关于“AI对话中断”场景的逻辑设计方法
一、用户场景
用户在与类ChatGPT的生成式AI产品进行对话和交互的过程中,可能因为某些原因,导致对话中断,此时,数据的流转逻辑和产品交互怎么设计才是比较好的方案呢?
中断的场景有2类,主要划分依据是是否切断网络、是否终止了数据传输和交互流程。
中断场景①:网络终端、刷新浏览器、关闭浏览器
- 该场景下,用户主动或者被动中断了与产品的网络连接;
- 本文讨论的范围设定是:对话中的用户已经成功发送了问题,继而中断了网络。
中断场景②:切换浏览器页签、切换查看对话记录
- 该场景下,用户仅仅切换了屏幕显示的画面,并没有切断网络和终止数据传输和交互流程;
- 可能存在长时间不停留在交互界面的情况。

(对话界面)
二、需求分析
根据上述的用户使用场景,我们需要对用户在该场景下的使用需求和交互心里进行进一步的分析。我们发现,两种场景都主动或被动打断了用户正常的对话路径,让用户的使用体验不流畅,产生了中断、丢失、卡顿等情况,我们需要通过分场景的、合理的产品交互的设计,来帮助用户完成交互动作,并且感受良好。
用户对产品的述求可能如下:
- 中断情况发生的时候,我需要明确感知情况有变;
- 中断时的状态和恢复后的状态之间需要有衔接,让用户认知保持连贯性;
- 已经交互的数据,不能丢失,能快速被找到,能感受到产品的稳定性。
三、产品目标
在对话式AI产品的交互中,这种主动或被动打断了用户正常的对话路径的场景是普遍存在的,尤其是组件化和PC端的界面。
基于场景的梳理和用户述求的分析,产品需要解决这个问题,并需要达到的目标有:
- 分场景梳理数据流转关系;
- 分析数据逻辑,明确数据呈现方式;
- 分场景的交互流程;
- 用户使用路径的设计。
四、数据逻辑
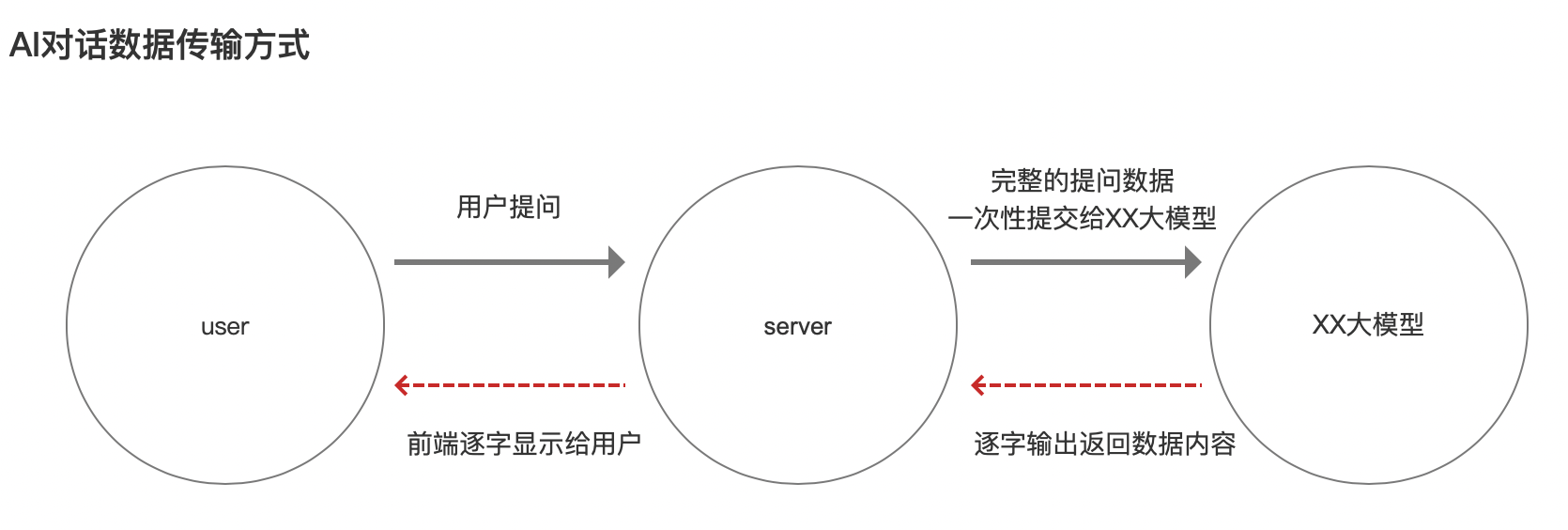
1. AI对话的数据传输方式
当用户需要使用GPT产品时,通常情况下,需要输入一段文本,一旦用户成功发送了“作为问题的这段文本”给到server,问题一次性提交给大模型。
而,大模型返回数据的方式是流式的,大模型逐步计算输出,server逐字逐句输出给到前端,前端再通过打字机效果展示给用户。
在此过程中,用户即便终端聊天,不终止大模型的数据输出。
如下图所示:
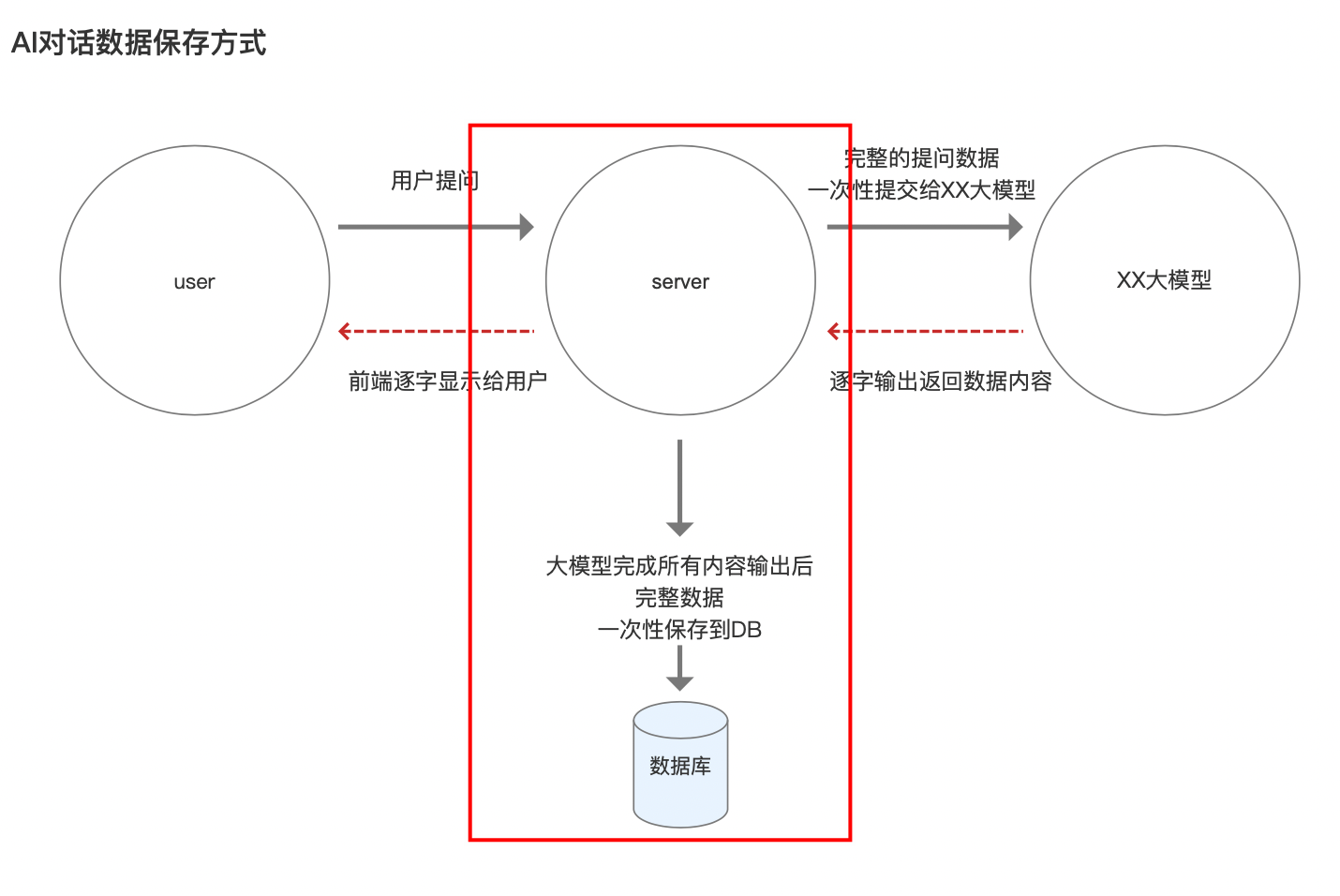
2. AI对话的数据保存方式
在一次用户对话交互中,大模型完成所有内容输出后,本轮对话的完整数据,server一次性提交并保存到DB(数据库)。
业务数据库的数据,可以用于产品的前端展示和其他用途,也可以用于后台产品的分析等。
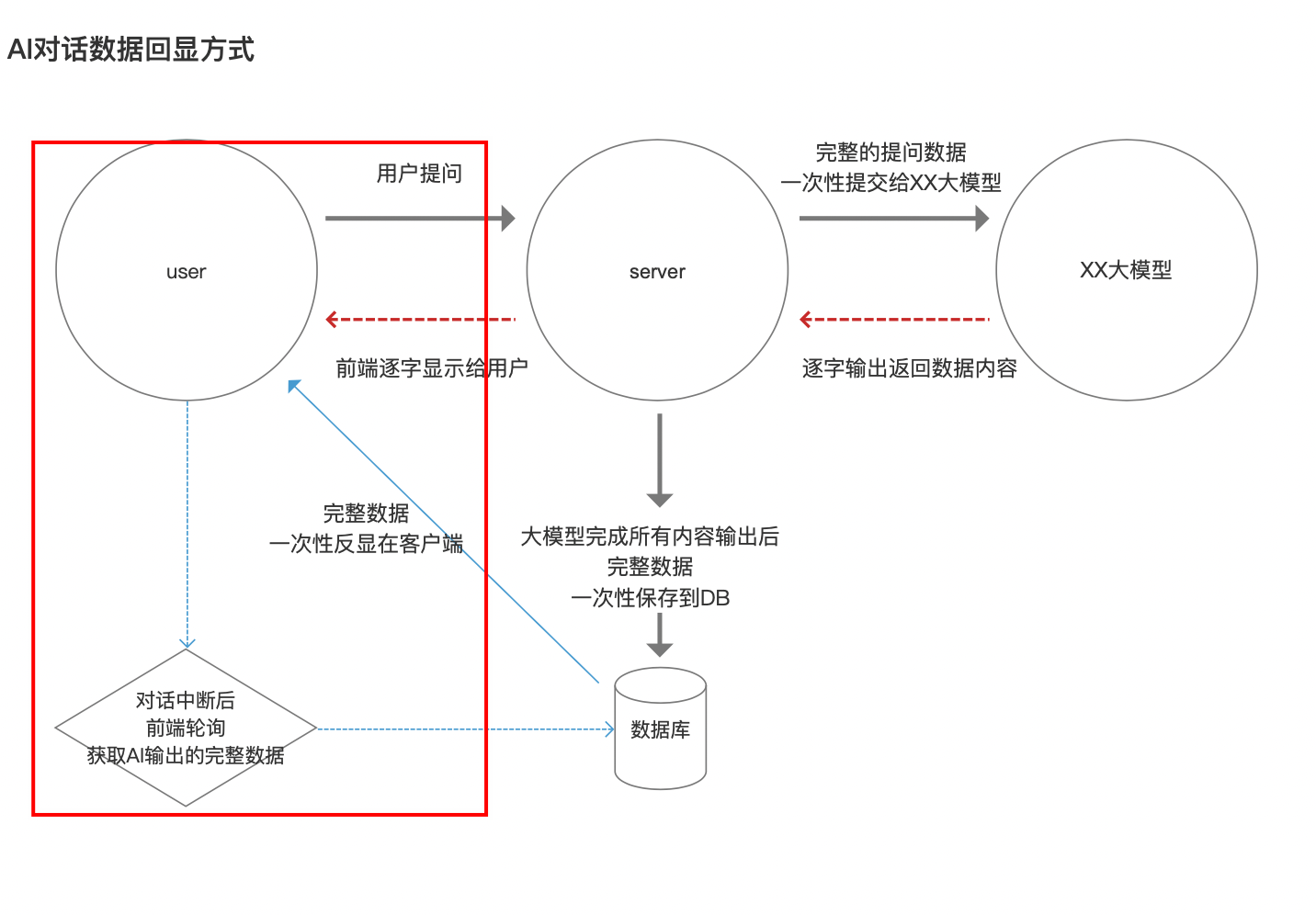
3. AI对话的数据回显方式
在不同场景下,数据回显到用户界面的方式不一样。
- 正常界面对话:打字机效果逐字显示;
- 对话中断后:前端轮询,获取AI输出的完整数据,一旦获取到,一次性全部展示在前端,非打字机效果;
- 中断网络:可通过对话记录,查看完整的数据,一旦获查看,一次性全部展示在前端,非打字机效果。
五、产品设计方案
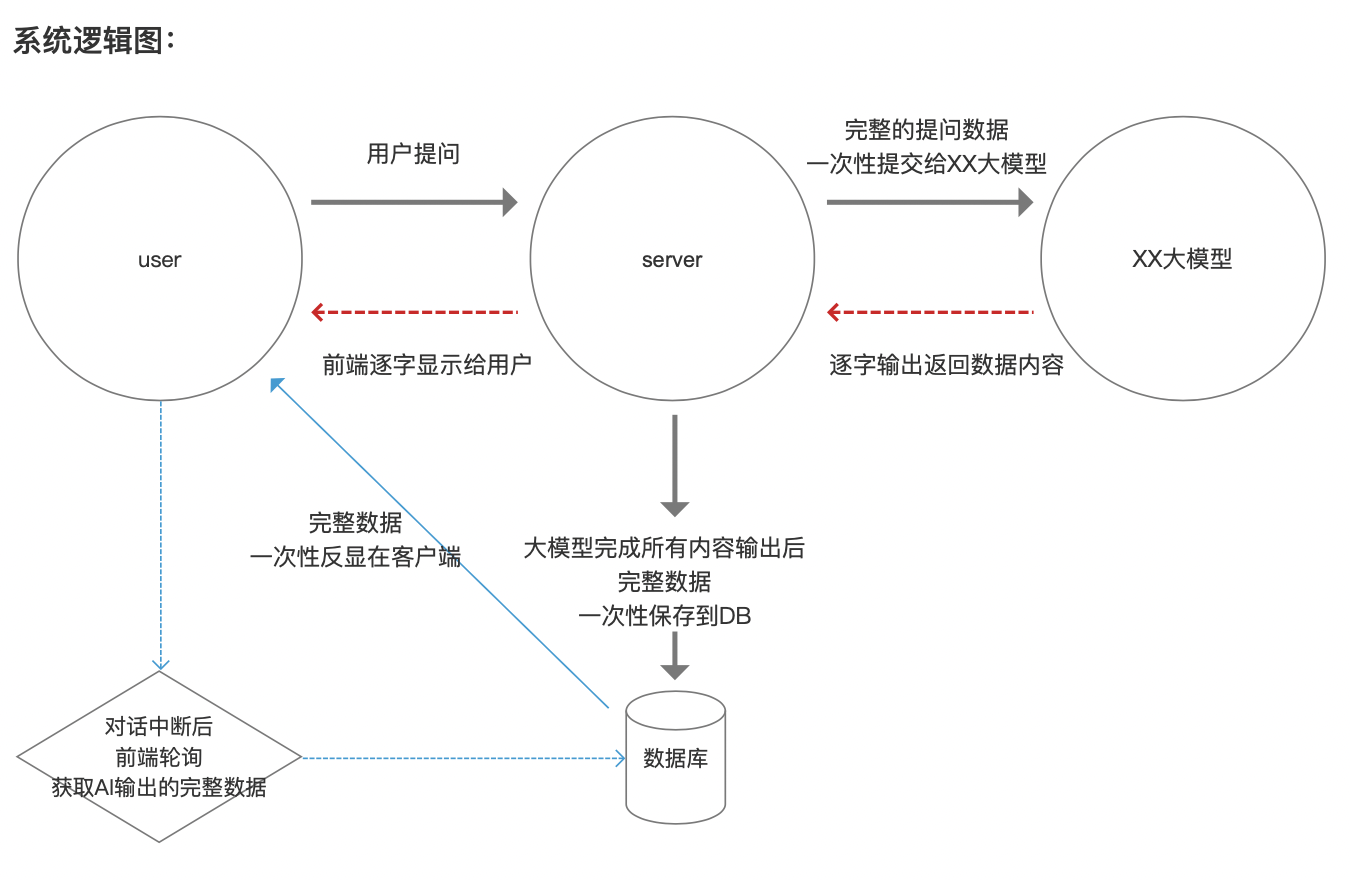
1. 中断场景①:网络终端、刷新浏览器、关闭浏览器
- 此种场景下,网络中断,当前对话框关闭;
- 页面刷新后,再次回到JiweiGPT,显示新的对话框;
- 刷新or关闭前的对话窗口收入到对话记录,可切换查看
- 用户再次切回原对话记录,能查看原提问的完整回答记录。

2. 中断场景②:切换浏览器页签、切换查看对话记录
- 此种场景下,网络未中断,用户未退出程序,只是不在当前屏幕上显示观看;
- 再次切换回当前对话,显示原残缺的不完整的数据;
- 同时,不可以再次发送问题,AI输出气泡有loading,告知用户AI正在输出中;
- 此时,前端需要轮询,请求服务端数据接口,一旦拉取到完整的回答数据,一次性显示在用户端的气泡;
- 此时,用户能看到完整AI回答。

六、小结
通过以上两个场景的需求分析和方案设计,本文提供了一个基于实践的、有效的解决AI对话中断的交互逻辑方案。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
