推荐系统里的推荐理由都有哪些?如何生成?
很多时候我们在推荐信息流里面会看到一些推荐理由,好的推荐理由可以提升我们的点击欲望,那么这些推荐理由到底是如何生成的了?本篇文章给大家详细介绍一下。
一、什么是推荐理由
推荐理由,字面上的意思就是为什么给你推荐了这个物品,也可以被叫做推荐解释。在推荐结果上增加一些“推荐理由”的目的也很简单,就是为了提升推荐结果的可解释性,进一步提升点击率。
目前在各个领域的APP上基本都会有推荐理由,挑选了9家比较有代表性的公司给大家介绍一下:
1. 电商领域
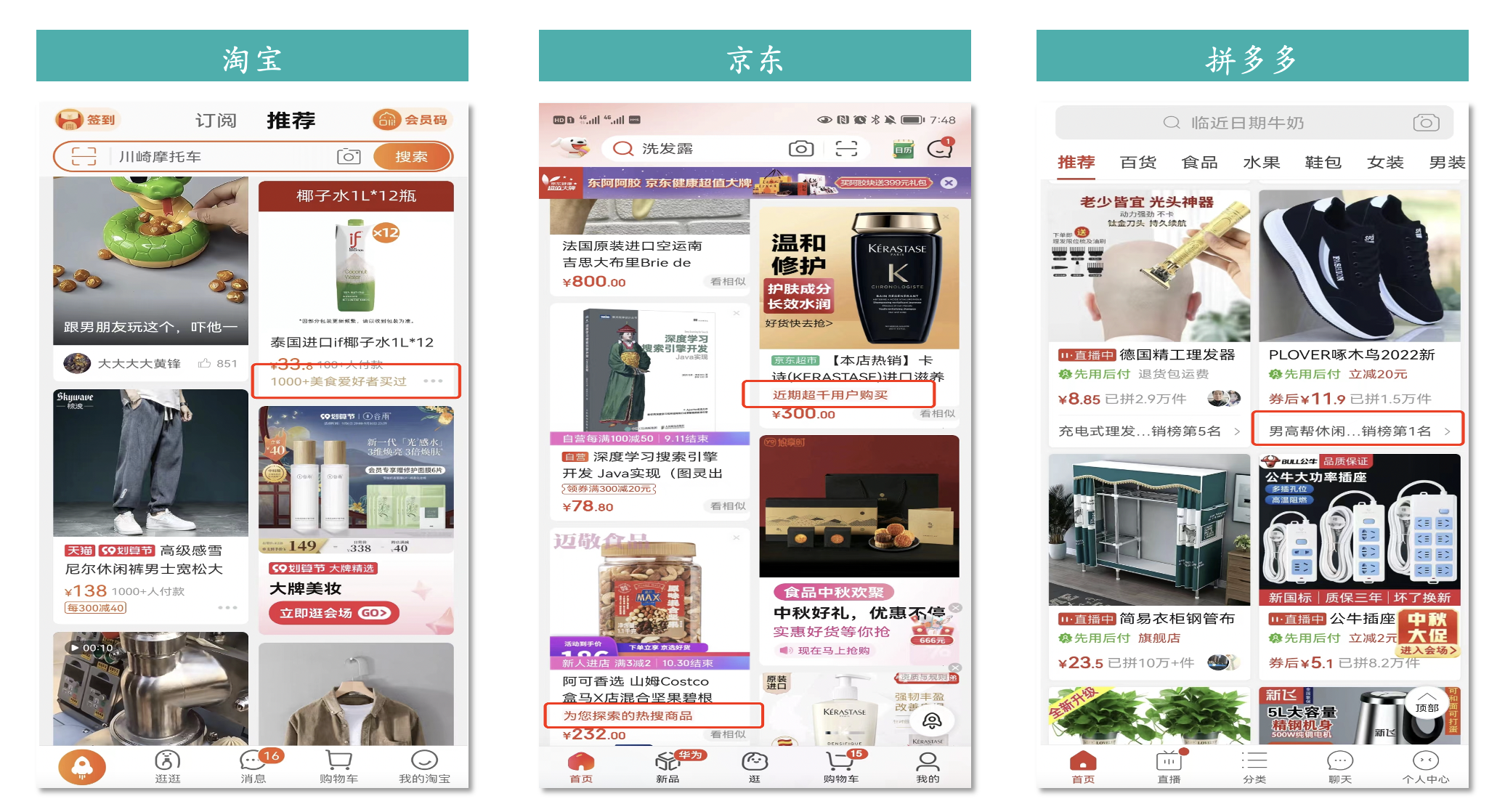
- 淘宝:“1000+美食爱好者买过”;是为了告诉用户这个商品很多美食爱好者都喜欢买,你也不能错过;
- 京东:“近期超千用户买过”+“为你探索的热搜商品”;同样是为了告诉用户这个商品是很多人共同的选择以及最近热门搜索的商品,你也可以尝试;
- 拼多多:“男高帮休闲鞋销榜第1名”;直接告诉用户这款鞋子很火,销量排名第一。
2. 本地生活领域

- 美团:“海淀区新店,快来种草吧”是为了告诉你有新店,可以来尝尝新;“经典必吃红烧牛肉米粉”是告诉你经典款不容错过;
- 大众点评:“五道口北京菜口味榜第一名”&“2022上榜一钻餐厅”都是通过排行榜的形式来告诉给你推荐的这些餐厅都是榜上有名的餐厅;
- 盒马:”回头客3.2万人“是通过历史上有大量人复购来告诉你这款商品很不错。
3. 内容领域
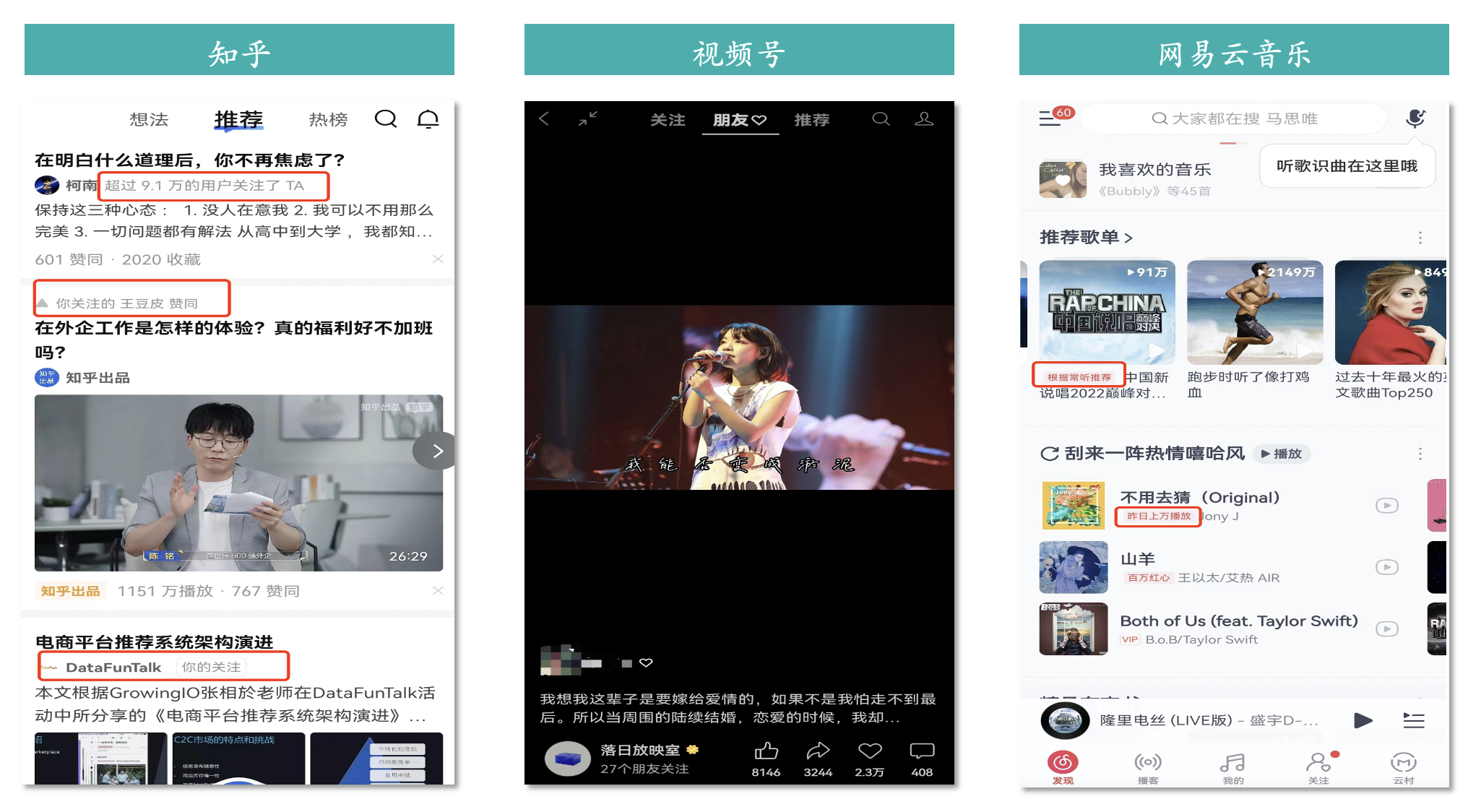
- 知乎:“超过9.1万的用户关注了TA”是为了告诉你这个创作者的粉丝很多,在一定的领域具有一定的影响力,你可以看看;“你关注的王豆皮赞同”是为了告诉你关注的某个博主对这个内容也很感兴趣,你也可以看看;
- 视频号:“XXX朋友点赞过”,和知乎的那个推荐理由差不多,都是基于社交属性来设置的推荐理由;
- 网易云音乐:“根据常听推荐”表示这首歌和之前你经常听的歌很相似;“昨日上万播放”表示这首歌昨天很火,给你推荐你也可以尝试听听。
我们可以通过三大领域,9个APP的推荐理由案例发现一个好的推荐理由其实是可以提升用户的点击欲望,让推荐结果更加透明化;
二、推荐系统为什么要做推荐理由
为什么推荐系统的推荐结果展示要添加推荐理由,其实这和我们日常生活也都是息息相关的。
- 当我们想看一部电影却不知道该看什么的时候,我们会咨询朋友的意见,朋友们会告诉我们XX电影好看,主演是XX,剧情非常好,演员的演技也很好。“剧情非常好,演员的演技也很好”其实就是我们生活中给出的一种推荐理由。
- 当我们去一家餐厅吃饭不知道点什么的时候,我们通常会叫来服务员问他有没有什么菜推荐。服务员会说 “这几道菜是我们店经典菜必点,这道菜是我们店刚刚上新的新菜可以尝试一下”。其实服务员给出的推荐理由和大众点评&美团给出的推荐理由逻辑是一样的。
一个值得信任和说服力强的推理理由会降低我们的选择成本和决策时间。如果我们将现实中的推荐场景同样复制到互联网上,在为用户推荐某一个商品或者服务时,不再是只告诉商品或服务是什么,同时也告诉为什么给他推荐这个商品或服务时:
- 平台侧:提高推荐结果的透明度,提升推荐结果的可解释性,进而提升推荐结果的点击率;
- 用户侧:提升用户体验,用户更加信服推荐结果;
在2022年这个时间点,在头部互联网大厂的APP推荐结果里基本都已经附上了推荐理由,只是推荐理由的覆盖度并没有很高以及种类比较少。随着推荐系统的进步以及用户自主意识的不断增强,推荐系统的透明化以及结果可解释性也需要不断增强。
推荐理由就是一种很好地提高推荐系统透明度,提升推荐结果可解释性,拉近系统与用户之间距离的方式,未来所有的推荐系统里都需要加上推荐理由。
三、推荐理由分为哪几类,如何实现
市面上这么多推荐理由,我们可以将其分为哪些大类了?又如何去挖掘出这些推荐理由了?
1. 推荐理由应该具备哪些特性
首先我们在设计推荐理由之前得明确推荐理由应该具备哪些基本要点,需要围绕着基本要点进行推荐理由设计。

如上图所示推荐理由需要具备三大基本要点:可解释性强、准确度高和信服度高,三者缺一不可;
- 可解释性强:推荐理由必须要容易理解,用户秒懂,而不需要进行思考;
- 准确度高:推荐理由必须要是准确的,而不是给商品乱加的标签;
- 信服度高:推荐理由必须要让用户信服,觉得推荐这个商品是有真道理,而不是一些无关痛痒的理由。
2. 推荐理由的分类及实现方式

- 用户特征:一般分为两个大类,一个是用户的行为特征,另一个是用户的偏好特征。基于用户行为特征的推荐理由生成基本都是统计学的方式,就像上文中盒马的例子”你经常购买的商品“;而基于用户偏好特征的,一般都是使用Item-CF算法,将基于Item-CF算法召回的物料都可以加上这类的推荐理由”根据常买推荐、根据常听推荐“。基于用户特征的推荐理由可以在各个领域使用,是一种普适性的推荐理由。
- 行业权威:这类主要用在一些内容和媒体领域,一种是将一些行业大V关注或点赞过的内容推荐给其他用户;一种是基于用户现有关注的一些大V,从他们历史曾经点赞过的内容中寻找和用户兴趣爱好匹配度比较高的物料进行推荐,然后附上推荐理由,可以进一步提升点击率;
- 热门潮流:可以分为很多种类型,比如近期流行的和历史上榜的。这类推荐理由基本都是通过统计学的方式来进行统计,尤其是排行榜类的信息,在很多电商公司会基于各种类目和属性的组合生成五花八门的排行榜,一个平台上的排行榜可能有几千种。
- 社交关联:基于社交属性的推荐理由其实是在相关社交软件或者媒体软件上经常使用的,在我们浏览视频号的时候,如果一个视频被很多微信好友点赞过,这个视频里面会被放在首位推荐给我们,甚至视频号还会有醒目的红点提醒我们点击观看,这就是一种基于微信社交生态专门有的推荐理由,我们看到这个视频下有哪些好友点赞了,我们就可以再去找这些好友聊这些视频,创造共同话题。
- 好评如潮:基于历史用户评论信息进行好评挖掘,然后再进行一个千人千面的用户匹配。因为评论信息中各种各样的信息都会有,有的评论侧重于产品功能,有的评论侧重于使用体验,如何实现推荐理由与用户之间的千人千面匹配而不是一个推荐理由分发给所有用户这是技术上的难点。
3. 推荐理由生成和使用的挑战
推荐理由可以让我们的推荐系统更加透明化,提升用户的点击率,但是实际在落地时还是会有很多技术难点需要突破以及合规性需要注意。
(1)如何保证理由的准确性和及时性
推荐理由的准确性是必须要得到保证的,不然会起到反作用。同时推荐理由的及时性也很重要,比如”热门潮流“类的推荐理由,此类推荐理由就需要及时更新,很多SKU可能在夏天是流行的,比如西瓜、雪糕等,到了秋天立马就不再是流行的了,所以相对应的推荐理由我们也不能再使用。
(2)如何保证披露信息的合规性
推荐理由里面的信息是不是都适合披露,都是合规的。比如基于用户评论信息里面的一些信息,很多评论可能会比较直接或比较敏感,虽然确实和商品有关,但可能不适合直接披露在最外页给用户展示。还有一些类似于功效的信息也得需要进一步确认才可以。
(3)如何做到更进一步千人千面的适配和动态生成
这个是目前推荐理由领域最大的挑战和重点攻克的方向。我们上面介绍的很多种推荐理由其实都是千人一面的,当一个SKU被推荐给所有用户时可能使用的推荐理由都是一个,比如排行榜信息。
而推荐系统需要做到的就是千人千面,以往做的是千人千面用户和物料的匹配。未来需要实现的是同样一个物料推荐给不同用户时可能推荐理由也是不一样的,需要做到推荐理由的千人千面动态生成,而不是像现在这样的离线千人一面的生成方式。
本文作者 @King James 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
