如何利用KANO模型,判断需求的属性归类?
一、为什么要用KANO模型?
小额付费产品经理的日常工作中,经常会同时接到很多需求,VIP改版、新产品形态掘金、支付页优化、花币后台优化、sqdb4.0添加注释等等需求,甚至sqdb4..0改版需求中,又涉及到提高算法准确度、添加信号操作建议注释、添加指标共振选股、增强及时提醒功能……
时间精力、开发资源、UI交互资源有限,尤其像今年上半年疫情泛滥的情况下,开发没有及时到岗,面对众多需求的情况下,为了保证收益的最大化,怎么进行取舍,哪些需求的属性是什么样子的,是否可以砍掉,怎么排序需求的优先级?以哪一种方式来确定才靠谱?
之前我们小额付费产品团队中,在处理类似这种优先级排序的时候,都是召集所有提需求的产品一起开个需求会,各自讲述一下自己需求的情况和紧急度,然后大家共同表决。虽然看起来很不错,很民主科学,但实际上在执行的过程中,每个产品经理都会把自己的需求吹的很紧急很重要,但没有给出一个合理公认的量化结论,以供参考,随意性还是特别强,几乎就是“看脸面”决定了优先级。
近期我们和用研的团队合作,做了几次调研,他们采用了一个新的模型–KANO模型来为我们的需求做了一个合理公允的分类,效果很不错。内部分享了这种模型之后,也在思考去建立一套适合小额产品需求的KANO模型。因此,今天要给大家介绍的就是这个工具: KANO模型。
二、什么是KANO模型?
KANO模型是东京理工大学教授狩野纪昭(Noriaki Kano)发明的对用户需求分类和排序的有用工具。通过分析用户对产品功能的满意程度,对产品功能进行分级,从而确定产品实现过程中的优先级。
KANO模型是一个典型的定性分析模型,一般不直接用来测量用户的满意度,常用于识别用户对新功能的接受度。利用这个模型,我们可以了解手上的这些需求是什么类型的,可以根据重要程度来取舍,比主观的随意取舍更为合理、科学。
KANO模型中,根据不同类型的需求与用户满意度之间的关系,可将影响用户满意度的因素分为5类:基本型需求、期望型需求、兴奋型需求、无差异需求、反向型需求。

2.1 基本型需求
这个是客户购买某个产品、使用某个功能时,最根本的需求。当不提供这个需求,用户满意度大幅降低,产品会导致客户投诉,续费率可能就直接为0。但优化此需求,用户满意度不会得到显著提升。好比sqdb没有给出红绿电波的买卖点;推荐股票的产品没有给出股票,而只给出仓位建议;手机level2没有给出十档行情,只给出大单净量的指标……

2.2 期望型需求
客户非常敏感的需求。当提供此需求,用户满意度会提升;当不提供此需求,用户满意度会降低。它是处于成长期的需求,是客户、竞品包括我们自身都关注的需求,也是体现竞争能力的需求。对应到我们付费产品的期望型需求的话,比如更高成功率的股池、越精准详细的操作建议、越及时有效的机会风险预警机制等等。

2.3 兴奋型需求
顾名思义,就是会让人兴奋欣喜的需求。这种需求是用户意想不到的,就像惊喜一样。
若不提供此需求,用户满意度不会降低;若提供此需求,用户满意度会有很大的提升。手机level-2刚开始只有10挡行情,但还是3秒刷新1次,但后面推出了全景委托队列需求,通过实时计算,将实时委托撤单数据累加到10挡上面,实现10挡委托能实时刷新,而非3秒一次的刷新,提高了数据更新的实时性,对短线客户帮助非常大,对他们来说这个就是兴奋型需求。

2.4 无差异需求
用户根本不在意的需求,对用户体验毫无影响。这种需求可有可无。无论提供或不提供此需求,用户满意度都不会有改变。比如:提供自选股的平均涨跌幅,我们通过调研得出这个是无差异的需求。

2.5 反向型需求
用户根本都没有此需求,提供后用户满意度反而下降。

总而言之,我们小额付费产品需求时,需要尽量避免无差异型需求、反向型需求,至少做好基本型需求、期望型需求,如果可以的话再努力挖掘兴奋型需求。
三、如何使用KANO模型?
KANO模型分析方法主要是通过标准化问卷进行调研,根据调研结果对各因素属性归类,解决需求属性的定位问题,以提高用户满意度。
我把使用模型的步骤分为3步:
第一步:明确调研的目的。
第二步:围绕目的设计问卷。
第三步:清洗数据与整理分类。
下面拿我最近一个需求实战案例–sqdb 是否添加信号说明注释,来讲解如何使用KANO模型。
3.1 明确目的
明确自己做问卷调研的目的,以便后面设计问卷题目的时候,能紧紧围绕目的来设计,确保后面得到的结果也是自己想要的。
例:
【背景】sqdb是公司最赚钱的小额付费产品,存量基数达到10万,产品的影响面是非常大,但使用满意度及复购率处于较低水平,一直有客户反馈信号太过单一,希望能提供有用的信号操作建议等注释信息。且当前还有好几个需求在排队,需要了解这个需求的类型,以判断其优先级。
【目的】了解用户是否需要对电波信号进行注解的功能,或者说信号操作建议注释功能对客户而言是什么样的需求,必备、期望的、还是无差异等,从而来确定这个需求的优先级。
3.2 设计问卷
问卷调查表划分维度有两个:提供时的满意程度、不提供时的满意程度。
而满意程度被划分为5级(非常满意、满意、一般、不满意、很不满意),因为人的满意程度往往是渐变的,而不是突变的。
满意程度的文案可根据实际问题灵活修改,如使用(非常喜欢、理应如此、无所谓、勉强接受、很不喜欢 或者 非常有用、挺实用、无所谓、不实用、很不实用 )更加形象的描述。
设计问卷的过程中,有几点要注意:
- 设计题目要紧紧围绕目的来设计,确保后面得到的结果也是自己想要的,设计的题目多和相关同事沟通商量,不断修改完善。
- 问卷中的每道题都涉及到正反两面,应适当给予强调,防止用户看错(比如正反对立词字体加粗/标红等等);
- 在设计问卷时,尽量做到清晰易懂、语言尽量简单具体,避免语意产生歧义
- 选项给予说明:由于每个人对“非常喜欢、理应如此、无所谓、勉强接受、很不喜欢”等形容词的理解都不一样,所以最好有一个明确统一的说明,让用户可以有个对照,方便填写。
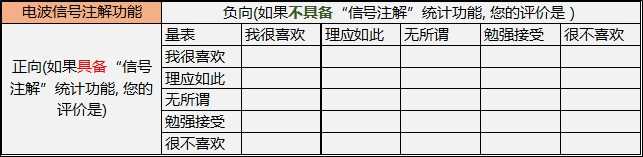
其实,满意程度的文案可根据实际问题灵活修改,如使用(非常喜欢、理应如此、无所谓、勉强接受、很不喜欢 或者 非常有用、挺实用、无所谓、不实用、很不实用 )更加形象的描述。
『例如』sqdb需求添加信号注释说明,题目可以这么设计:
- 非常喜欢:注释让你觉得信号更准,更有意义。
- 理应如此:本来就应该提供的、必备的功能/服务。
- 无所谓:有无注释,没影响,都可以接受。
- 勉强接受:注释不太喜欢,有的话,我也不看。
- 很不喜欢:注释很厌恶,影响判断,千万不要给。
3.3 数据清洗、分类
得到问卷结果后,处理掉一些乱填的客户数据后,整理统计得到最后以下结果表。


按照最早模型的统计口径来说,属性维度占比最大的就是该需求的属性类型,从上面的得分可以看到无差异属性的占比为44.2%,说明这个需求就是无差异需求。
但是,由于采用问卷的形式,客户填写的随意性很高,很多答案都没有经过认真思考就得出来的,因此会发现最后做了很多需求,利用这个模型反馈都是无差异的。所以,不代表这个需求不做,还是要看其他属性的占比情况,因为这些属性也代表着部分客户的需求。
因此我们需要利用另一个指标来确定需求的属性类型,最后再确定其优先级。这个指标叫做『better/SI 和 worse/DSI 指数』,通过计算这个需求的的better/SI 和 worse/DSI 指数,并标志在四分位图上,来确定这个需求的类型。
下面我们再来讲一下什么是better/SI 和 worse/DSI 指数,以及它的计算方式。
3.4 计算better/SI 和 worse/DSI 指数
Better指数,可以解读为增加后的满意系数。Better的数值通常为正,代表如果产品提供某种功能或服务,用户满意度会提升。正值越大/越接近1,则表示用户满意度提升的效果会越强,满意度上升的越快。
增加后的满意系数 Better/SI=(兴奋型指数+期望型指数)/(1-反向型指数-可疑型指数)
Worse,可以叫做消除后的不满意系数。Worse的数值通常为负,代表产品如果不提供某种功能或服务,用户的满意度会降低。其负值越大/越接近-1,则表示对用户不满意度的影响最大,满意度降低的影响效果越强,下降的越快。
消除后的不满意系数 Worse/DSI= -1 *(期望型指数+基础型指数)/ (1-反向型指数-可疑型指数)
因此,根据 better-worse系数,两者系数绝对分值较高的项目优先级越高。
通过上面的计算公式,可以得到sqdb添加信号注释的Better/SI和Worse/DSI指数:
- 具备信号注解功能的满意度系数(Better/SI)为26.8%
- 消除信号注解功能的不满意系数(Worse/DSI)为-30.3%
以此推知信号注解功能属于为必备功能(表示当产品提供此功能,用户满意度不会提升,当不提供此功能,用户满意度会大幅降低)。当前sqdb不具备此功能,需要增加注解功能。

至此,我已经介绍完了如何利用KANO模型来判断需求的属性归类。当然这个过程周期是比较长,所以一般都是多个调研需求一起做,减低调研的成本。另外,这个KANO模型也是比90年代提出来的,08年外国有人研究出了一个更为科学,谨慎的KANO模型,但因为过程更为繁琐复杂,因此比较难以实施,有兴趣的同学可以找我要一份相关的资料。
本文作者 @新时代过客 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
