漫谈 Spark 数据平台下的应用及编程
Spark 正在成为下一代大数据分析和处理的平台,这种趋势越来越明显。

但是,就在一年以前,笔者曾做过多方面的咨询和了解,那时Spark 还没有大规模地在各大企业应用起来,即使当时某些企业已经运用Spark,大多却还只是在开始局部性的尝试,其主要业务和数据仍然运行在Hadoop 数据平台上。
说起来,笔者对Spark平台的应用经历也是从一年前才开始,从尝试到最后熟练的应用,也算是经历了不少波折。当时自己安装部署的是1.4.0版本,SparkR 也是从那个版本正式纳入成为Spark 一部分的,由于需要做金融大数据分析,很自然的专门选择了SparkR 。但是接下来的经历令人印象非常深刻,SparkR当时在项目中根本没法用,即使最基本的,它的很多API在集群中运行的结果是错误的,甚至是随机的(当时的测试,在本地多线程模拟集群环境下,结果是正确的)。
一开始遇到有API错误,经常在深更半夜不断地去检测是否是人为错误,确定不是人为错误之后,笔者会想各种办法去绕开使用错误的API ,还曾向开发Spark 的伯克利大学的教授多次发邮件寻求帮助。随后又发现接连好几个其它API错误,于是果断暂时放弃了SparkR ,转而使用Spark 的其它部分。
最后选择的是基于Java 语言的Spark 应用(RDD,SQL,ML和Hive),之所以选择Java而不是Scala ,主要原因在于,那时并不保证Spark的其它部分没有Bug 而可以顺利运用到项目里去,并且,在项目上线时间已很紧迫的情况下,传统面向对象语言Java远比Scala好把握(开发进度和调试)。
本文内容主要讲的是基于Java 的Spark 应用及编程,来自于个人实战和学习的一部分要点提炼和总结。
其实,即使到现在,整个网络上和实体店都找不到一本比较好的关于Spark应用的中文或英文书籍,同时也没有来自外界同行比较成熟的应用经验可供借鉴(同行经验方面现在可能稍好一些)。关于Spark 的应用,官方文档是其唯一可靠资料。
但是,个人以为,官方文档也存在一些问题,比如Spark 的相关内容太多,但是官网里对一些内容描述实在不甚清楚,有些内容的描述甚至没有任何提及。因此,个人摸索便成了办法之一。
关于编程
Hadoop 的map-reduce 计算框架高度的精炼和抽象,是Hadoop 平台的重要基础之一。
但是map-reduce框架也有比较大的弊端:
一方面,Hadoop 的shuffle 和过多的磁盘IO导致map-reduce 框架运行速度太慢;
另一方面,map-reduce 固有的框架使得很多原本并不适合运用它来进行编程的问题,特别是一些要求反复迭代的作业。
于是,不断的尝试转换作业形式和过程以使它方便套用map-reduce 框架,成了某种需要。对此,Spark 在很多方面做了长足的改进,比如Spark 可充分的基于内存操作,有向无环图DAG 的方式执行作业,shuffle 的改进,作业失败后从前面某一步而不是第一步开始重新执行作业等等,让Spark 的运行速度相对Hadoop 有几十倍甚至百倍的提升。
因此,相对Hadoop 的离线计算,Spark 是近实时的。同时,Spark的算子很多且非常丰富,远远不止Hadoop 只有单纯的map , reduce 和combine 若干几个,这使得Spark RDD 可以很方便的运用到各种场景的应用作业里面去。
关于Spark Java 的RDD 编程,其实也挺意外,有不少写法,看起来挺正常的,官网没有特别说明,编译也没有任何错误,运行时就是报异常或错误,甚至错误日志看起来也和错误代码处不搭界。
以下给出部分Spark Java编程的若干要点:
RDD 的行数有限制,最大行数大概是200万行多一些,不然RDD 会溢出。在某些场景下,大行数RDD 用的上;
RDD 包含transformation 和action 两种算子,但是,一个RDD 连续的transformation 算子个数有限制,不然调用堆栈会溢出。解决办法可以在中间某个transformation 算子之前执行一次checkpoint ,或者插入某个简单的action 算子,比如first 或take ;
派生算子类Function 系列,似乎必须和static 扯上,即Function 派生类必须定义成static函数的内部类或匿名类,要么必须定义成函数外部的static类,不然,运行时会报错;
HiveContext 和SQLContext 不可混用,也就是一个类对象如果是用HiveContext 创建的,那么它不可用SQLContext来执行SQL操作,反之亦然。这应该和两个Context 的底层实现有关系;
一个类对象将用于Hive或SQL操作,该类必须是public static 的,且实现Serializable ,该类各个成员变量必须有set/get 方法(应该用到了类Java的反射机制,其实set如果不需要也可以不用写),并且,get方法的函数名有要求,比如一个类有成员变量名为abcd , 则其对应函数名必须为getAbcd ,不然,运行时会报找不到该表列名错误;
如需按行操作RDD ,可考虑用zipWithIndex 。
关于运行错误调试和作业调优
1. cache 有时候需要多用,有时候却又需要尽量少用,collect 某些时候要慎用,因为collect 涉及到将各个node 的所有数据都通过网络传输到drive ,所以,大RDD 的collect 会非常耗时,不是必须的情况下,可考虑用take;
2. 擅于用mapPartitions ,某种程度上它可以替代filter ,并且在某些场景下mapPartitions 比map 效率高,要注意mapPartitions 对只有空返回分区的特殊处理;
3. Broadcast 和传参,是解决外部变量和Function 系列派生类打交道的两个方法,对于大的常量应用Broadcast ,可提高效率。但是,外部变量有时难以用于Broadcast ,这时候可给Function 系列派生类定义一个成员变量,在调用的时候创建并将外部参数传递给它;
4. Spark 集群有standalone ,mesos 和yarn 三种安装模式,本地多线程也可模拟集群模式。经常在Spark 社区看到有人问关于Spark 的一些难题,有时却是由于不同安装模式导致的,这一点要注意了,yarn 据说是最有前景的方式,由此也共享了Hadoop 的框架,个人喜欢用yarn 模式;
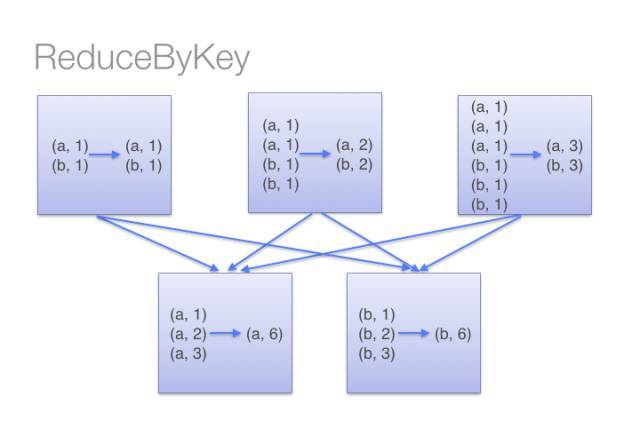
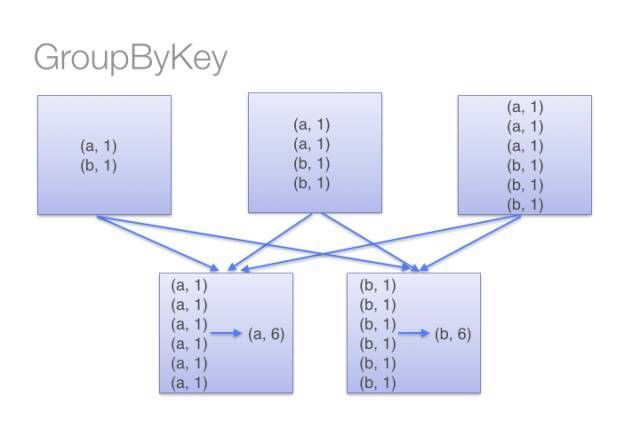
5. groupBy, reduceBy和aggregateBy比较
一个RDD包括多个partition (分区),其所有partition 可能分布在集群不同的node 上,同一个partition只能在某一个node 上。RDD 的分布式和并行性,即是partition 层面的。假如RDD的某一个action算子需要同时读取来自不同分区的一些数据,这时候就需要通过网络IO或磁盘IO将位于不同分区的那些数据汇集到一处以作下一步的操作,这就是Spark 的shuffle (混洗)。由于shuffle操作涉及到网络IO 和磁盘IO ,所以shuffle 的操作总是很耗时的,于是,尽量减少shuffle的次数和传输的数据量,是提高Spark作业运行效率的一个方法。
能用reduceBy 的时候尽量不用groupBy ,reduceBy 需做两次合并操作,一次在shuffle 之前,一次在之后,经历过之前一次合并操作,合并后的中间数据量会大大减少,从而减少shuffle过程中IO的时间,提高了运行效率。groupBy 只有shuffle 之后一次合并操作,所以在它shuffle 过程需传输的数据量大而影响了效率。
当Pair RDD 指定列的输入和输出类型不一致的时候,应不要用reduceBy ,而考虑用aggregateBy 。比如,需要找到Pair RDD各个key的所有不同的value ,如用reduceBy,可考虑输出类型为set,于是,每一次都需要为新的set 动态分配内存空间,效率很受影响。aggregateBy 在map 端做聚合操作会更高效。
关于reduceByKey 和groupByKey 的图解示意图如下:
6. out of memory (OOM)问题若干解决办法
内存溢出OOM 可以说是运行Spark 作业时经常遇到的问题,特别是对运行时间比较长的大作业,可能同一个应用程序运行在较少量数据上一直表现良好,一旦运行在大数据集上问题立马出来了。导致OOM 的原因比较多,有些还很复杂,于是解决方法也不尽相同。个人感觉,解决OOM 问题的过程,有时某种程度上也是对Spark作业进行优化的过程。
导致OOM 的原因之一,可能是作业内部action 过程比较多,需要不断将集群上的数据下到drive 上来,如当时drive 上内存不够,很可能就产生OOM 了。当时drive上空间不够,可能是系统本身分配给该作业的drive 内存资源就不够,也可能是作业前面阶段消耗的内存太多导致后来的阶段不够用了,还可能是action (比如shuffle )内部过程本就有较多内存需求但又给予其分配的空间不够。
以下是对于解决OOM的若干方法:
设置spark.executor.memory 尽可能大,可为接近集群单个node 的所有内存
用更多的partition ,其数可等同于CPU数,适当分区数目的设置对作业运行效率及稳定性影响挺大
设置spark.storage.memory.fraction 更小,默认其值为0.6,是专预留给cache 用的,剩余内存给作业其它部分用。尽量少用cache,经验看来也有挺大帮助
如OOM 发生于shuffle 过程,则应增加shuffle 阶段的内存数量,设置spark.shuffle.fraction 为更大值
对大对象多用Broadcast
可能是内存泄漏导致的问题,一般检测日志会有类似“task serializable as xxx bytes”, xxx一般大于几M , 内存泄露本就是严重的问题,这时首先需要解决的当然是内存泄露自身
命令行提交作业,--drive-memory 尽可能设更大。并不意外,实践表明,这一条往往成功解决了OOM 问题
应该说,Spark 解决了Hadoop 的很多弊端,相比于Hadoop它取得了很多长足的改进。首先是速度上,Spark 运行效率提升了几十甚至百倍,相对于Hadoop ,Spark是近实时的。
随着版本迭代,现在Spark 系统也越来越稳定了。
本人曾基于RDD 编程,实现过股票基金投资组合的最优化系统,主要是用它完成了带复杂约束条件的完整的遗传算法过程,测试下来,相比于量化研究员们惯用的R加SQLServer 的传统做法求解最优化,RDD 方法不论运行速度还是最优化结果都获得了很大的提升,运行时间从一两个小时缩短到了两分钟,最优解提升了百分之二十。当然,也曾考虑过Java单机应用程序是否可能效率就足够好甚至更高,不过,排除多个请求作业并行运行需求之外,当遗传算法初始种群数量比较大,染色体数量比较多,约束条件很复杂,所需繁衍后代次数非常多的时候,应该可以判定Spark 平台下的RDD 应用系统仍然会有明显的优势。
Spark ML 机器学习算法库,经过实战,表现还是很不错的。做数据挖掘项目,有时可能训练样本数量特别多,也可能需要同时运行比较几百个模型,这在单机下要跑很久甚至跑不出来,但是,应用Spark ML 库可在合理的时间内运行完成。
HBase 的速度相对比较快,它解决了传统单机数据库如Oracle 可扩展性差的问题。但是HBase的实时性只是相对于map-reduce 的低速来讲的,特别是当做大表的join 操作时,HBase/Phoenix 的问题表现的很明显。有内部测试表明,20张表作join 操作,其中大的表有几亿条记录,小的表纪录数也在百万级,HBase 上几乎跑不起来,但是Hive on Spark 只要半个小时就运行出结果了。事实上,Hive on Spark已经在一些企业运行起来了,并且反馈的结果都很不错,在某些地方,Hive on Spark 也已经逐步替代HBase/Phoenix 成为新的大数据平台下的数据仓库了。
可以预见,在不久的将来,Spark 终会在大数据平台里扮演远比Hadoop 更为重要的角色。
本文作者 :朱志亮(点融黑帮),复旦大学计算机系研究生毕业,有三年多传统IT经验和一年多互联网大数据经验,对大数据平台和数据挖掘兴趣很大,目前主要专注于大数据平台下的数据挖掘。
关键字:产品经理
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
