10款国产大模型大战弱智吧——中文理解能力测评
自从2022年11月ChatGPT的问世掀起了互联网的一场浪潮,中国的互联网巨头、科技企业乃至众多创业公司,纷纷投身这场技术竞赛,力图在中文AI领域迎头赶上。特别是最近,商汤科技推出的商量大模型5.0版本,据媒体报道,其在中文处理能力上不仅赶上了GPT-4,甚至有所超越。此模型一出,便使公司股价翻倍,同时也激起了笔者浓厚的探索兴趣。
本文笔者试图从一个侧面回答一个问题:近一年半的时间,国产大模型的发展究竟如何?
为了深入了解,笔者自掏腰包,购买了GPT-4和文心一言4.0,并将这两款模型与其他9款国内领先的大模型一起,用于解答“弱智吧”上的经典问题。本文将从中文理解和处理的角度,探讨国内大模型的进展与成就。
让我们一起看看,这些“智能大模型”在理解和回应中文内容方面,能达到怎样的高度。(文末附完整评测结果)
一、测试说明
为了探索中文大模型的理解能力,笔者从“弱智吧”精选了10道经典问题。虽名“弱智吧”,但这里藏龙卧虎,其内容并非普通意义上的“弱智”,反而是充满了智慧的表达。这个平台的帖子通常包含了大量的脑筋急转弯和双关语,这些都是测试逻辑推理和语义理解的绝佳材料。
更重要的是,帖子的表达方式简洁明了,信息干净且高质,使其成为研究中文语料的宝贵资源。
近期,一篇专注于中文语料质量的论文《COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning》进一步验证了“弱智吧”数据的价值。研究团队构建的数据集采用了各种被认为是高质量的数据源,如问答社区、维基、考试以及现有的自然语言处理(NLP)数据集,其中也包括了“弱智吧”。使用这些数据集对大语言模型进行微调,并通过BELLE-EVAL标准利用GPT-4进行评估,结果表明,“弱智吧”在这些高质量数据源中的表现尤为突出,其效果远超其他网络媒体如知乎。
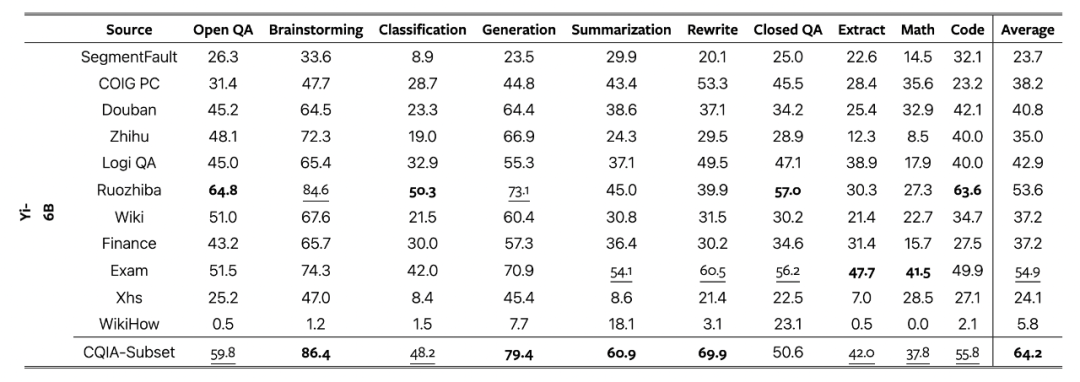
基于以上分析,选择“弱智吧”的题目来测试大模型的中文理解能力显然是一个明智的决定。这不仅可以验证模型在处理复杂逻辑和语言游戏方面的能力,同时也能深入了解其在理解高质量中文内容方面的表现。
更多细节,可以直接查看论文:https://arxiv.org/abs/2403.18058
参评大模型
评测基准:
GPT-4
国产大模型:
1.商量5.0(商汤):https://chat.sensetime.com
2.文心一言4.0(百度):https://yiyan.baidu.com
3.讯飞星火(讯飞):https://xinghuo.xfyun.cn
4.豆包(字节):https://www.doubao.com
5.百川(百川):https://www.baichuan-ai.com
6.通义千问(阿里):https://tongyi.aliyun.com
7.混元(腾讯):https://hunyuan.tencent.com/bot/chat
8.kimi(月之暗面):https://kimi.moonshot.cn
9.智谱清言(智谱):https://chatglm.cn
10.跃问(阶跃星辰):https://stepchat.cn
测试目标
从“弱智吧”选取10道充满内涵的题目,这些题目要求对中文语言乃至文化有深入理解,才能洞察其表层之下的深层含义。
模型需识别句中关键词汇,并准确解释这些词语的出处、表面意义以及深层内涵。此外,模型还需要结合整个句子的内容,阐述为何该句子具有幽默感。
这不仅是对模型中文理解和幽默感捕捉能力的考验,也是一次全面的挑战,难度极高。
测试题目
1、“丢死人了!”王老汉一边喊着一边把尸体扔下了楼
2、在发现我没有道德后对方放弃了道德绑架
3、烽火连三月,褒姒笑成了一个憨批
4、王老汉愤怒地打开水龙头,因为开水龙头烫着他了
5、“小屁孩,这是什么法术法力这么高?“呵呵,这是未成年人保护法
6、去掉一个最高温,去掉一个最低温,今天的天气预报播送完了
7、死有什么好怕的,死之前还没有死,死之后就没法怕
8、没有一片雪花是无辜的,王老汉指着没信号的电视说到
9、算命的说我22岁之后要多少钱就有多少钱,现在我身上有15元8角,因为今天我只要到这么多
10、为了让自己文雅一些,拉面改名叫方便面
评分标准
满分10分。所有模型只提问一次,对模型的回答进行评分。
- 理解错误,得0分。
- 主要意思理解正确,但存在瑕疵,得0.5分。
- 理解正确,得1分。
测评结果
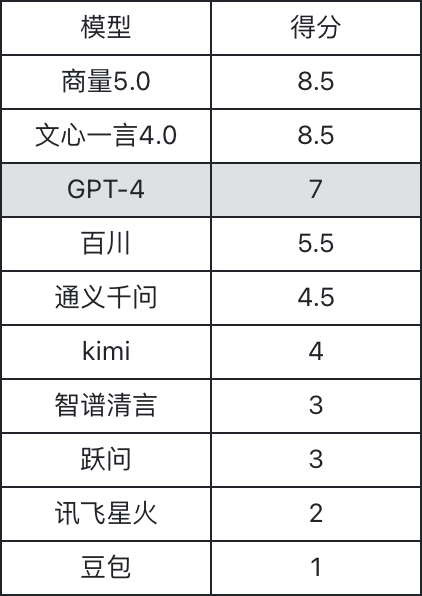
从本次的评估结果来看,商量5.0和文心一言4.0的性能表现出色,均在评分中获得了8.5分,超越了超越了GPT-4的7分,遥遥领先于其他中文模型。
其中文心一言4.0值得一提,因其所有问题都基本能回答正确,是唯一在最具挑战性的第10题上给出了正确答案,但由于3道题目的回答存在小瑕疵,总分被扣除了1.5分。
其中文心一言全部回答正确,尤其是最后一道最难的题,是唯一答对的一个模型。因3道题回答有瑕疵而被扣除1.5分。
商量5.0虽然在最后一题答错,且有一题回答不够完美,但与文心一言4.0同样取得了8.5分的最高成绩。这两款模型的表现不仅显示了它们在中文理解和处理上的强大能力,也反映了当前国产大模型技术的进步。
在价格和可用性方面,目前文心一言4.0要支付59.9元会员费,才能使用一个月。而商量5.0目前可以免费使用,目前正是白嫖的好时机。
其他一些国产大模型,如豆包和混元大模型,其表现相对较弱,特别是在理解“弱智吧”这类特定语境的题目上显得力不从心,在中文处理的深度和精度上仍需进一步提升。顺便八卦一下,看来业内传闻字节和腾讯训练大模型进展不顺利,也并非空穴来风。
评测结论
就中文理解能力来说,以文心一言4.0和商量5.0为代表的优秀国产中文大模型显示出了与GPT-4相匹敌乃至超越的能力,这标志着中国在自然语言处理技术领域的快速发展。尽管国产大模型的表现参差不齐,一些模型在处理复杂语境和幽默理解方面仍显不足,但这也反映出AI技术发展的正常现象。
总体来说,我们有理由对国内大模型的未来发展持乐观态度。
二、评测详情
在接下来的部分,我们将详细介绍每道题目的评测过程,以及一些有趣的回答案例。如果你对具体的评测细节感兴趣,推荐仔细阅读接下来的内容。
对于那些更希望直接查看所有模型的具体回答的读者,可以选择跳转到文末的链接,查看详细的对比表格。
1. “丢死人了!”王老汉一边喊着一边把尸体扔下了楼
题目解析
在这个例子中,“丢死人了”这一短语的双关含义是题目的核心。通常,“丢死人了”被理解为“非常丢人”,用以形容极其尴尬或令人羞愧的情况。然而,在这个笑话里,这句话被字面地解释为“把死人丢下去”。
通过设置这样的语境,当王老汉将“丢死人了”用在其字面意义上时,就形成了与听者预期的严重偏差,从而引发笑点。这种预期与实际的反差是幽默产生的关键,而大模型能否准确捕捉并理解这种双关语,是测试其语言理解能力的一大挑战。
对于大模型来说,正确处理这类含有多层意义的表达需要不仅仅是文字的直接解析能力,更需要对文化背景和语言习惯的深入理解。这样的题目不仅考验了模型的语义处理能力,还考验了它对人类幽默感的捕捉和再现能力。
GPT-4
正确(1分)
国产模型表现
正确/不完全答对/错误:7/0/3
答对模型:商量5.0、文心一言4.0、讯飞星火、百川、通义千问、kimi、智谱清言
不完全答对模型:无
答错模型:豆包、混元、跃问
答案举例
测试之前,笔者对这些模型的表现持怀疑态度。因为弱智吧的内容因其复杂的双关语和文化细节,很多人理解起来都要花费一番功夫,那么对大模型来说更是一大挑战。
当看到有些大模型不仅能识别出“非常丢人”这一表面含义,而且能够深入解释为什么会产生幽默效果时,笔者确实被深深震撼到了。比如商量5.0的回答:

其回答的准确性、清晰性、逻辑严谨性与GPT-4相比也难分伯仲。

而有些国产大模型,表现则不佳。比如跃问在解释“丢死人了”的常用意思时就出现了纰漏;豆包、混元虽然理解了表面意思,但是解释这个句子好笑的原因时则完全在乱说。这种情况揭示了当前大模型技术中的一些不均衡发展现象。虽然某些模型在识别语言的表面结构方面取得了进步,但在深层次的语义理解和文化感知方面,仍然存在显著差距。



鉴于大模型出色的表现,后文我直接让模型代替解释题目的意思。表现不佳的模型也不再举例,避免影响其口碑。
2. 在发现我没有道德后对方放弃了道德绑架烽
题目解析
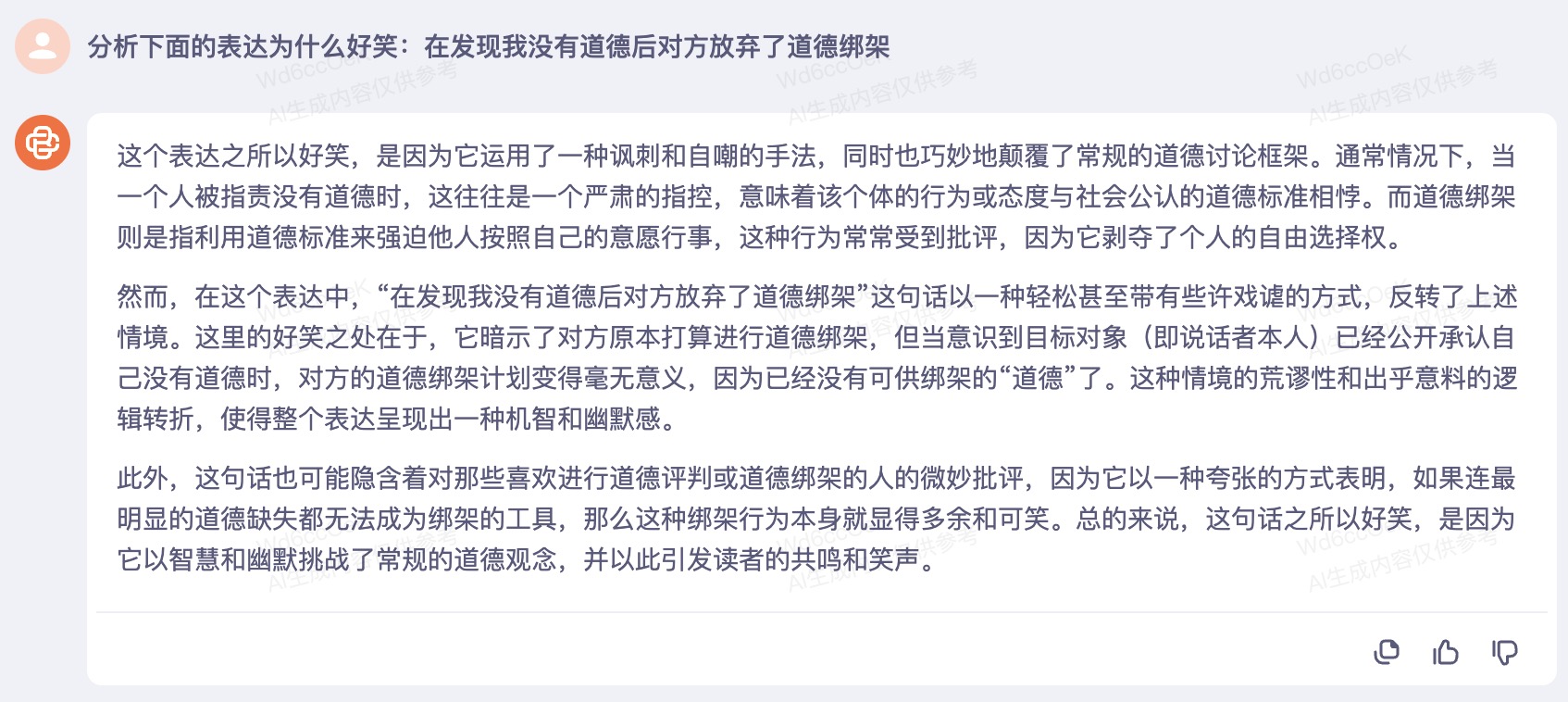
GPT-4
正确(1分)
国产模型表现
正确/不完全答对/错误:5/2/3
答对模型:商量5.0、文心一言4.0、百川、智谱清言、跃问
不完全答对模型:通义千问、kimi
答错模型:讯飞星火、豆包、混元
3. 火连三月,褒姒笑成了一个憨批
题目解析

GPT-4
不完全答对(0.5分)
国产模型表现
正确/不完全答对/错误:2/1/7
答对模型:商量5.0、文心一言4.0
不完全答对模型:百川
答错模型:讯飞星火、豆包、通义千问、混元、kimi、智谱清言、跃问
4. 王老汉愤怒地打开水龙头,因为开水龙头烫着他了
题目解析

GPT-4
正确(1分)
国产模型表现
正确/不完全答对/错误:1/1/8
答对模型:商量5.0
不完全答对模型:文心一言4.0
答错模型:讯飞星火、豆包、百川、通义千问、混元、kimi、智谱清言、跃问
5. “小屁孩,这是什么法术法力这么高?“呵呵,这是未成年人保护法
题目解析

GPT-4
正确(1分)
国产模型表现
正确/不完全答对/错误:3/2/5
答对模型:商量5.0、文心一言4.0、通义千问
不完全答对模型:混元、kimi
答错模型:讯飞星火、豆包、百川、智谱清言、跃问
6. 去掉一个最高温,去掉一个最低温,今天的天气预报播送完了
题目解析

GPT-4
错误(0分)
国产模型表现
正确/不完全答对/错误:4/0/6
答对模型:商量5.0、文心一言4.0、百川、跃问
不完全答对模型:无
答错模型:讯飞星火、豆包、通义千问、混元、kimi、智谱清言
7. 死有什么好怕的,死之前还没有死,死之后就没法怕
题目解析

GPT-4
正确(1分)
国产模型表现
正确/不完全答对/错误:8/1/1
答对模型:商量5.0、讯飞星火、豆包、百川、通义千问、kimi、智谱清言、跃问
不完全答对模型:文心一言4.0、
答错模型:混元
8. 没有一片雪花是无辜的,王老汉指着没信号的电视说到
题目解析

GPT-4
正确(1分)
国产模型表现
正确/不完全答对/错误:4/1/5
答对模型:商量5.0、文心一言4.0、百川、kimi
不完全答对模型:通义千问
答错模型:讯飞星火、豆包、混元、智谱清言、跃问
9. 算命的说我22岁之后要多少钱就有多少钱,现在我身上有15元8角,因为今天我只要到这么多
题目解析

GPT-4
不完全答对(0.5分)
国产模型表现
正确/不完全答对/错误:0/3/7
(注:本题没有模型完全答对,主要还是对答基本正确的商量5.0、文心一言4.0、通义千问这3个模型,没有挖掘出讲话者成为了乞丐的这一关键笑点。)
答对模型:无
不完全答对模型:商量5.0、文心一言4.0、通义千问
答错模型:讯飞星火、豆包、百川、混元、kimi、智谱清言、跃问
10. 为了让自己文雅一些,拉面改名叫方便面
题目解析
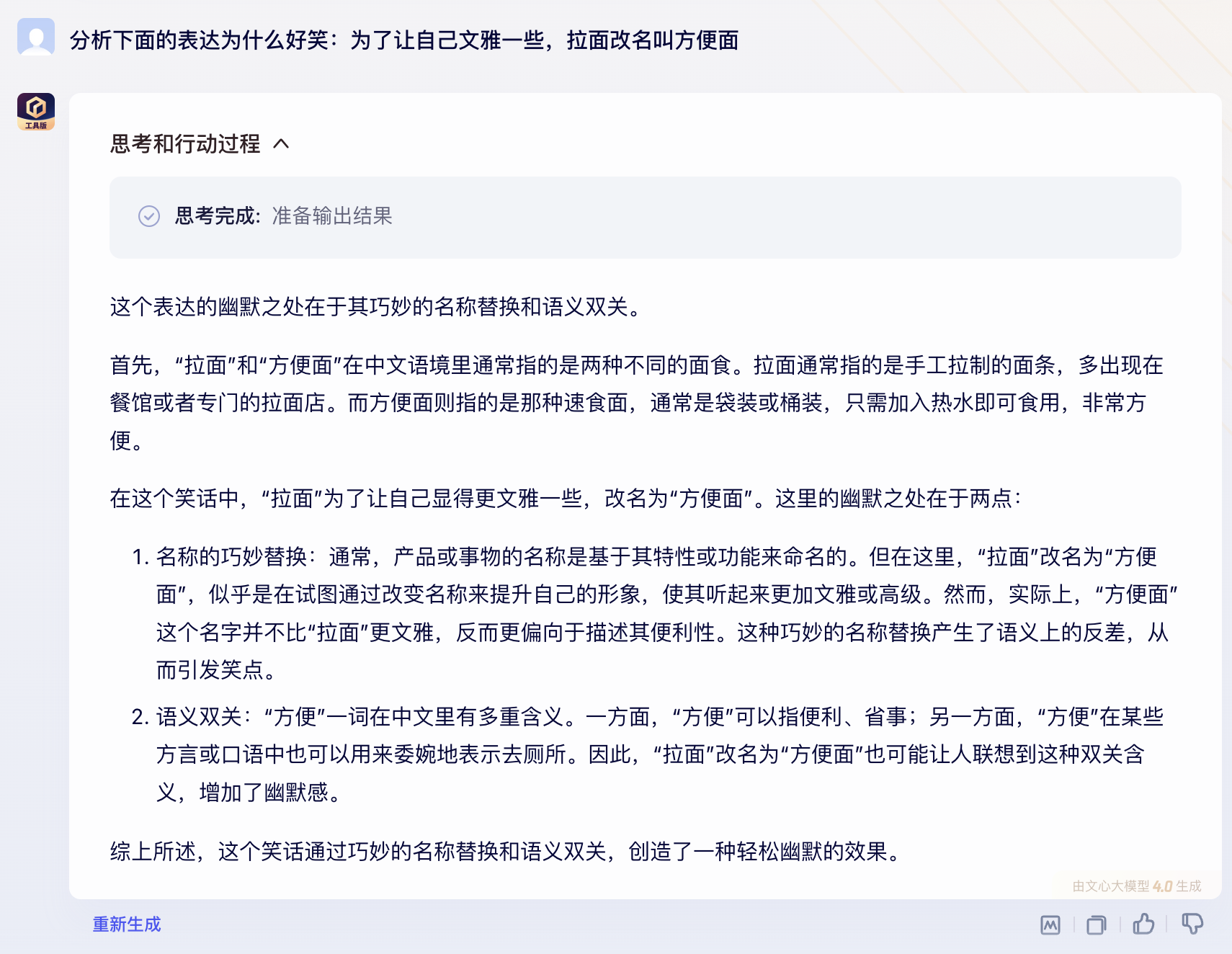
GPT-4
错误(0分)
国产模型表现
正确/不完全答对/错误:1/0/9
(注:方便面和拉面、方便和拉,这两组语义对照关系太难挖掘了,因此只有坐拥弱智吧的
文心一言4.0回答正确)
答对模型:文心一言4.0
不完全答对模型:无
答错模型:
商量5.0、讯飞星火、豆包、
百川、通义千问、混元、
kimi、智谱清言、跃问
笔者自掏腰包测评不易,各位朋友要点赞、转发、收藏哟~
三、原始数据
https://qvylhiay5s3.feishu.cn/sheets/Rxhqs7Jb9h95jbtwjQzcQjsNnhh?from=from_copylink
如果你有想问模型的问题,欢迎在第二个表格中提问,笔者会挑选有意思的问题,帮助大家提问GPT-4、文心一言4.0等模型。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
