争夺用户数据,巨头公司正暗斗深度学习能力?
12月18日,腾讯公司对外宣布,将推出一个由腾讯与香港科技大学、北京大学联合研发的名为Angel的第三代高性能计算平台,并预计于2017年一季度开放其源代码,鼓励业界工程师、学者和技术人员大规模学习使用,激发机器学习领域的更多创新应用与良好生态发展。
Angel采用参数服务器架构,解决了上一代框架的扩展性问题,支持数据并行及模型并行的计算模式,能支持十亿级别维度的模型训练。自今年初在腾讯内部上线以来,Angel已应用于腾讯视频、腾讯社交广告及用户画像挖掘等精准推荐业务。另外,Angel还支持深度学习,它支持Caffe、TensorFlow和Torch等业界主流的深度学习框架,为其提供计算加速。Angel平台的推出可以说是腾讯在人工智能领域的重要一步。
在腾讯Angel之前,谷歌有TensorFlow,微软有CNTK,Facebook是Torch的坚定支持者,IBM强推Spark,百度开源了PaddlePaddle,亚马逊也在前段时间高调宣布了对MXNet的支持。目前,全球各大科技巨头争相布局人工智能领域,拉开了明争暗斗的产业大幕。

数据之争
除了主导机器学习平台外,巨头公司们也纷纷出招收集更多类型的用户数据,为其人工智能深度学习提供素材库。
交易行为数据
12月初,亚马逊在美国新开张了一家“智能超市”Amazon Go。进入这家神奇的智能超市后,打开亚马逊的 App 在门口扫一扫。在你扫码进入超市的瞬间,超市各个角落的摄像头就已经锁定你了,通过人像识别技术,藏在超市各处的摄像头将会时刻监控你的行为是否合法。

商品货架上配备了摄像头和压力感应器,当系统感知到物品从固定位置被拿走时,就会把它添加到你账户的购物车里,如果不想买了放回去,系统就会把商品从你的购物车里消除。最后,当你选购完商品离开时,再次拿出手机 App 扫码,此时系统将会联网,确认你的购买行为,并且在你的亚马逊账户中扣费。

炫酷新奇的 Amazon Go 智能超市背后,暗藏着亚马逊的野心。当你在商店里转悠的时候,实际上你逛商场的路线、喜欢的商品、购买的习惯都会被各种传感器忠实地记录下来。通过整理大量的用户数据,亚马逊可以灵活地调节商品的摆放、库存、甚至店面的装潢,最大程度地激发用户购买欲,从而提高整体的销售情况。如此详尽的数据,以往传统的零售店是拿不到的。
语音数据
用户语音数据的争夺则更为激烈。如今许多内置智能语音助理设备的实际使用体验都不如人意,语言识别技术已经成为了众多科技厂商的攻坚重点。《彭博社》日前撰文指出,语音识别技术的发展,其背后语音数据库的规模或许就是这类产品未来发展的命门所在。
因此,包括亚马逊、苹果、微软和百度都在世界范围内广泛收集人类语音数据。
微软已经在全球多个城市打造了专门用于录制志愿者在家居环境中对话内容的工作室;
亚马逊每小时都会将Alexa收集到的海量语音请求上传到庞大的数据库;
百度正在收集中国各地的方言数据,然后利用这些数据告诉电脑该如何分析、理解、响应不同的语音指令。
“我们系统获得的数据越多,其实际表现就越好。语音识别是一项资本密集型业务,目前还没有多少组织拥有如此庞大的数据库。”百度首席科学家吴恩达(Andrew Ng)表示。
图像数据
巨头的收购往往预示着未来的方向,去年谷歌巨资收购Nest已经对国内整个智能硬件产业产生了极为深远的影响,互联网公司争相进入智能硬件领域。而近日又有消息称,谷歌计划收购无线网络摄像头Dropcam,而和谷歌竞购Dropcam的是另一家科技巨头苹果,这一下又把智能摄像设备推上了风口浪尖。事实上,百度(小度i耳目)、三星(SmartCamHD)等巨头已经布局。
智能硬件和过去传统硬件不同之处,传统硬件强调硬件本身的能力,而智能硬件强调“硬件-云-终端(手机)”(即物联网的黄金三角)的联网和交互。智能化越来越深入到现实世界,搜索也在从最初的文字,慢慢开始朝图像演进,诸如Google地球和街景,还有扫封面、查人像之类的应用,这些离不开图像大数据的积累。而这只是静态的世界,而以时间轴的视频数据,更接近于现实世界,这些数据的积累相当于在记录整个动态世界,这后面具有极为重大的价值。
用户通过网络摄像头上传到云端的海量的声音、视频等数据,服务商可以用来进行深度学习的研究,帮助计算机模拟人类的学习行为,这是人工智能的核心。

不仅是网络摄像头,大到智能电视,小到智能路由器、智能手环等产品,科技巨头们布局智能家居、可穿戴设备都是看重数据的价值,是在给3-5年后的竞争提前打基础。
战争背后
目前AI整个行业还处于早期阶段,虽然在某些垂直领域已经超过或者达到了某些人类的平均智能水平,但是这与人的综合智能还相差甚远。无论我们有如何先进的算法模型,我们都需要重新训练数据;无论我们有如何深层的网络模型,本质上都是通过算力解决问题。这和人与生俱来的智能,以及“创造力”、“举一反三”、“归纳总结”能力都相差甚远。
但是我们也看到了积极的方向,比如deepmind的reinfocement的强化学习的发展进步,openai的gan生成对抗网络的发展。这些积极的发展使得AI的领域发展日新月异。因此大数据素材库的收集整理,对人工智能发展、机器学习能力进步显得尤为重要。那么,机器的学习是否跟人一样?深度学习该怎样理解?机器学习是否依赖于大数据?企业都需要做机器学习、智能AI才能有利于后期发展吗?小编炮带着这些疑问查询了相关资料。

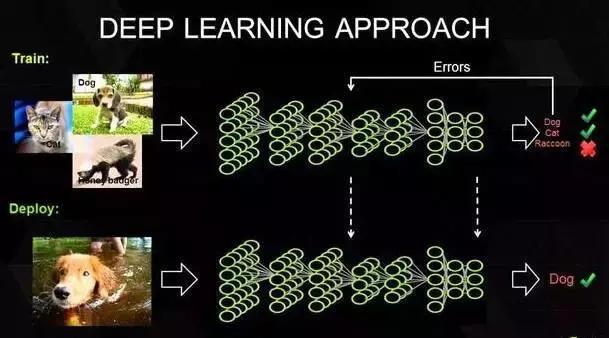
深度学习的概念源于人工神经网络的研究。人工神经网络,即模仿人类大脑建立的、处理单元(人工神经元)相互关联的计算机模型,已经出现数十年了。早期这些神经网络通常有1个或2个隐藏神经元层组成,现在已经从浅层结构进化到深层结构,后者又被称为深度学习。而这种转变依赖于大规模建造大型和并行模型的成本不断下降,以及训练深度模型所需大型多维数据集的日益增多。
从本质上看,深度学习隶属于机器学习范畴,但是标准的机器学习通常需要手工从数据中提炼模式,耗时费力;而深度学习模型擅长于自动捕获隐藏于大数据中的复杂结构模式,在对图像、视频、音频以及文本数据进行分析时,这种能力拥有巨大优势,而依靠手工从数据中提取模式很快将达到极限。
不过,中国科学院院士、清华大学教授张钹表示,在后深度学习时代,人工智能将面临三大挑战:
一是 概率统计方法带来的困难。即它只能找出重复出现的特征,发现数据间统计的关联性,却不能发现本质特征,找到因果关系。
其次 是冗余数据带来的困难。实际上,网络数据中只有34%是有用的,66%则是虚假、无用的,这会严重影响识别的效果。
三是 不能举一反三,进行领域迁移。而要想实现突破,人工智能发展除了需要知识驱动与数据驱动结合从而“双轮驱动”外,更加要依靠学科交叉,特别是数学、认知科学、心理学、神经科学和语言学等。

目前,众多公司都在尝试做机器学习、智能AI,大量学术机构和科技公司也在研究深度学习,媒体对深度学习相关成果的报道日益增多……这都大大促进了深度学习的普及。
不过,企业需要了解,进入深度分析领域需要权衡利弊。尽管深度网络构架的精度可媲美甚至超越现有分析方式,但由此产生的模型通常是不透明的“黑盒子”,需要对其进行精调。深度学习往往需要预先架构投资,以便能处理模型的复杂性。大型神经网络往往需要数小时乃至数天的训练,如果没有事先考虑或准备,这可能对数据科学团队造成巨大影响。
文/华强智造Hi空间
关键字:数据, 深度学习
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
