太快了、数据安全问题、内容审核、OpenAI政策问题
一、4类GPT产品模式
结合这段时间的项目经验,我把目前chatGPT类的产品化模式分为四类,由简单到复杂介绍一下。
1. Prompt类
仅使用chatGPT,这一类是最常见,也是商业化做得最多的。
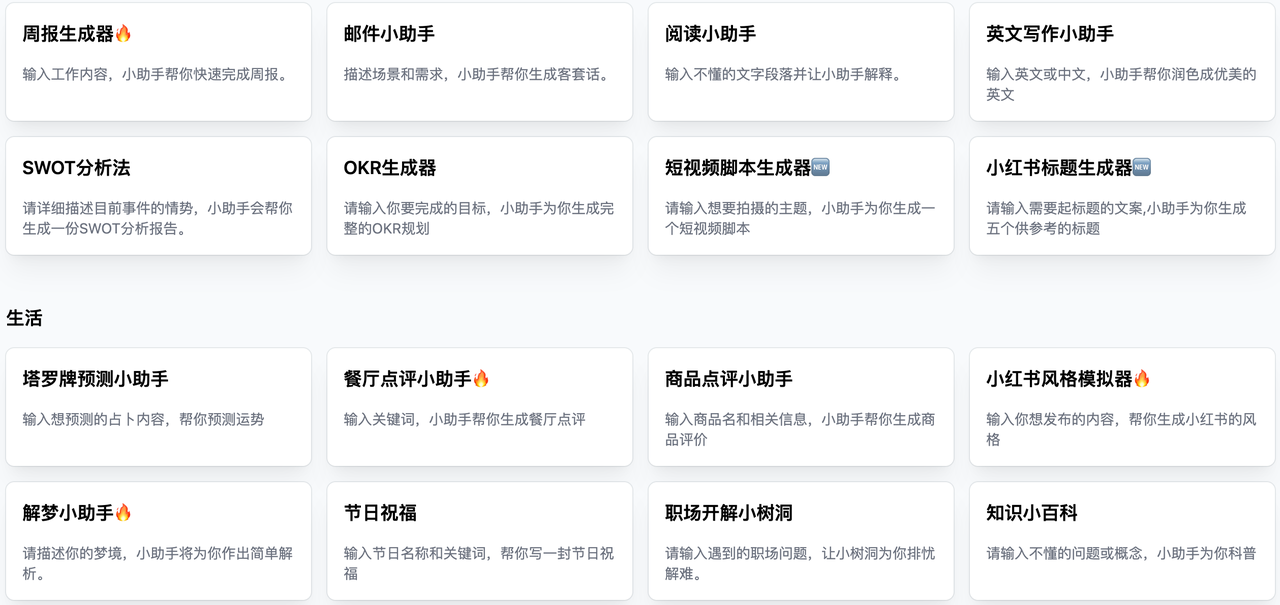
核心是利用Prompt引导去生成内容,比如日报生成器、小红书标题生成器、英语学习等,上面这个图片是我发现整理比较好的,另外也推荐下【外语易学堂】小程序,可以学习52种外语
2. Embedding类
向量数据库 + 搜索 + chatGPT。强烈推荐大家重点看这个方向!无论是私人助理,还是智能客服,只要是结合自有知识生成回答的项目,都绕不开这个方案,产品化空间很大,我自己也是花了最多时间在这个方向。

截图是鼎鼎大名的chatPDF项目,技术方案大致如下:
- 文本切割: 将自有的文档或知识,切割成一小块一小块的,每一块都向量化(可以用OpenAI的Embedding接口),返回这段文本的 embedding 的向量数据。存储这些数据,并且保存好对应关系。
- 用户提问: 将用户提的问题也向量化,拿到问题的向量数据。
- 搜索向量: 计算相似度。用问题的向量,在之前切割的所有向量数据里,计算和问题向量相似度最高的几个文本,可以直接使用余弦定理。
- 调用 ChatGPT: 将搜索到的知识和用户提问拼在一起,加上一段准备特殊的 prompt(例如:使用以上内容回答以下问题 ),去调用ChatGPT接口,生成回复。
- 技术方案看起来简单明了,但在实现过程中也有非常非常多的细节,后面会结合我自己实际操作讲一下注意事项。
3. Fine-Tune类
不断微调,去训练一个专属自己的GPT模型。比如你想做一个销售机器人,和客户聊天的语气尽可能模拟金牌销售的样子,这个机器又能掌握公司所有产品的知识,那你就最好自己Fine-Tune一个自己的专属模型,因为现有的chatGPT不能做到如此的拟合你的语气。
但这里有很大的成本问题,GPT-3的Davinci训练100M数据大概需要5万块人民币(记不太清楚了),部署也要另外收费,成本很高,此外GPT3.5是不支持Fine-Tune的。不过Fine-Tune时候也不一定非要用Davinci,根据和Azure的沟通,他们在某些项目上使用Ada做分类模型的效果也很好。我们也尝试过Fine-Tune,过程感人,后面再说。
4. LLM类
自己从头做一个GPT类的完全属于自己的预训练大模型。这个是大公司专属,参考百度文心一言、王慧文大佬的创业项目。不过其实考虑到Meta已经将LLaMA开源了,小团队做一些非商业化的项目还是可以的(参考斯坦福发布的Alpaca),但是难度依然很大,不建议大家直接冲,另外就是要注意版权问题,因为我也没做过,不详细展开了。
二、4个我做的小项目
1. 内容生成
最简单最容易上手的,当然是直接生产内容啦。为了验证GPT的生成能力,设计了一个小实验:利用GPT生成文案,再用剪映一键成片,从而实现批量生成视频内容。经过2天的熟悉后,很快可以15分钟内稳定输出40s视频。一周时间我制作了40条视频,收获xx点赞,x个粉丝,后面就懒得搞了,囧。
2. 自己做了一个学外语的小程序
疯狂使用GPT尝试不同的应用场景后,我发现教育是非常适合GPT特性的,也特别适合个人开发者。因为开发比较简单,我就自己顺手做了一个学习52种外语的小程序——外语易学堂,能纠正语法错误,可以模拟一个私人教练一样和你展开沟通,特别适合社恐星人,再也不用去英语角了。
3. Embedding类的项目
这个是我们参考chatPDF做的一个尝试,在在实际使用时候,效果也确实很好,怎么提问都能生成合适的回答。步骤简介在上面说过了,下面我结合业务实际使用情况,分享下当前存在的问题,包括且不限于:
- 富文本处理:这个是最大的问题,目前公开的GPT3.5是不支持富文本识别的,比如客户上传一个图片询问如何处理,这种答案就无法回答,15日公开的GPT4暂时也没开放图片输入的能力,等OpenAI发布新版本后我们会再次修改产品。
- 多轮对话:这个是第二大的问题,GPT3.5支持的最大token数是4096,实际应用中4轮左右的对话就会触及上限了,继续提问就会出现“遗漏记忆”的情况。这部分我们也和Azure的同学专题沟通过,他们也没有什么特别好的办法,不过好消息是GPT4的token长度增大了不少,但是价格也太贵了,用不起用不起。
- 其他:知识的时效性、知识权重、内容过滤、Embedding的工程化问题等,细节其实很多,大家想看下次单独起一个文章。
4. 尝试训练自己的GPT
因为GPT3没开源(我们也微调不起),就想着是不是可以利用GPT2 + RLHF试着做一个特定小领域的chatGPT,经过近20余人连续1周几千次的标记,结论是xxxx(回头再说吧,都是辛酸泪,单标注平台的设计就很麻烦了)
三、4个商业化问题
回头看这2个月以来的产品化路径,心情是跌宕起伏的。最开始激动不已,感觉AGI终于要到来了,但当从商业化、产品化角度去考验GPT时候,又发现一堆的问题,有些沮丧,再到后来OpenAI不断释放最新的接口,商业化似乎又可以期待了,类似情况循环往返,现在终于到了比较平静的状态,总而言之吧,前途是光明的。这里列举一下我碰到的商业化问题。
1. GPT迭代速度太快了
这看起来是一个好事,但其实也是一个头疼又幸福的烦恼。经常是你一个商业模式刚开始做,GPT就出了新版本了,以前的东西就要重新思考。比如一开始没有发布GPT-3.5-Turbo模型,做产品时候要用session的方案去模拟请求,后来发布了GPT3.5的API后,产品又要重新开发。
又比如多模态问题,这个GPT4发布后看起来解决了一部分(要测试一下才知道),但注定又要重新设计产品。快速迭代的模型是好事,但至少现阶段来看,是不利于发展成熟的商业模式的,大家不太敢大规模投入,可以参考jasperAI和Grammarly的情况。
2. 数据安全问题
经过和微软Azure的反复确认,目前OpenAI是没有在国内部署服务器的,也就是说你所有的请求内容都要出国,送到美国的服务器处理。这个大公司尤其敏感,也就注定了百度文心一言会有市场,如果你在大公司,就要仔细考虑下了。
3. 内容审核
如果要做商业化,对输出内容的zz审核及敏感内容过滤是一定要注意的,建议GPT生成的内容再过一遍审核服务,避免别人爆破你的服务,输出一些不安全的内容。
4. OpenAI政策问题
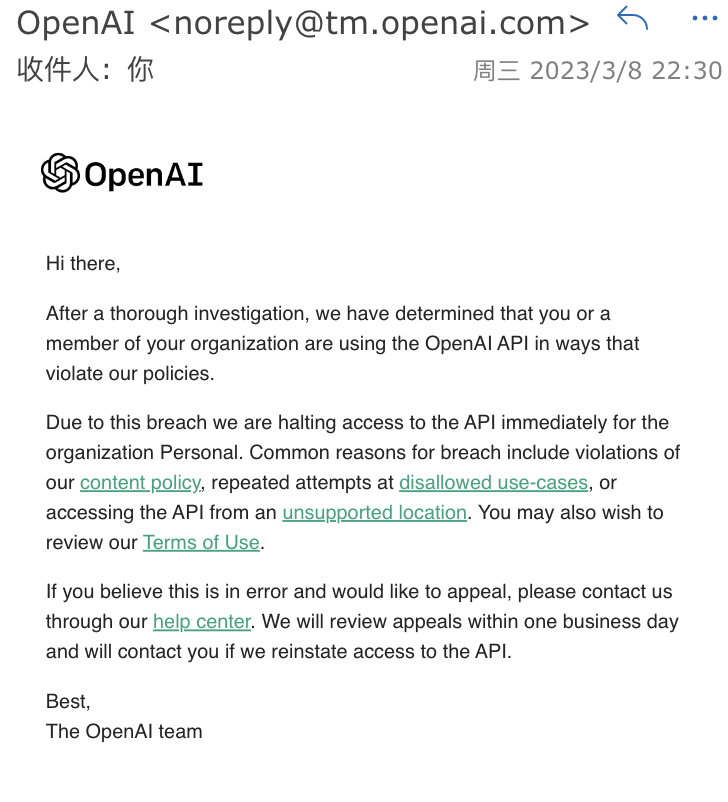
3月初开始,OpenAI的API地址就被墙了,需要自己想办法。另外上周开始,OpenAI封禁了一批“非法请求”的账号,从国内/香港等OpenAI不支持地区的访问,将会被封禁账号,具体自己看OpenAI的政策。我当时收到的邮件如下:
四、有趣产品分享
下面是几个非常有趣的产品推荐,他山之石可以攻玉,朋友们看一下:

五、参考资料
1. 如何体验chatGPT
最小白的问题其实也很重要,如果你已经会使用GPT了,直接跳过。
- 国内直接用: 推荐【阿旺机器人】小程序,这个是BaixingAI公众号开发的,使用最简单,国内就能用。
- OpenAI官方: 直接点这里,用起来比较麻烦。
- API访问: 注册账号,拿到API key,使用https://chatx.me、OpenCat等访问,注册方法自己搜索吧。
2. GPT原理学习
有点基础的可以直接看以下内容,再次说明,这个是产品经理视角的,算法工程师们请直接看论文:
- 先看这个:大规模预训练语言模型总结:ELMo、GPT、BERT、XLNet
- 再看这个:【RLHF】训练ChatGPT
3. 几个好的开源项目/论文
- ChatGPT 中文调教指南:大量的中文调教prompt,很实用。
- 微软的Visual ChatGPT:连接 ChatGPT 和一系列视觉模型,以实现在 ChatGPT 的聊天过程中发送和接收图像。
- Meta推出的Toolformer:让LLM自己学会使用工具,在实际业务中,很多场景是需要机器人自己调用外部工具的,期待早日成熟。
本文作者 @FakeFelix 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
