Python实现SMA黏菌优化算法优化支持向量机分类模型(SVC算法)项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。
1.项目背景
黏菌优化算法(Slime mould algorithm,SMA)由Li等于2020年提出,其灵感来自于黏菌的扩散和觅食行为,属于元启发算法。具有收敛速度快,寻优能力强的特点。主要模拟了黏菌的扩散及觅食行为,利用自适应权重模拟了基于生物振荡器的“黏菌传播波”产生正反馈和负反馈的过程,形成具有良好的探索能力和开发倾向的食物最优连接路径,因此具有较好的应用前景。
本项目通过SMA黏菌优化算法优化支持向量机分类模型。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:
3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
从上图可以看到,总共有12个变量,数据中无缺失值,共1000条数据。
关键代码:
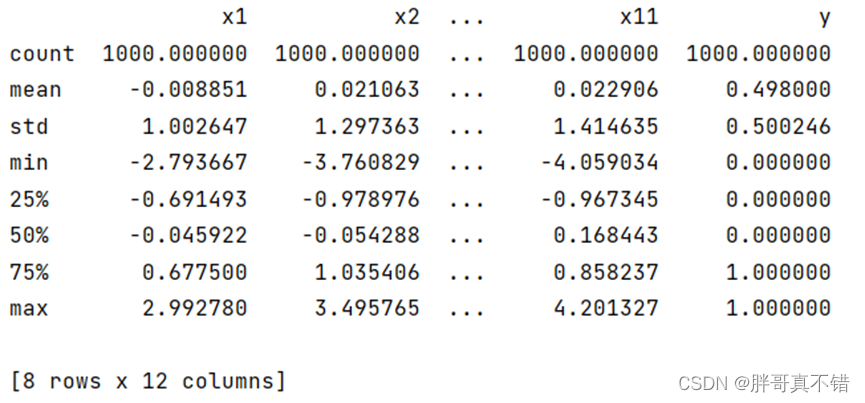
3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
关键代码如下:
4.探索性数据分析
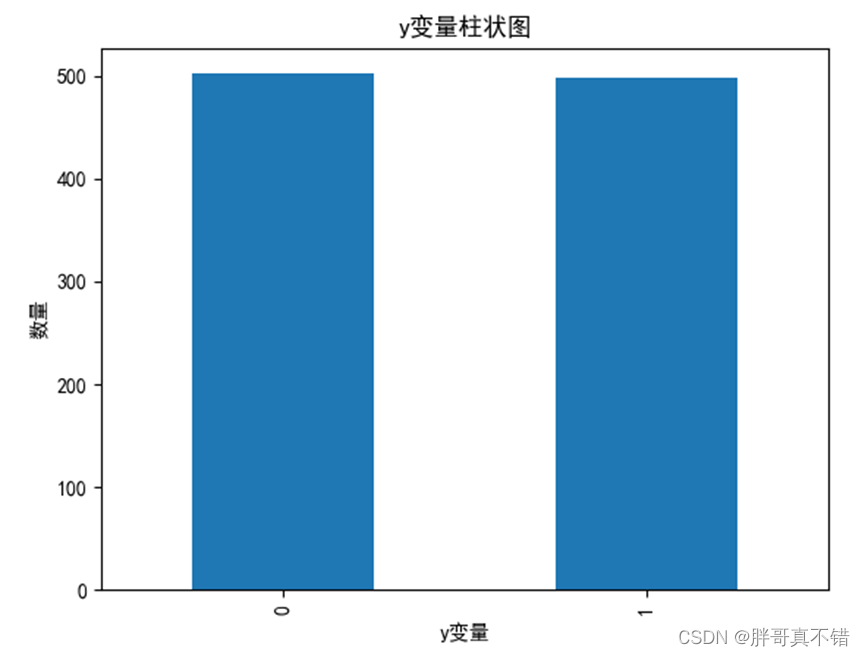
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
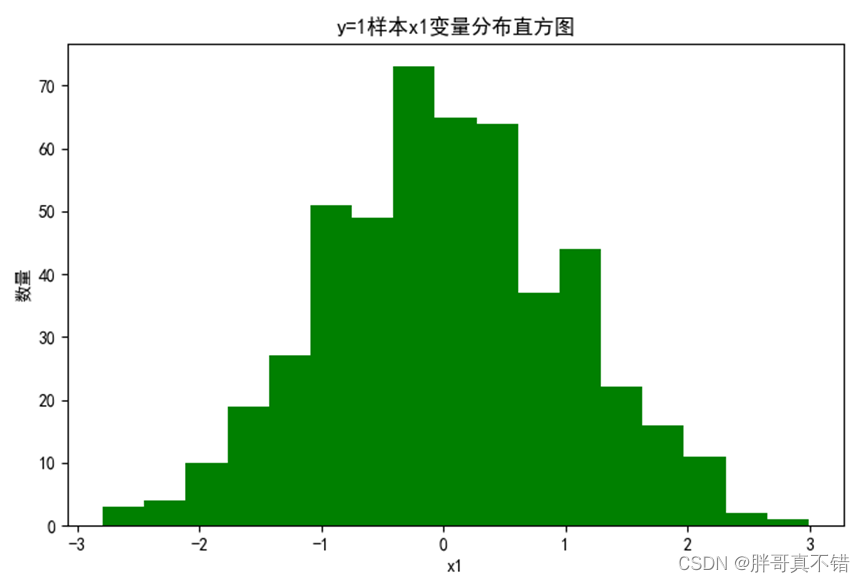
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
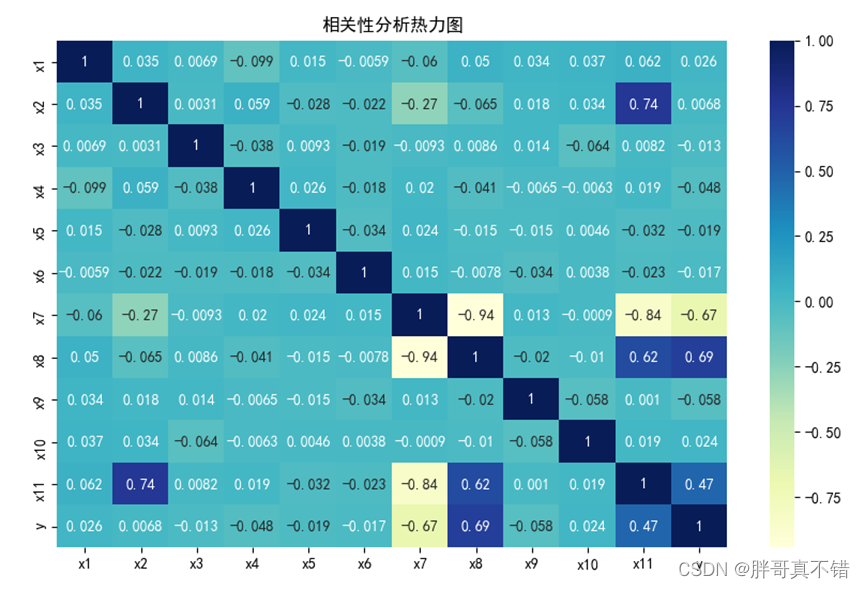
4.3 相关性分析
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:
5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:
6.构建SMA黏菌优化算法优化支持向量机分类模型
主要使用SMA黏菌优化算法优化SVC算法,用于目标分类。
6.1 算法介绍
说明:SMA算法介绍来源于网络,供参考,需要更多算法原理,请自行查找资料。
黏菌是一种生活在寒冷和潮湿的地方的真核生物。觅食时,黏菌中的有机物寻找食物,包围食物,并分泌酶来消化食物。在迁移过程中,前端延伸成扇形,随后是一个相互连接的静脉网络,允许细胞浆在其中流动。由于其独特的形态和特征,它们可以同时利用多种食物来源,形成连接它们的静脉网络。下图模拟了黏菌的这种独特觅食行为:
研究表明,当黏菌静脉接近食物来源时,其体内的生物振荡器会产生一种传播波,增加静脉内细胞质流动,细胞质流动得越快,静脉就越厚。通过这种正负反馈的结合,黏菌可以凭借相对优越的方式建立连接食物的最佳路径。所以一般大家见到的黏菌都是黏黏糊糊的一大滩。
该算法主要模拟了黏菌在觅食过程中的行为和形态变化,而未对其完整生命周期进行建模。通过权值指标模拟黏菌静脉状管的形态变化和收缩模式之间的三种相关性。
黏菌觅食过程,首先根据空气中气味接近食物,食物浓度越高,生物振荡器波越强,细胞质流动越快,黏菌静脉状管越粗。通过函数表达模拟该其逼近行为,其位置更新公式如下:
其中LB与UB表示搜索范围的上下边界,vb的参数,取值范围是[−a,a],vc从1线性减少至0.t 表示当前迭代,Xb表示当前发现食物气味浓度最高位置,X表示黏菌当前位置,XA和XB表示随机选取的两个黏菌位置,W表示黏菌重量,S(i)表示X的适应度,而DF表示所有迭代中的最佳适应度。其中,参数a的函数表达为:
其中,maxT表示最大迭代次数。而W的表达式为:
其中condition表示S(i)排在前一半的种群,r表示[0,1]区间内的随机值,bF表示在当前迭代过程中获得的最优适应度,wF,表示当前迭代过程中得到的最差适应度值,smellIndex表示适应度序列(最小值问题中为递增序列)。
最初公式表示的黏菌逼近食物行为,搜索黏菌个体位置X可以根据目前获得的XB最佳位置进行更新,同时vb、vc和W参数的微调可以改变黏菌位置。
黏菌搜索个体在三维空间中的位置变化,可通过rand函数使个体形成任意角度的搜索向量,此概念同样可扩展至更高维空间。
算法流程:
Step1.初始化种群,设定相应参数。
Step2.计算适应度值,并且排序。
Step3.利用最初的公式,更新种群位置。
Step4.计算适应度值,并且更新全家最优位置,当前最优位置。
Step5.是否达到结束条件,如果达到则输出最优结果,否则重复执行步骤2-5。
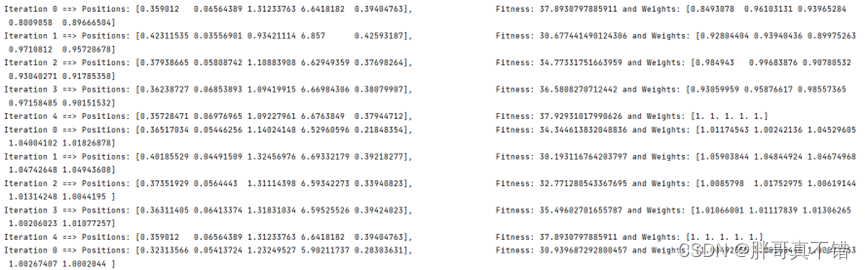
6.2 SMA黏菌优化算法寻找最优参数值
关键代码:
每次迭代的过程数据:
最优参数:
6.3 最优参数值构建模型
7.模型评估
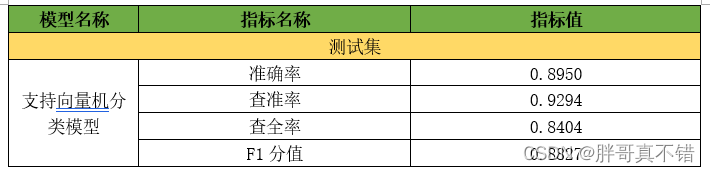
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
从上表可以看出,F1分值为0.8827,说明模型效果良好。
关键代码如下:
7.2 查看是否过拟合
从上图可以看出,训练集和测试集分值相当,无过拟合现象。
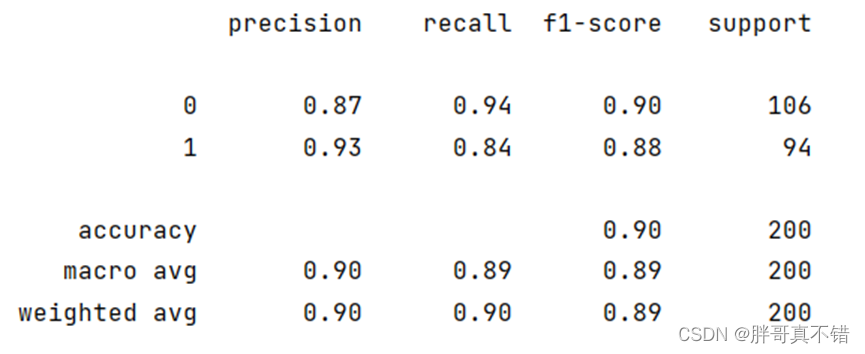
7.3 分类报告
从上图可以看出,分类为0的F1分值为0.90;分类为1的F1分值为0.88。
7.4 混淆矩阵
从上图可以看出,实际为0预测不为0的 有15个样本;实际为1预测不为1的 有6个样本,整体预测准确率良好。
8.结论与展望
综上所述,本文采用了SMA黏菌优化算法寻找支持向量机SVC算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。







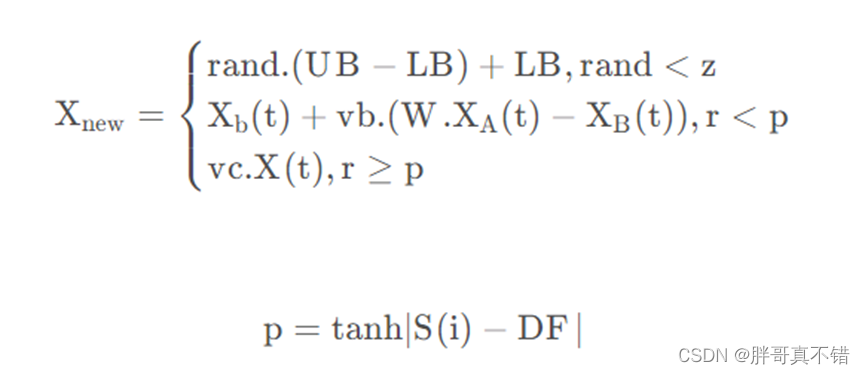
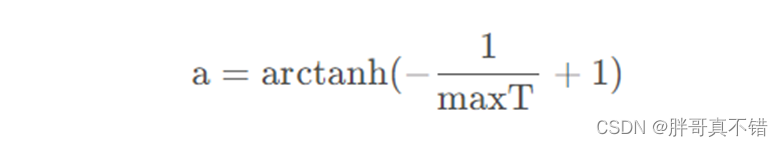






本次机器学习项目实战所需的资料,项目资源如下:
项目说明:
链接:https://pan.baidu.com/s/1c6mQ_1YaDINFEttQymp2UQ
提取码:thgk
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!