策略产品经理:通俗易懂了解机器学习原理(下篇)
今天我们继续讲完剩下的几个算法原理与应用场景。
一、基本的机器学习算法
1. 支持向量机算法(Support Vector Machine,SVM)
1)支持向量机入门了解
支持向量机可以算是机器学习当中比较难的部分了,一般很多学习机器学习的同学学到这个部分都会选择“狗带放弃”,但是我们还是要坚持去通俗易懂的理解,尽量帮助大家深入浅出。
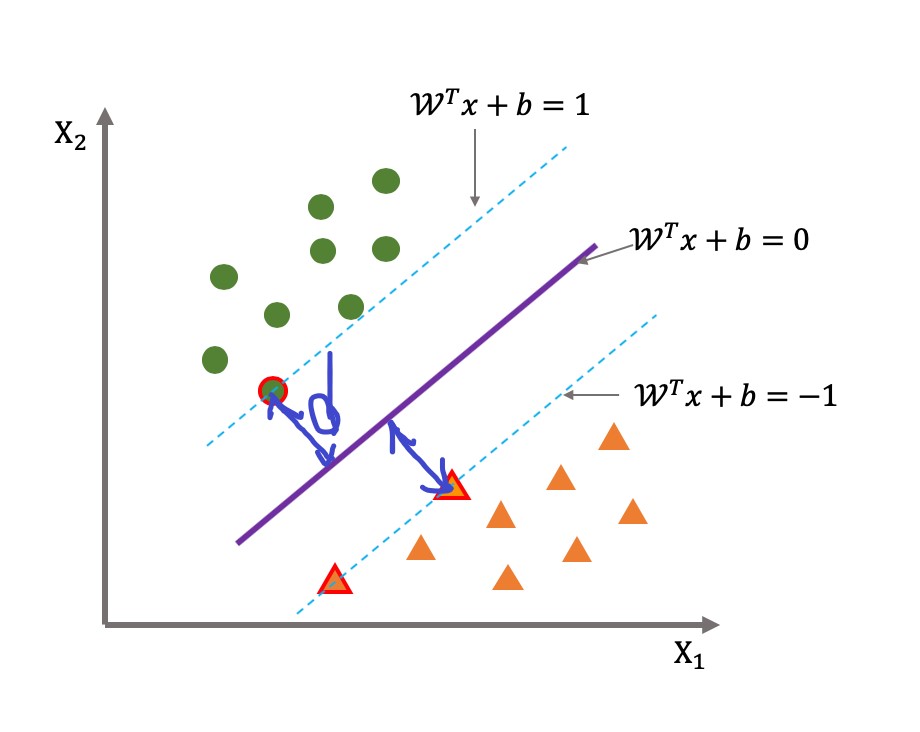
SVM一般用于解决二分类问题(也可以解决多分类和回归问题,目前主要的应用场景就是图像分类、文本分类以及面部识别等场景),归根结底就是一句话最大化离平面最近的点到到平面之间的距离,这个其实就叫支持向量;类似图中的直线,对两边的点形成的超平面(绿色虚线与红色虚线)能够最大。
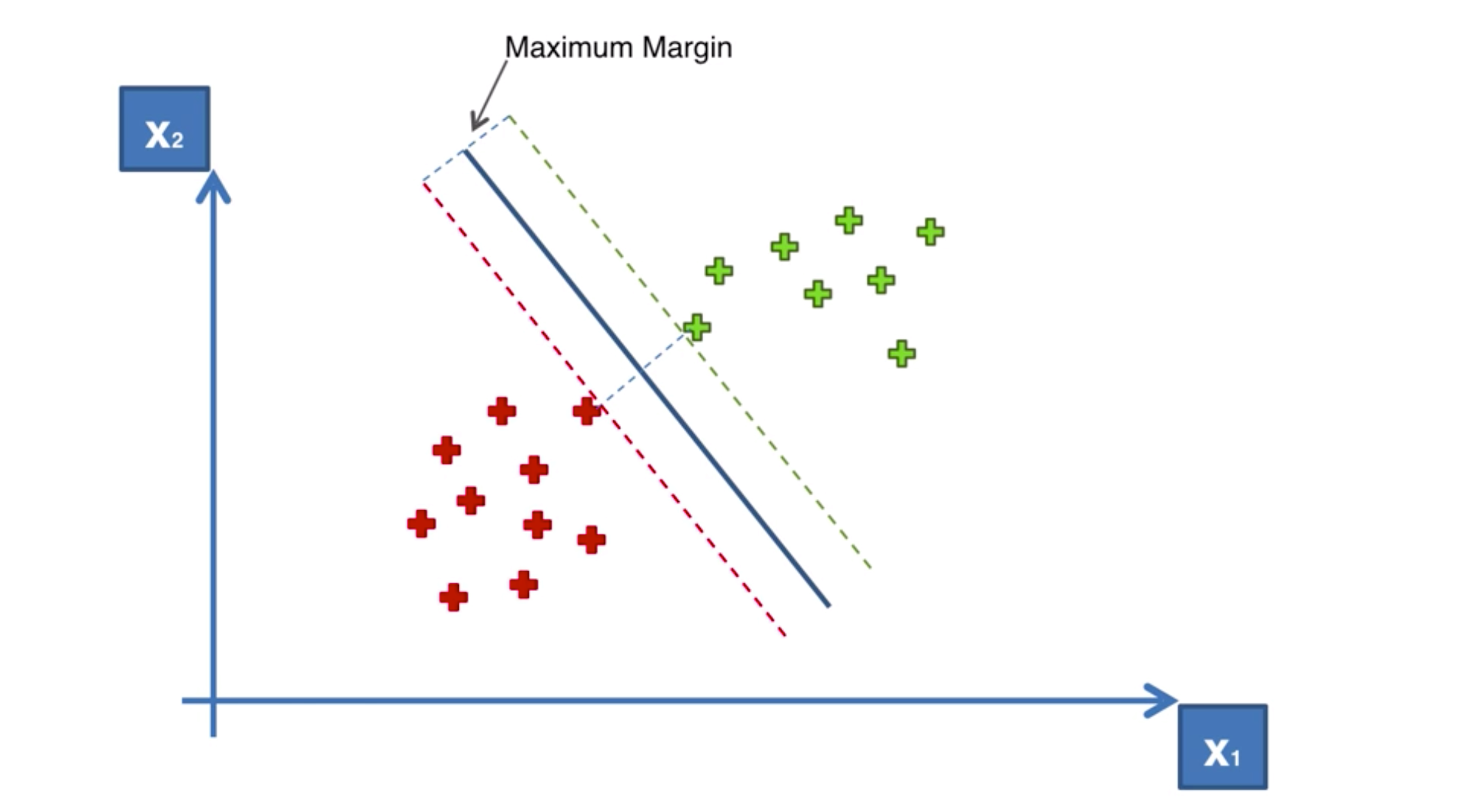
2)线性分类器定义
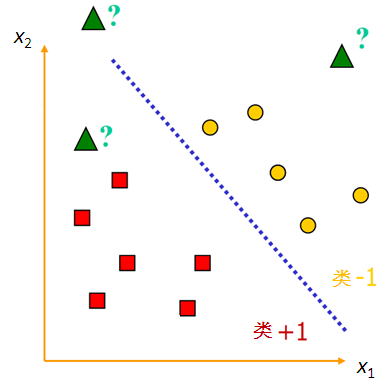
在机器学习的上篇中讲到线性回归为一元线性回归,一元也就是一个自变量加上一个因变量,这种在二维坐标轴可以表示成(x,y);假设有两类要用来区分的样本点,一类用黄色的“●”,另一类用红色的“□”,中间这条直线就是用来讲两类样本完全分开的分类函数,用数学化的方式描述图片就是:
样本数据:11个样本,2个输入 (x1,x2) ,一个输出y。
第i个样本的输入: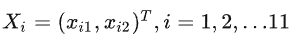
输出y:用1(红色方形□)和-1(黄色圆点●)作为标签。
训练样本集合: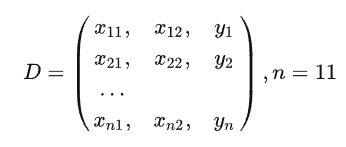
训练的核心目标:以训练的样本为研究的对象,找到一条直线能够将两类样本能够有效分开,一个线性函数能够把样本进行分开的话,我们就称之为样本的线性可分性:
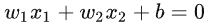
当样本点位(x1,x2,y)的时候,找到上述这条直线进行平面样本点分割,其中区域 y = 1(图中的类+1)的点用下述公式表达:
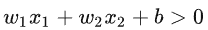
那么y = -1类的点表达式就是:
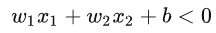
上述就是线性可分的明确定义,由此类推用更高维度的超平面可以通过增加x维度来表达,我们认为这种表达方式会比较的麻烦会用矩阵表达式来进行代替:

一般简写为,方便理解:

大家要厘清一个概念,在公式当中X不是代表横坐标,而是样本的向量表达式,假如上图最下方的红框坐标是(5,1),那么这个对应的列向量表达式如下所示;其中WT 代表是一个行向量,就是我们所说的位置参数,X是一组列向量,是已经知道的样本数据,Wi表示的就是Xi的系数,行向量和列向量相乘就得到了1*1的矩阵,也就是一个实数了:
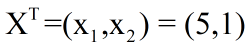
3)如何找到合适的参数构建线性分类器
机器学习就是找到通过学习的算法找到最合适超参Wi,支持向量机有两个目标:第一个是使间隔最大化,第二个是使样本正确分类;
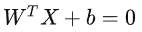
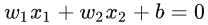
我们都学过欧式距离公式,二维空间当中的点位(x,y)到 对应直线的距离可以表示为,

用这个逻辑推演扩展到n维度空间之后,n维度的向量表示为:
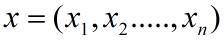
即n维度列向量到直线公式的距离可以表示为:
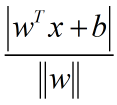
其中:
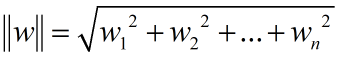
根据下图可以指导,支持向量到超平面的距离就是d,其他点到超平面的距离就会大于d;
所以按照欧式距离原理,我们就可以得到下列式子:
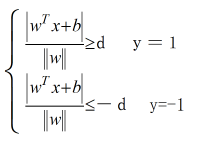
公式两边同时除以d,并且我们令||w||d = 1(方便公式推导,对目标函数本身无影响),可以得到下列式:
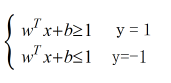
并且我们对方程进行合并可以得到式:
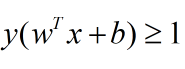
我们就得到了最大间隔下的两个超平面,分别为过绿色原点的平面和过黄色三角的平面,我们来最大化这个距离就可以得到:
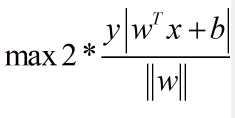
我们令y(wTx+b ) = 1,最后可以得到:
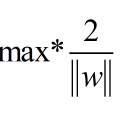
再做一个分子与分母之间转化可以得到:
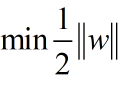
为了简化问题,再把w里面的根号去除一下,所以我们最终优化问题可以得到要求解决的w:
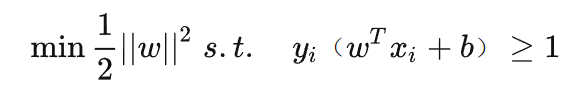
策略产品了解支持向量机SVM到这个阶段已经差不多了,后面详细的求解w涉及到对偶问题的求解拉格朗日乘数法和强对偶问题求硬间隔,当分类点位存在交织的时候还需要设定软间隔(放宽对于样本的要求,允许少量的样本分类错误),已经属于偏算法数学解题范畴了,感兴趣同学可以深度了解与推导一下。
4)支持向量机的优缺点
优点:
- 理论基础完善,相比较于神经网络可解释性更强;
- 求解是全局最优而不是局部最优;
- 同时适用于线性问题和非线性问题(核函数)两种;
- 高纬度样本空间同样也能用SVM支持向量机;
缺点:
SVM不太适合超大的数据集类型。
2. 朴素贝叶斯算法-Naive Bayes
朴素贝叶斯是基于贝叶斯定理和条件独立性假设的分类方法,属于生成模型(工业界多用于垃圾邮件分类、信用评估以及钓鱼网站监测等场景),核心思想就是学习输入输出的联合概率模型P(X,Y),然后使用条件概率公式求得P(Y | X )-表示在X发生的条件下,Y事件发生的概率。Arthur先带大家回顾一下大学数学概率论的基础知识,便于大家能够快速理解。
1)概率论基础必备知识
其中条件概率公式如下所示:
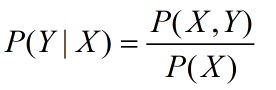
P(X,Y)表示的是Y和X同时发生的概率;
- 如果X和Y是相互独立事件的话P(X,Y)=P(X)*P(Y)
- 如果X和Y不相互独立那么P(X,Y) = P(Y | X )*P(X)= P(X | Y )*P(Y)。
两遍同时除以一个P(X),就得到了我我们的主角贝叶斯公式:
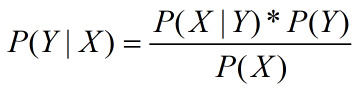
2)朴素贝叶斯的学习和分类
我知道了贝叶斯公式之后,怎么用其原理来做分类呢,跟随Arthur按照下面的思路一起推演:
假设:训练集 T={(x1,y1),…,(xn,yn)},通过P(Y = k), k = 1,2,…,k 算出 P(Y)。
在朴素贝叶斯中我们把条件概率分布做独立性假设,解耦特征与特征之间的关系,每个特征都视为单独的条件假设:
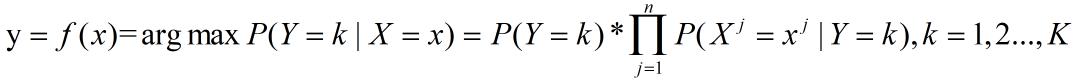
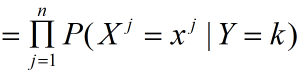
n代表的特征个数,根据后验概率带入贝叶斯定理可以得到:
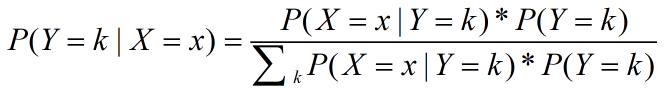
再把特征条件独立性带入到公式当中得到以下的式子,就得到了决策分类器:
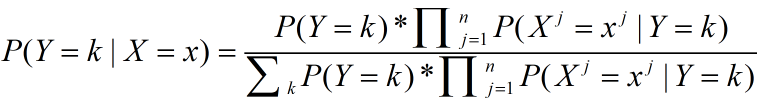
可以看出,X的归类方式是由x属于哪一个类别的概率最大来决定的,决策函数改写成为:
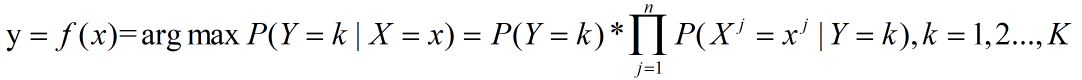
我们来举个通俗易懂的栗子吧,不然大家看着一堆公式也不太好理解,假如小明过往出门的依照以下的规则分布:
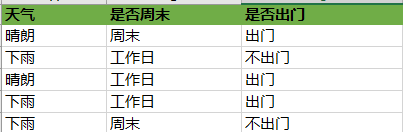
现在有一天(x1=晴朗,x2=工作日),求小明这一天是否出门?
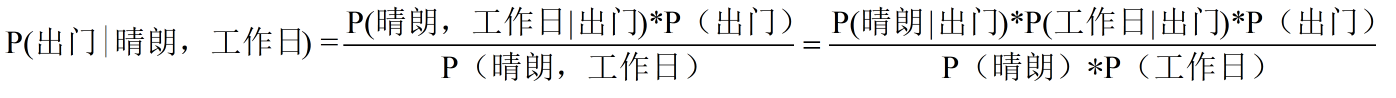
=(2/5*2/5*3/5)/(3/5*3/5)=0.267,同理我们得到P(不出门|晴朗,工作日)=0.4
P(不出门|晴朗,工作日)> P(出门|晴朗,工作日),因此我们判定小明这一天多半是不出门的;
3)朴素贝叶斯校准与属性值处理
① 拉普拉斯校准
p(x) 为0的时候,也就是某个特征下,样本数量为0。则会导致y = 0;所以x需要引入Laplace校准,在所有类别样本计数的时候加1,这样可以避免有个式子P(X)为0带来最终的y = 0。
② 属性特征处理
以上都是介绍的特征离散值可以直接进行样本数量统计,统计概率值;如果是连续值,可以通过高斯分布的方式计算概率。
4)朴素贝叶斯的优缺点
优点:
- 坚实的数学基础,适合对分类任务,有稳定分类效率;
- 结果易解释,算法比较简单,常常用于文本分类;
- 小规模数据表现好,能处理分类任务,适合实时新增的样本训练。
缺点:
- 需要先验概率输入;
- 对输入的数据表达形式敏感,分类决策也存在错误率;
- 假设了样本独立性的先决条件,如果样本之间存在一定关联就会明显分类干扰。
二、策略产品必知机器学习系列干货总结
给策略产品、运营讲机器学习系列到这里就结束了,该系列的文章目的是在为转型策略产品,或者是已经从事策略产品、策略运营方向的同学通俗易懂的了解机器学习算法原理与思想。
很多文科同学/运营会觉得看着策略公式就头大,其实怎么去推导不是我介绍这篇文章的目的,理解核心的思想与应用场景,如何和业务贴近服务才是关键,我们毕竟不是算法,需要间隔两者工作职责和范围边界。
希望这个系列真正能做到普及策略产品经理的工作,更深入浅出的普及到关于机器学习的知识。
本文作者 @策略产品Arthur
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
