产品常用的策略方法
一、引言
最近工作的重心都在跟数据打交道,各种各样的数据呈现及内在挖掘都要定策略,加上之前在产品策略方面的经验,因此对常用的一些策略方法做一个总结梳理,算是抛砖引玉吧。
二、概述
结合实际的工作场景和经验,会从以下几个层面分别进行展开:
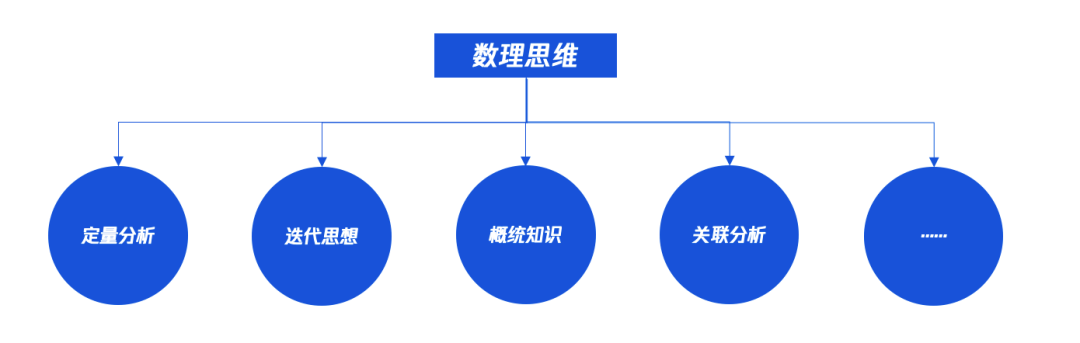
- 定量分析:如何将定性、不确定的场景/因素进行量化的数据表达。
- 迭代思想:数据持续变化,如何利用数据构建可靠的模型,进行深度挖掘?
- 概统知识:基础的概率统计学知识在数据分析中那是必不可少的。
- 关联分析:数据林林总总,不同的维度/事务是否存在千丝万缕的关联?
当然,这样的拆分是基于个人的经验,不见得多么合理,其实是会存在很多的交叠,也只是冰山一角,所以活到老学到老。
三、定量分析
在实际的工作场景中,常常会碰到各种需要拍脑袋的场景,定性的成分占比较大的比重,除了基本的服务性能外,其他难以定量考评。
举个例子,我们对于作者进行评级的时候,常常会在作品量、播放量、粉丝量和互动量这几个指标之间纠结,到底谁更重要,重要多少呢?
一番激烈友好的讨论之后定下来“播放量>粉丝量>互动量>作品量”之后,那每个的权重又是多少呢?
哎,祭出个“4-3-2-1”的圣诞树阵型吧,分别赋予权重0.4,0.3,0.2,0.1吧——这种场景重复见到了好多好多次,历史不会重复它的事实,但是历史会重复它的规律,欢迎对号入座。
在这边推荐层次分析法(AHP):
充分利用人的分析、判断和综合能力,广泛应用于结构较为复杂、决策准则较多且不易量化的问题。层次分析法主要和专家调查法一起运用,以提高评价体系的置信度。
大体框架如下:
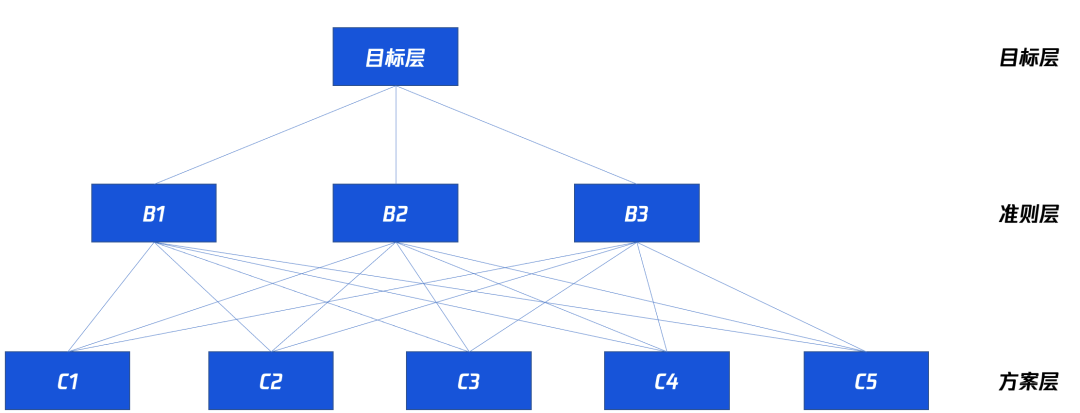
- 将复杂/模糊的测量对象概念化,进行多个明确指标的拆解;
- 对各指标间的关联进行具体分析,建立多层次的递阶结构;
- 在同一层次上的指标,两两进行相对重要性比较,建立判断矩阵;
- 计算要素的相对权重值,并进行一致性检验;
- 计算各层次元素对于系统目标的合成权重,进行总排序。
具体的实施步骤就不再详细展开了,可以参考具体案例。
以后再碰到定性问题定量化,不妨试试看。
四、迭代思想
世界是动态变化的,我们碰到的各种各的场景、数据都是不断演变的,而他们的演变不是孤立的,基本上都是基于之前的情况变化的,包括熟知的天梯积分,各种各样的排行榜:
这里通常采用的有以下几种思想:
随时间的衰减,这个最有名的当属艾宾浩斯遗忘曲线,以及半衰期的概念,这个给到的指引,通常就是在处理过往数据时候的进行衰减降权:
- 在处理内容热度的时候,对上一时刻的热度进行某一个指数的降权,再结合当前时刻的各种热点指标进行组合;
- 当时在教育行业,负责知识点掌握度的时候,最早给定的粗暴逻辑是对知识点掌握度按照周进行衰减,到某个阈值的时候不再衰减,当时虽然比较简单,但基本能跑起来。
基于对抗的迭代提升,这就不得不提ELO算法了,简单来说就是基于双方前置的能力值来评估对抗的预期表现,如果实际表现好于预期则能力提升。
反之能力下降,非常朴素的思想,但广泛使用在各种竞技场景,比如国际象棋评分、国际足联国家队排名以及Dota等电子竞技游戏。
以国际足联的积分为例,可以简单了解一下(截图自摘自国际足联官网):

基于ELO算法的思想,当时在负责教育项目知识点掌握度的时候,我做了一个大胆的尝试:
其实可以把做题类比于人跟试题进行对抗,人的能力其实可以看做知识点掌握度,而题目的能力则可以用试题的难度来表征,所以基于这样的思考,对于整个知识点掌握度做了一个大版本的更新,整体的效果反馈比之前要更加准确。
另外也在思考同样的方法是否可以用于作者的挖掘,初步的想法是:
可以分别表征某个作者的阅读影响力、互动影响力、创作影响力等等,以阅读影响力为例,作者在上个周期的阅读影响力去预估他下个周期的阅读影响表现(比如篇均阅读量,可进行全局归一化处理),如果实际表现好于预期那么阅读影响力提升,反之下降,最后对多个因素加权综合(前面的定量方法也许就排上用场了)。
五、概统知识
跟数据打交道,必不可少也不可避免的需要有基本的概率论与梳理统计的知识做支撑,不然一直拍脑袋头都拍秃了,凡事还是得有理有据的。
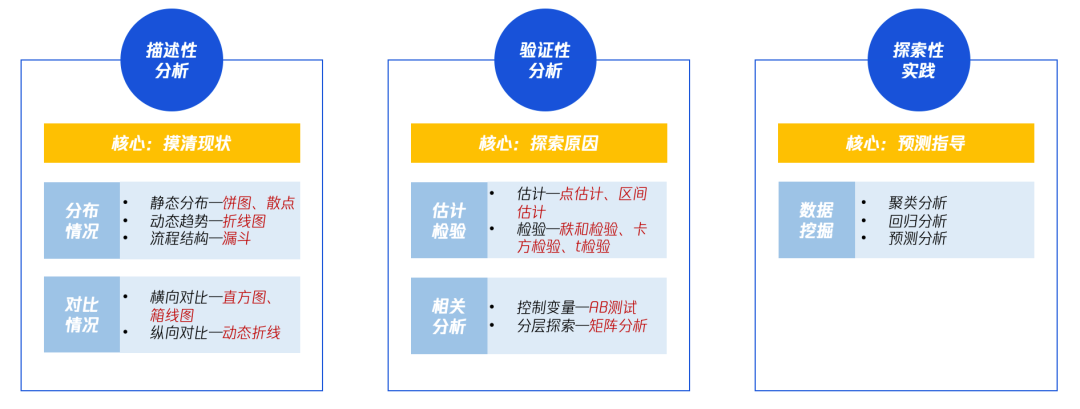
在进行数据处理的过程(其实产品的逻辑也一样)无外乎就是三件事:
是什么、为什么、怎么办?
所以基于这三件大事,分别要做好的就是以描述性分析来刻画现状、以验证性分析来探索原因、以探索性实践来指导后续工作,在上图也做了简单的总结。
当前游戏整体在推内容带发行,一般会就这这个跟同事或者面试的同学讨论,如何来论证看过游戏内容的用户在游戏内的活跃或者消费更高。这里就不展开了,有兴趣的可以一起讨论。
六、关联分析
这个单独拎出来,主要因为在过往的工作场景中经常碰到,觉得特别好用,好东西就推介一下吧。
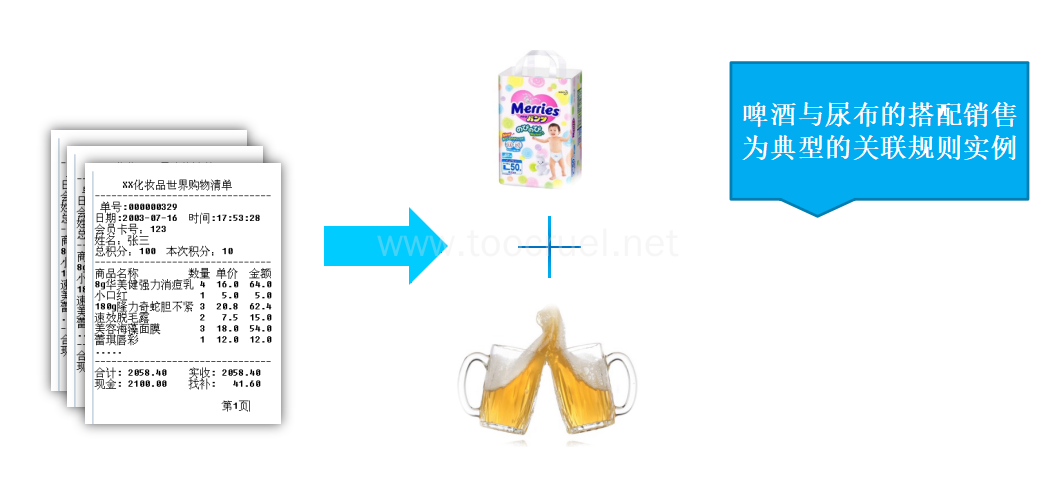
这个最有名的当属啤酒和尿布的例子了:
67%的顾客在购买啤酒的同时也会购买尿布。
超市有一个很有趣的现象:货架上啤酒与尿布竟然放在一起售卖,这看似两者毫不相关的东西,为什么会放在一起售卖呢?
原来,在美国,妇女们经常会嘱咐她们的丈夫下班以后给孩子买一点尿布回来,而丈夫在买完尿布后,大都会顺手买回一瓶自己爱喝的啤酒(由此看出美国人爱喝酒)。
商家通过对一年多的原始交易记录进行详细的分析,发现了这对神奇的组合。于是就毫不犹豫地将尿布与啤酒摆放在一起售卖,通过它们的关联性,互相促进销售。“啤酒与尿布”的故事一度是营销界的神话。
在过往的教育场景中,对试题进行详细分析的时候,通常会对知识点、模型方法等维度进行拆解,去总结经常一起出现的知识点,一起出现的知识点和方法,这个在知识图谱和相关试题推荐上起到了关键性作用。
七、总结
以上基于个人的实践经验和闲暇思考做了一些整理,越来越觉得“学好数理化,走遍天下都不怕”。
整体的梳理相对还比较粗浅,期望能够借此跟大家交流讨论,借助讨论碰撞和持续的实践探索不断的修正完善。
作者:youngyue,腾讯IEG高级产品运营
本文作者 @腾讯大讲堂 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
