爬虫数据采集技术趋势-智能化解析
用一句话概括爬虫工程师的工作内容,就是We Structure the World's Knowledge。

爬虫工作内容
互联网作为人类历史最大的知识仓库,是没有充分结构化的。目前互联网仅仅是一些文本等多媒体数据的聚合,内容虽然非常有价值,但是程序是无法使用那些没有结构化的数据。
在2006年左右,有专家提出的web3.0,语义互联网,知识共享。虽然现在开放API,SOA概念越来越普及,真正语义上的互联网的时代似乎还非常遥远。因此爬虫依然是最重要的手段,一端不断解析,聚合互联网上的数据,另外一端向各种各样的的应用输送数据。
现有爬虫开发技术存在问题
从招聘市场岗位需求可以看出,近年来对爬虫工程师需求越来越强烈。
个人判断原因有两个:
信息聚合是互联网公司的基本需求。
数据时代到来,对数据更强烈的需求。
下面是我整理的部分靠爬虫聚合信息的创业公司,按照时间顺序排序:
搜索引擎聚合了网页:百度,google,
机票比价网站:去哪儿,聚合各大航空公司票价
团购平台:团800 聚合了团购网站信息。
比价网站聚合了各大电商平台的商品价格:美丽说,蘑菇街,一淘
记账理财产品聚合和消费者,信用卡,银行卡信息:挖财和铜板街。
新闻聚合平台:今日头条
p2p平台聚合各大p2p借贷公司的信息:网贷之家,融360
风控公司需要收集企业公司,财务司法等信息:鹏元
征信数据会收集了贷款者司法,社交,财务,大量和征信相关信息:聚信立,量化派,zestfinace
最后5种类型,几乎2014年都是开始。很多金融场景相关应用开始出现,这就对准确度和可靠性提出了更高的要求。但现有的爬虫开发技术能否满足高可靠,大规模,高效率开发需求呢?
从软件工程角度来看,一件事情如果无法评估,那就无法管理。爬虫开发经常是被吐槽的原因之一,就是工作量常常无法评估。一般的软件项目的开发过程随着时间推进,工作量会逐渐减少,也是大家经常说的燃尽效果。
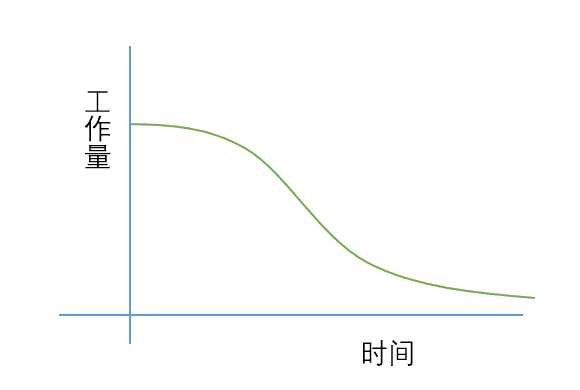
而爬虫开发生命周期如下图:
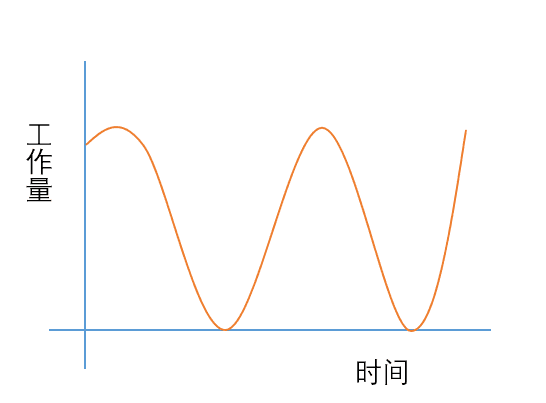
爬虫开发主要有两个方面内容:下载网页,解析网页 。解析网页大概占据开发工作的80%左右。
下载网页功能的开发工作,会涉及IP限制,验证码等问题,这样问题都是可以预期的。同时,随着现在优秀的爬虫框架和云服务器的普及,问题解决起来会更轻松。
编写解析代码,虽然有一些基本工具chrome,firecdebug可以使用,但始终需要人工分析,编写解析规则。无论是使用xpath,正则表达式,css selector,都不能减少这一部分的工作量。
大量重复性工作会导致以下两个问题:
即使同类型的网页看起来99%是一样,也需要编写独立的爬虫。这就会给人这样一种感觉——爬虫开发大部分的工作内容是重复的。
数据源网页改版,几乎整个爬虫项目需要重做。重做的工作量几乎是100%,爬虫工程师心中往往是一万只羊驼跑过。现在很多征信数据采集公司的合作伙伴,当数据源网站改版,常常需要一至两天才能修复爬虫,很明显这种可靠性是无法满足金融场景需要。
智能化解析
这是一张新浪新闻的图片。
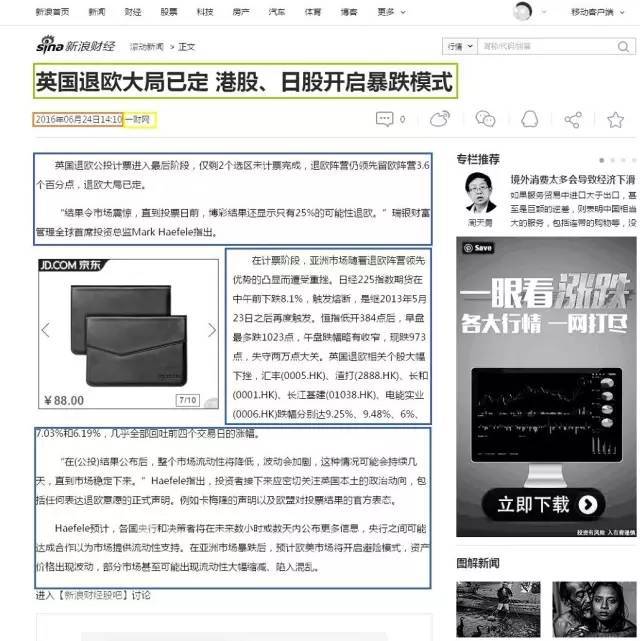
可以发现,视觉上很容易了解到,新闻所报道的事件的标题,发表时间和正文。自然也会想到,能否通过一些机器学习的算法达到自动解析的目的?这样就不用人工编写解析额,减少重复劳动。在2008年开始,就要研究机构发表了相关论文。
www.cs.cmu.edu/~deepay/mywww/papers/www08-segments.pdf
research.microsoft.com/en-us/um/people/znie/p048.special.nie.pdf
也就是在2008有一家相关的创业公司,在斯坦福大学孵化。
DiffBot智能化数据采集公司
总部位于加州的Diffbot成立于2008年,创始人Mike Tung,是斯坦福毕业研究生。Diffbot是通过人工智能技术,让“机器”识别网页内容,抓取关键内容,并输出软件可以直接识别的结构化数据。其创始人兼首席执行官Mike Tung表示,“Diffbot现在做的,相当于人类在浏览网页文章时所做的事情,找出页面中最核心的相关信息。”目前Diffbot已经发布了头版API和文章API,还有产品API。服务的客户包括三星、eBay、思科、美国在线等。
Diffbot的理念就是通过“视觉机器人”来扫描和识别不同的网页类型(主要是非结构化的数据),再将这些丰富的数据源用于其他应用。Mike Tung表示:“我们在获取页面之后会对其进行分析,然后通过成熟先进的技术进行结构化处理。”之前我提到的we structure the world's knowledge,就是该公司提出的理念。
Diffbot在基于智能采集的基础上,又开发出很多数据产品,比如知识图谱,智能商业BI。在2016腾讯与硅谷风投机构Felicis Ventures领投了人工智能创业公司Diffbot 1000万美元的A轮融资,很多互联网巨头开始发现这家公司的价值。
算法实践
通过智能方式来解析网页需要两个步骤:
基于视觉上的网页分割,将网页分割几个视觉块。
通过机器学习训练的方式来判断各个视觉块的类型,是标题,还是正文。其中主要流程和一般机器需要流程没什么区别。这就不详细解释。使用到使用的开源框架有:scikit-learn,phantomjs
Scikit-Learn机器学习库已经非常成熟,很容易上手。
phantomjs,是一个headless webkit渲染引擎。做爬虫开发的同学应该非常需要。
网页分割算法
从Diffbot早期发布的文章来看,是通过图像处理的方式来切割视觉块。使用到的算法有,边界检查,文字识别等算法。但这种方式计算量偏大,复杂度很高。
另外一种实现方式是基于Dom树结构,导出所需的视觉特征。
聚合时候需用的特征变量。主要考虑视觉相关的因素有元素在页面上的位置,宽度和高度,Dom的层次。
有一点需要注意的是,现在网页很多是动态生成。需要借助phantomjs工具来进行动态网页渲染。
聚类算法可以选用的DBSCAN,DBSCAN算法优点是更加密度来划分,比起K-mean算法的优点,是处理任意形状的聚合。
具体的实现方式可以参考下面博文:http://blog.mapado.com/web-page-segmentation-by-visual-clustering/
分类算法
在第一步处理后,网页上的标签,会被划分分若干类,需要判断标签的类型,是否是标题,正文,广告,导航之类。需要整理出类似下面的,训练矩阵。


整个学习过程与一般的机器学习训练过程没有区别。由于数据样本规模不大,分类算法基本算法采取。分类算法可以选用朴素贝叶斯,或者SVM。
总结和展望
本文介绍的方式比较粗略,一般来说解析模型只能针对特定的网络训练解析模型,比如新闻,电商产品页。所以不同类型的网页,所需要的特征变量有较大差别。针对不同特点类型数据,需要大家自己花时间去探索和实践。
随着数据时代和智能化时代到来,爬虫作为重要的数据来源,自身需要一些技术提升来适应时代的要求,这也就对爬虫工程师提出更高的要求。成文粗陋,权且当做抛砖引玉,欢迎大家留言讨论。
本文作者: 李国建(点融黑帮),现就职于点融网成都团队Data Team,喜欢研究各种机器学习,爬虫,自动化交易相关的技术。
关键字:产品经理, diffbot
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
