Kafka 设计详解之网络通信
前言
Kafka 是 LinkedIn 开发的一个分布式的消息中间件。由于其高吞吐量、可水平扩展等特性,目前被广泛使用,已经是目前大数据生态系统中不可或缺的一环,有关其详细介绍可以查看官方的文档。Kafka 的流行源于他优秀的设计,如依靠磁盘(以及操作系统的 Page Cache)而不是内存来存储队列数据、充分使用零拷贝(zero-copy)以减少数据在不同内存空间间的拷贝、数据尽可能的使用顺序读写等。今天准备深度解析 kafka 的网络通信模块,来学习下实现一个高吞吐量的系统要设计一个怎么样的网络通信机制。
网络通讯协议
作为一个消息队列,涉及的网络通信主要有两块:
- 消息生产者与消息队列服务器之间(Kafka 中是生产者向队列「推」消息)
- 消息消费者与消息队列服务器之间(Kafka 中是消费者向队列「拉」消息)
要实现上述的网络通信,我们可以使用 HTTP 协议,比如服务端内嵌一个 jetty 容器,通过 servlet 来实现客户端与服务端之间的交互,但是其性能存在问题,无法满足高吞吐量这个需求。要实现高性能的网络通信,我们可以使用更底层的 TCP 或者 UDP 来实现自己的私有协议,而 UDP 协议是不可靠的传输协议,毕竟我们不希望一条消息在投递或者消费途中丢失了,所以 Kafka 选择 TCP 作为服务间通讯的协议。
网络 IO 模型
谈到网络通信,绕不过 IO 模型,IO 模型主要是同步与异步,阻塞与非阻塞之间进行选择。
Kafka 的生产者同时实现了同步和异步两种类型的客户端(即:向服务端发完请求后可以一直等待响应也可以继续干后面的事),其异步客户端实现方式是通过线程池加回调函数。
Kafka 的服务端使用了 NIO 的 IO 多路复用技术,是非阻塞的 IO, kafka 的早期版本中,服务端是通过同步的方式处理客户端请求,最新版本是通过异步的方式进行的。
Kafka 自带的消费者是通过同步阻塞的方式进行数据拉取的,当然如果需要异步处理,可以自己另外写一个异步消费者。
Reactor 线程模型
Kafka 采用的是 Reactor 多线程模型,即通过一个 Acceptor 线程处理所有的新连接,通过多个 Processor 线程对请求进行处理(解析协议、封装请求并转发)。在早期版本中,对请求的处理在 Processor 线程中同步进行,也就是说,有多少个 Processor 线程就有多少个处理请求的线程。在新版本中,kafka 新增了一个 Handler 模块,通过指定的线程数对请求进行专门处理,Handler 与 Processor 之间通过一个 block queue 进行连接。线程模型如图:
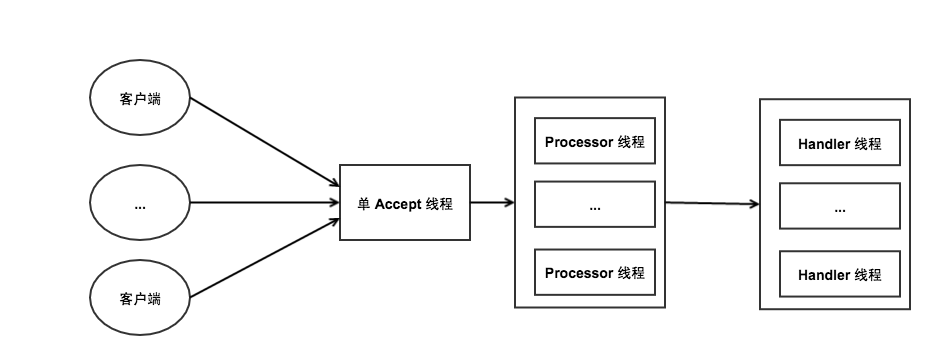
kafka 线程模型
网络通信流程剖析
Kafka 的整个网络通信框架并非一成不变,从早期版本到现在经历了一些变化,下面我们通过分析早期的版本与最新版本的网络通信流程,了解其演变过程,以供自己在设计系统的网络通信时的一些参考。
早期版本(0.7)
Kafka 以 NIO 作为网络通信的基础,其通过将许多 socket 连接注册到一个 Selector 监听,可以只用一个线程就能管理很多的连接,减少了大量线程的系统开销。
早期版本的 kafka 的网络通信实现是一个简单的 Reactor 多线程模型,如图:

kafka 早期版本网络通信流程(白色虚线框内是一个 Processor 线程内部做的工作)
- 客户端向服务端发起请求时,Accept 负责接受这个 TCP 连接,连接成功后传递给其中一个 Processor 线程(先添加到 Processor 线程中的内部新连接队列)。
- Processor 线程收到该新连接后(从新连接队列中 poll),将其注册到自身的 Selector 中,监听其 READ 事件。
- 每当 Client 在这个连接上写入数据,就会触发 Processor 线程中 Selector 监听的 READ 事件,这时该线程会读出连接中的元数据,根据协议(Handler Mapping)调用相应的 Handler 进行处理
- Handler 处理完成后,可能会有返回值需要返回给客户端(如 Fetch 请求就需要返回具体内容给客户端),这时将 Handler 返回的 Response 绑定到连接上(SelectionKey.attach 方法),同时将这个连接的监听事件从 READ 转为 WRITE。
- Selector 监听到刚才注册的 WRITE 事件,将连接中绑定的 Response 发送。
个人理解 4、5 两步可以合并,即如果 Handler 有返回值,就直接返回,个人猜测 kafka 这样设计可能是出于整个架构上更加清晰优美的目的。
新版本
新版 Kafka 也是以 NIO 作为网络通信的基础,也是用 Reactor 多线程模型,所不同的是新版把具体业务处理模块(Handler 模块)独立出去,用单独的线程池进行控制。具体如下图:
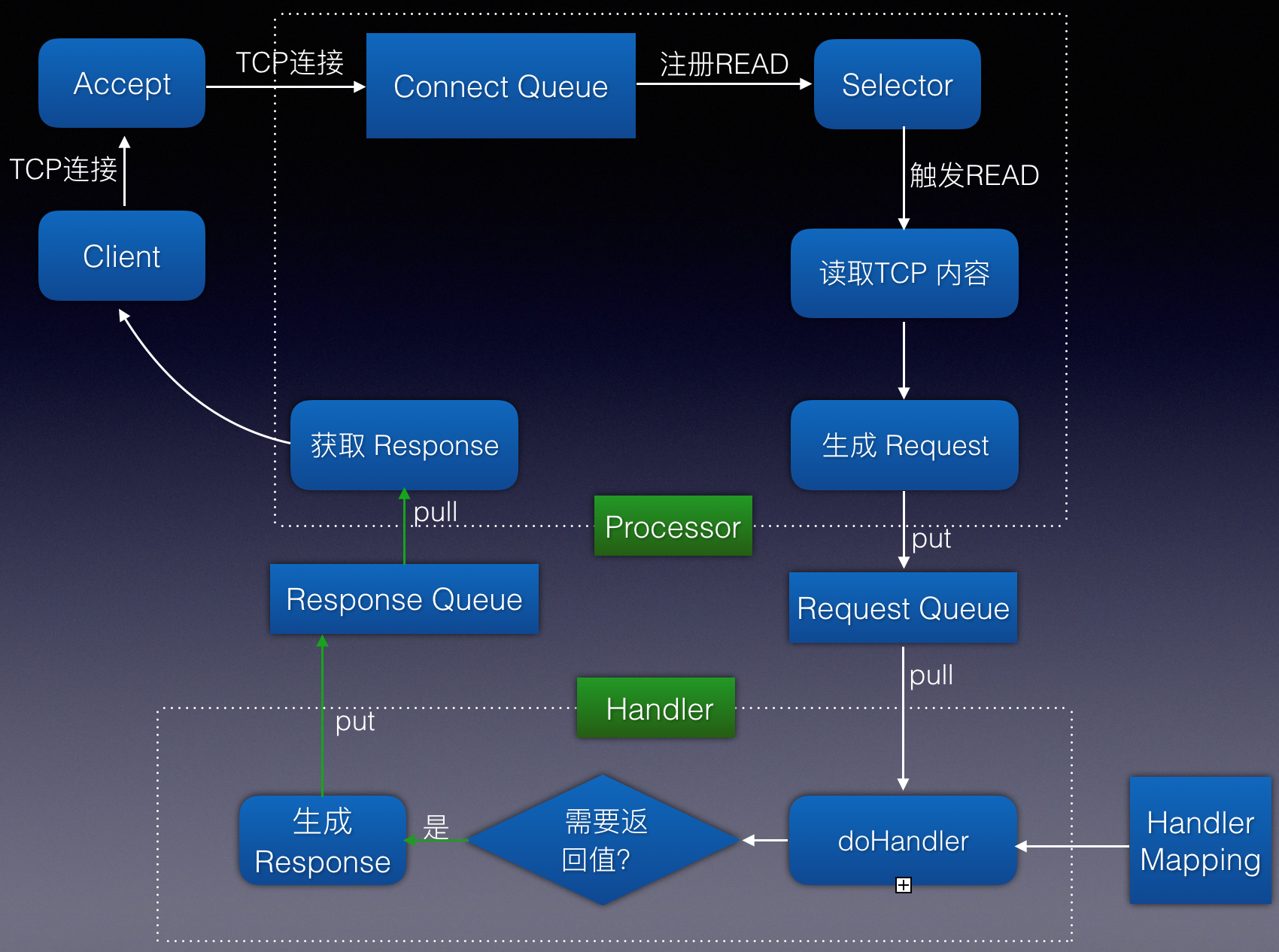
kafka 新版本网络通信流程
新版本分离出 Handler 模块,我理解的好处有以下几个:
- 可以单独指定 Handler 的线程数量,便于调优和管理
- 可以避免一个超大请求堵住整一个 Processor 线程的情况
- 因为 Request 与 Handler、Handler 与 Response 之间都是通过队列进行连接,所以彼此是解耦的,可以让请求变为异步,对系统的性能会有提升
总结
本文通过分析 kafka 的网络通信设计对网络编程进行了一次学习,笔者之后又对 netty 的网络通信进行了了解,发现大部分也类似,可见目前的高性能的网络通信可能存在「最佳实践」,不过真正在设计一个系统的网络通信时,还有很多工程上的问题需要解决,有许多的「坑」,很容易为系统埋下定时炸弹,因此,我看很多大牛都建议不要自己去实现网络通信模块,因为 netty 已经足够优秀了。
最后,如果读者有兴趣看 kafka 的源码,又对 scala 不是很熟悉,可以先看 jafka 的代码,它是早期 kafka 版本的 java 克隆版。
文/两棵橘树
关键字:kafka
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
