如何设计销售CRM×运营CRM×社交化SCRM系统?(五) 如何设计数据工厂系统?
上文我们已经讲了运营推广系统的业务逻辑设计、角色职能和功能权限的分析。那么接下来终于轮到我们期待已久的【数据工厂系统】了!老样子,我们先来回顾下之前的【数据工厂系统】架构图:

对这个系统的解读,我们可以从以下几个角度出发。
一、系统的主要目的是什么?
数据工厂系统顾名思义,它的主要目的是对线索库千辛万苦收集来的数据进行智能、人工清洗的行为,以达到线索较真、修正错误信息、补全线索关键内容、实现触达线索客户可能性的目标。归根结底,我们可以认为它是一个负责数据修复、优化、校对、加工的智能数据工厂:

这里也要强调一下,不考虑关键字段信息的数据加工,不是合格的数据加工模型,打个比方,你把线索的信息补全得天花乱坠、完美无瑕,可是唯独少了联系方式或联系方式错误,在根本触达不了真实客户的情况下,这条线索再怎么修补也是没有价值的,只能扔进废纸篓。
二、一般在哪里使用这套系统?
数据加工系统一般可独立运作,专人负责,它的数据来源于线索库,它最大的特色是要支持充分发挥EXCEL的优秀特性,高频次的批量导入执行对线索库海量数据的高效更新清洗动作;所以做好这个导入、去重清洗功能是重中之重。
而且它也是高频使用的一套系统功能,一般建议在各个相关的实体数据业务系统操作上尽可能全面的进行埋点,通过其它系统的操作行为,自动执行关键的数据清洗动作,大大降低人工人力成本,当然你要一条条的拿着几份EXCEL人工录入更新线索数据,那我也不拦你,这个可谓是20年前的工作方式,极为低效,当然如果是培训员工对数据处理的专业能力,那可以尝试。
三、用户是谁?
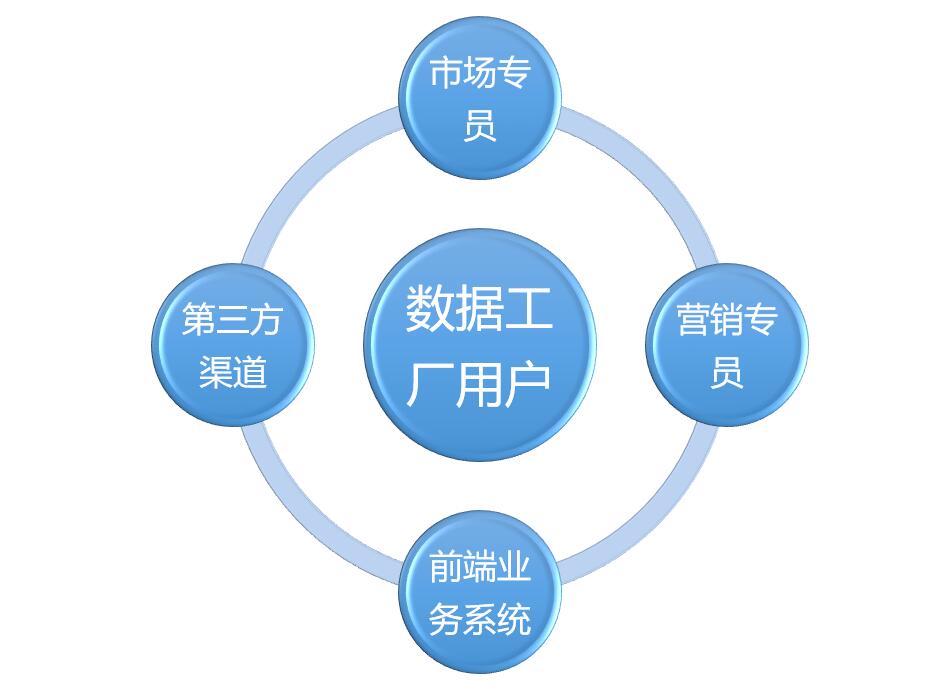
数据工厂系统是独立的一套工具型系统,它不需要复杂的层级关系,它一般直接面向市场部、客服部,由负责收集线索的人接着进行加工清洗,除此之外,其它所有前端系统都是它的用户,通过埋点行为来自动触发修复规则,以对线索数据进行一定的修复、加工。
1. 比如市场部、客服部的用户,可以根据自己一对一沟通、获取到的客户最新内容,人工的对某条数据进行清洗,还可以进行一定的批处理操作,如导入收集到的EXCEL数据,然后对冲突进行同类项批处理判断,虽然不能完全代替人工,但要尽可能人性化,大大提高用户的工作效率;
2. 对于其它全量的前端系统,则只要根据用户在当前系统上的操作,在满足指定的清洗规则时,自动触发对数据的清洗修正操作,比如有用户修改了手机账号(通过新旧手机验证码),那么就要自动把线索的联系手机给自动修正,记录LOG,无需任何人工干涉。
3. 如果会活用第三方渠道,那大可以把埋点埋到提供给第三方渠道的引流URL上,这样能更为精准的跟踪数据来源和关键信息的修正。
四、如何设计、研发实现数据工厂系统?
好了,各位看官,照惯例接下了是对业务如何实现的解析内容。
那么我们如何设计实现这套数据工厂系统呢?
我们之前已经提了线索库管理系统,那么现在要做的数据工厂系统也是架设在线索库底层之上的一个应用系统,对于这个应用系统来说的话,它所有的数据都直接对接调用线索库的内容,数据来源自然是线索库,它自身无需存储业务数据,但是它对线索库有比较高的操作权限,需要能对线索库的数据进行高效的增删改查操作,特别是批量去重操作。
那么这里我们还是利用5W2H1E的分析法,来设计这整套数据工厂系统:
1)What:【数据工厂系统】的目的是帮助使用者去清洗线索数据,尽最大的努力实现把废旧线索去重、更新、修复、优化,以尽可能帮忙下游营销、销售同学去跟踪、转化商机。
2)Where:【数据工厂系统】底层依赖于线索库管理系统,是跟线索库紧密关联的业务执行系统,从用户体验性角度出发来说,它比较简单、单一,因为它明确的只做一件事,就是数据清洗加工,然后为了这个目的,在它当前系统底座的基础上,它还需要埋伏(埋点)到各个前端业务系统的方方面面里去。
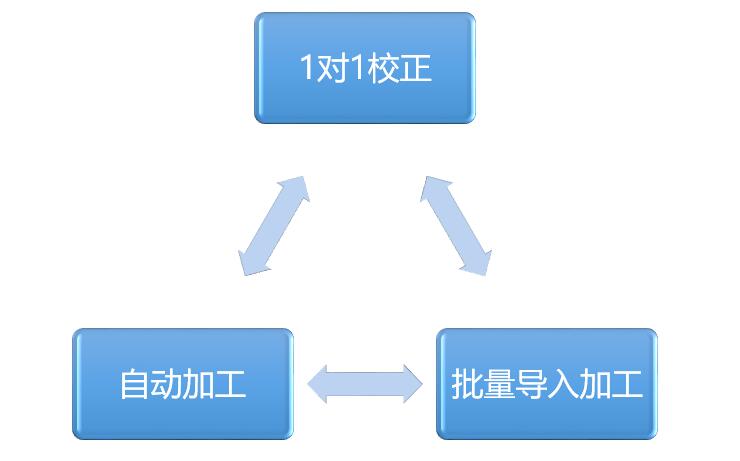
3)When:【数据工厂系统】自动清洗一般是在用户触发指定行为、动作时使用,手动清洗则是在数据加工者在获得一批最新信息时批处理操作使用,或者1对1的进行单条数据加工使用。
4)Why:那么用户为什么要用【数据工厂系统】呢?因为当我们的线索放久了,随着各个企业、用户最新情况的变化(比如离职、调岗、购房买车、结婚生子等),我们就需要及时调用数据工厂系统这把磨刀石来对数据进行磨刀了。
5)上游-Who:上游用户是谁?是管理【数据工厂系统】的市场、营销的数据加工专员,他们的目的明确、单一,就是要确保线索数据的及时性和正确性,为下游销售员工争取在最宝贵的时间窗口期内提供尽可能充分准确的弹药信息。
6)上游-How:上游用户如何执行数据加工呢?这里一般分为1对1加工、批量加工和自动加工规则管理,只要系统做的足够完善合理,那基本上绝大部分可以自动清洗修复更新数据,人工加工只是辅助补充。
7)上游-How Much:需要加工到什么程度呢?一般我们做数据清洗,都一定会强调获取关键数据,比如姓名、手机、邮箱、微信、地址、职务,最早的甚至会有QQ等,当然这个已经跟不上时代潮流了,最新的甚至可以考虑抖音号、快手号等,触达用户的手段信息往往是第一位,其次才是其它可供后续用户画像、丰富展开的附加信息。
8)下游-Who:下游用户自然是我们的销售、直面用户的营销小伙伴了,一份好的线索清单,能让销售能轻松高效的联系、跟踪客户,转化订单,对销售来说,它是1,没有它后面再多的0都无意义。
9)下游-How:联系、触达方式都给到销售、营销小伙伴了,如何高效的进行转化呢?那我们需要销售伙伴一是足够厚脸皮,二是打仗要有章法,要考虑清楚什么是客户最需要的,而他们需要做的,依然是把【提示】做好,做到位,让客户知道我们能解决他们的什么痛点,争取做到雪中送炭,就可以了。
10)下游-How much:那么我们的数据加工能达到怎样的程度呢?首先是联系方式,至少要有一种准确可触达客户的方式,然后再不断的收集该线索的周边准确【原生】资讯,并及时准确的维护回线索里,且需要有通知机制,在线索数据更新时需要第一时间自动通知下游销售伙伴。
好了,最后补充个技术层面的说明:数据加工系统不保存任何数据,数据依然在线索库,其中加工的历史记录是永远不许删除的数据且至少应该有个备份,因为你不知道哪一天你会遭遇【数灾】,服务器挂掉、准离职员工搞破坏、总之就是各种天灾人祸,并且应该有非常便利的还原机制。
那么,以上就是【数据工程系统】的主要内容,感谢大家的“品尝”!
PS:那么让我们期待下一篇,我们将会讲解【用户画像系统】,这里抛个思考题给大家:
【用户画像系统】中的自动打标,也会对各个前端系统的埋点有强依赖关系,那么它跟【数据工厂系统】的清洗埋点有什么区别呢?
欢迎大家思考并踊跃评论讨论,下一篇笔者会把自己的理解细细道来。
以上有任何不合理或错误之处,欢迎指出,谢谢。下一篇什么时候?可能很快,也可能很慢,希望大家能积极评论 ,也算给笔者点写下去的动力,谢谢。
本文作者 @Ian Huang 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
